
- 1xilinxFPGA-SPI协议详解(基于verilog)_xilinx spi 文档
- 2MySQL的配置方法以及数据库配置常见错误及其解决方法_数据库中没有表配置数据怎么办
- 3数据库_MySQL: mysql数据类型的用法介绍_mysql数据类型与使用
- 4Pulling is not possible because you have unmerged files. hint: Fix them up in the work tree
- 5第一篇博客------自我介绍_如何介绍自己的博客
- 6字符串匹配(BF,KMP,BM)_int match(const char*p
- 7如何理解python包的离线安装?_gitpython 离线安装
- 82017年度人工智能事件大盘点
- 9MySQL【部署 03】8.0.25离线部署(下载+安装+配置)Failed dependencies 问题处理及8.0配置参数说明_numactl离线安装
- 10数据库系统概论(第五版)创建Student、Course、SC表的步骤_数据库中有三张表,分别为student,course,sc
Huggingface 的 generate 方法介绍:top_p sampling/top_k sampling/greedy_search/beam_search 等_huggingface llama model generate
赞
踩
Blog Information
- Blog name: How to generate text: using different decoding methods for language generation with Transformers
- Blog URL: https://huggingface.co/blog/how-to-generate
- 内容介绍:自回归语言模型解码方法介绍,也即 Hugginface 库中的 generate 方法介绍
Introduction
近年来,由于在数百万个网页数据上训练的大型基于 Transformer 的语言模型的兴起,开放式语言生成引起了越来越多的关注,其中包括OpenAI著名的GPT2模型。在条件开放式语言生成方面,取得了令人瞩目的成果。除了改进的 Transformer 架构和大规模无监督训练数据外,更好的解码方法也起到了重要作用。
本文简要介绍了不同的解码策略,并展示了如何使用 huggingface 的 transformers 库来轻松实现它们!
本文介绍的所有功能都能用于自回归语言生成。简而言之,自回归语言生成是基于这样的假设,即一个词序列的概率分布可以分解为下一个词条件概率分布的乘积:
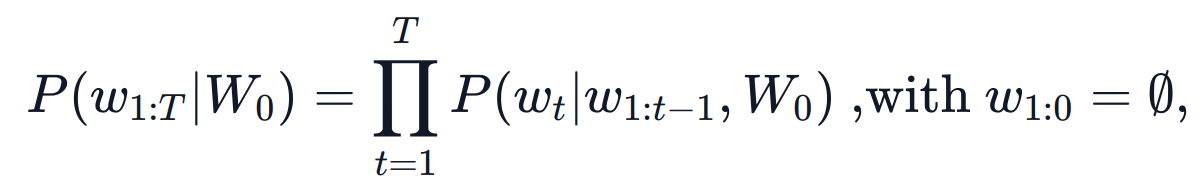
其中 W0 是初始上下文词序列;单词序列的长度 T 通常是生成时即时 (on-the-fly) 确定的,即当某个时刻 t 出现了 EOS token 则可以停止单词序列生成。
- 本文将重点介绍目前最主流的解码方法:
- greedy search
- beam search
- top-k sampling
- top-p sampling
环境配置
- transformers 库安装
!pip install -q git+https://github.com/huggingface/transformers.git
!pip install -q tensorflow==2.1
- 1
- 2
- 导入 gpt2 模型
import tensorflow as tf
from transformers import TFGPT2LMHeadModel, GPT2Tokenizer
tokenizer = GPT2Tokenizer.from_pretrained("gpt2")
# add the EOS token as PAD token to avoid warnings
model = TFGPT2LMHeadModel.from_pretrained("gpt2", pad_token_id=tokenizer.eos_token_id)
- 1
- 2
- 3
- 4
- 5
Greedy Search
-
Greedy search 每次都选择概率最大的词作为单词序列中的下一个词
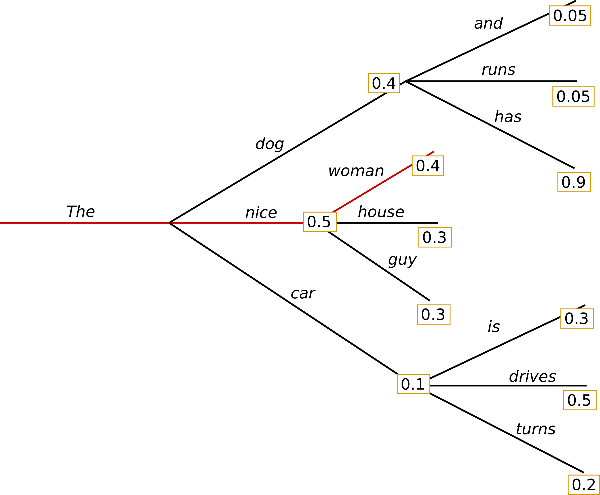
从 “The” 这个词开始,每一步都选择概率最大的单词,分别选择了 “nice” 和 “woman”,最后这样选择的整体概率为 0.5 × 0.4 = 0.2 0.5 \times 0.4=0.2 0.5×0.4=0.2 -
接下来,我们将使用GPT2在上下文(“I”, “enjoy”, “walking”, “with”, “my”, “cute”, “dog”)上生成单词序列(“I”,“enjoy”,“walking”,“with”,“my”,“cute”,“dog”)。让我们看看在transformers中如何使用贪婪搜索:
# encode context the generation is conditioned on
input_ids = tokenizer.encode('I enjoy walking with my cute dog', return_tensors='tf')
# generate text until the output length (which includes the context length) reaches 50
greedy_output = model.generate(input_ids, max_length=50)
print("Output:\n" + 100 * '-')
print(tokenizer.decode(greedy_output[0], skip_special_tokens=True))
# Output:
# ----------------------------------------------------------------------------------------------------
# I enjoy walking with my cute dog, but I'm not sure if I'll ever be able to walk with my dog. I'm not sure if I'll ever be able to walk with my dog.
# I'm not sure if I'll
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
太好了!我们使用GPT2生成了我们的第一个短文本声明:本文内容由网友自发贡献,转载请注明出处:【wpsshop博客】
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

