- 1反反爬虫之--爬取大众点评--店铺名称、详址、经纬度、评价人数、平均消费等信息_怎么爬大众点评的店铺信息
- 2初学构建小项目之仓库管理系统数据库及表的创建及登录页面的实现(一)_addcomponent(passwordtxt, grouplayout.preferred_si
- 3python-提取特征 & 特征选择_python 脑电信号特征提取
- 4Python请求示例获取抖音视频详情数据,抖音商品详情数据_抖音获取视频信息
- 57大最常用ChatGPT Excel最佳使用示例(最后附微软官方Excel-ChatGPT插件使用方法)——手把手从0开始教您如何在Excel中使用ChatGPT,附详细指南及教程_chatgpt for excel
- 6基于Python爬虫广西柳州餐厅餐馆数据可视化系统设计与实现(Django框架) 研究背景与意义、国内外研究现状
- 7语音交互的三驾马车:ASR、NLP、TTS_asrnlp全称英文
- 8使用LSTM进行情感分析_lstm 情感分析 影响准确率的因素
- 9[AIDV] 芯片验证:AI 机器学习在 DV 中的应用及进展_dv验证芯片
- 10spring cloud config server端接收到远程仓库端消息之后,无法将消息传递到config client端的问题_discoveryclient - registration status: 204
Pytorch Transformer
赞
踩
Pytorch Transformer
0. 环境介绍
小技巧:当遇到函数看不懂的时候可以按 Shift+Tab 查看函数详解。
1. Transformer
1.1 架构
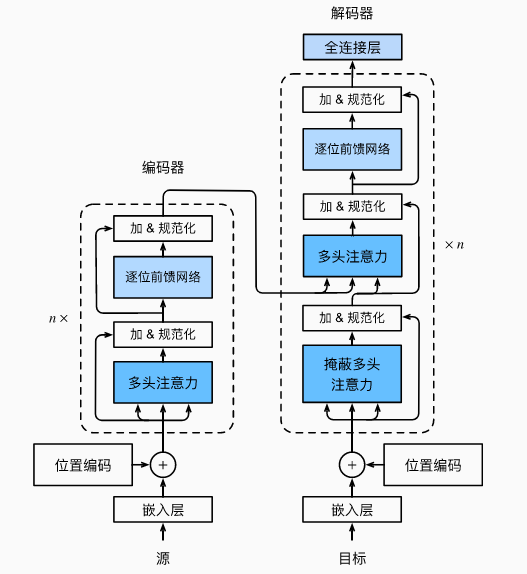
- 基于Encoder-Decoder 架构来处理序列对
- 跟使用注意力的 seq2seq 不同,Transformer 是纯基于注意力
1.2 多头注意力
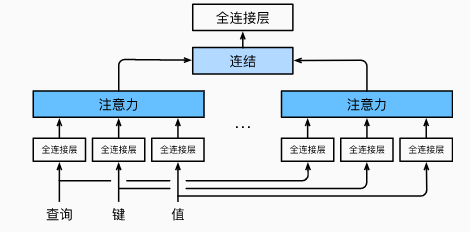
- 对同一 Key,Value,Query,希望抽取不同的信息
- 例如短距离关系和长距离关系
- 多头注意力使用
h
h
h 个独立的注意力 Pooling
- 合并各个头(head)输出得到最终输出
数学语言表达:
- 给定 Query q ∈ R d q \mathbf{q} \in \mathbb{R}^{d_q} q∈Rdq,Key k ∈ R d k \mathbf{k} \in \mathbb{R}^{d_k} k∈Rdk,Value v ∈ R d v \mathbf{v} \in \mathbb{R}^{d_v} v∈Rdv
- 头 i i i 的可学习参数: W i ( q ) ∈ R p q × d q \mathbf W_i^{(q)}\in\mathbb R^{p_q\times d_q} Wi(q)∈Rpq×dq, W i ( k ) ∈ R p k × d k \mathbf W_i^{(k)}\in\mathbb R^{p_k\times d_k} Wi(k)∈Rpk×dk, W i ( v ) ∈ R p v × d v \mathbf W_i^{(v)}\in\mathbb R^{p_v\times d_v} Wi(v)∈Rpv×dv
- 头 i i i 的输出: h i = f ( W i ( q ) q , W i ( k ) k , W i ( v ) v ) ∈ R p v \mathbf{h}_i = f(\mathbf W_i^{(q)}\mathbf q, \mathbf W_i^{(k)}\mathbf k,\mathbf W_i^{(v)}\mathbf v) \in \mathbb R^{p_v} hi=f(Wi(q)q,Wi(k)k,Wi(v)v)∈Rpv
- 输出的可学习参数 : W o ∈ R p o × h p v \mathbf W_o\in\mathbb R^{p_o\times hp_v} Wo∈Rpo×hpv
- 多头注意力输出:
W o [ h 1 ⋮ h h ] ∈ R p o \mathbf W_o\in \mathbb{R}^{p_o} Wo⎣⎢⎡h1⋮hh⎦⎥⎤∈Rpo⎡⎣⎢⎢h1⋮hh⎤⎦⎥⎥
1.3 有掩码的多头注意力
- Decoder 对序列重一个元素输出时,不应该考虑该元素之后的元素(因为从时间序列上还没看到)
- 可以通过掩码来实现
- 也就是计算 x i \mathbf{x}_i xi 输出时,假装当前的序列长度为 i i i
1.4 基于位置的前馈网络
b b b:表示一个 batch 有多少句子, n n n:表示句子有多少个单词, d d d 表示每个单词向量的维度
- 将输入形状由 ( b , n , d ) (b, n, d) (b,n,d) 变换成 ( b n , d ) (bn, d) (bn,d)
- 作用两个全连接层
- 输出形状由 ( b n , d ) (bn, d) (bn,d) 变化回 ( b , n , d ) (b, n, d) (b,n,d)
- 等价于两层核窗口为 1 1 1 的一维卷积层
1.5 层归一化(LayerNorm)
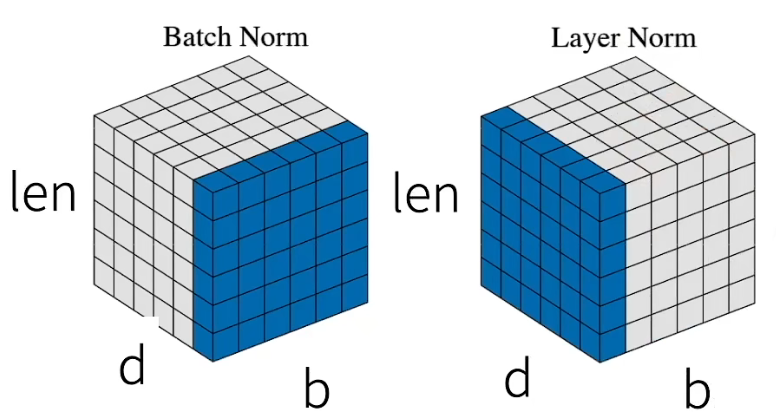
- 批量归一化(BatchNorm)对每个特征/通道里元素进行归一化
- 不适合序列长度会变的 NLP 应用(每个句子的长度不一样,不能用 BN)
- 层归一化(LayerNorm)对每个样本里的元素进行归一化
1.6 信息传递
- Encoder 中的输出 y 1 , . . . , y n \mathbf{y}_1,...,\mathbf{y}_n y1,...,yn
- 将其作为第
i
i
i 个 Transformer 块中多头注意力的 Key 和 Value
- 它的 Query 来自目标序列
- 意味着 Encoder 和 Decoder 中块的个数和输出维度都是一样的
1.7 预测
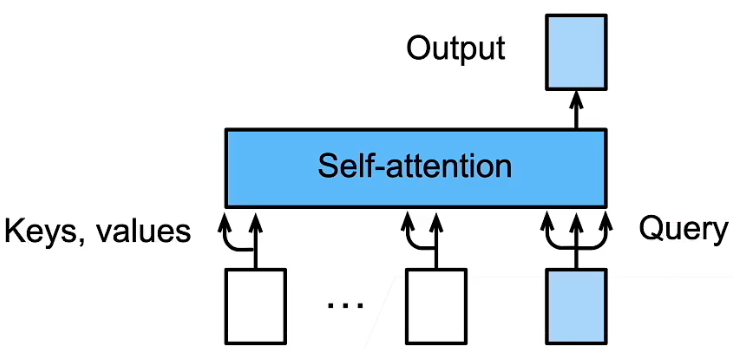
- 预测第 t + 1 t+1 t+1 个输出时
- Decoder 中输入前
t
t
t 个预测值
- 在自注意力中,前 t t t 个预测值作为 Key 和 Value,第 t t t 个预测值还作为 Query
训练时:Decoder 第一个带掩码的多头注意力的 K,V,来自本身的 Q,第二个多头注意力的 K,V 来自 Encoder
预测时:K,V 来自 Decoder 的上一时刻的输出作为 K,V
2. 代码
2.0 导包
!pip install -U d2l
import math
import pandas as pd
import torch
from torch import nn
from d2l import torch as d2l
- 1
- 2
- 3
- 4
- 5
- 6
2.1 多头注意力
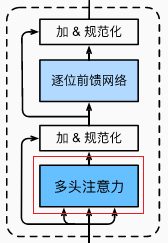
class MultiHeadAttention(nn.Module): """多头注意力""" def __init__(self, key_size, query_size, value_size, num_hiddens, num_heads, dropout, bias=False, **kwargs): super(MultiHeadAttention, self).__init__(**kwargs) self.num_heads = num_heads self.attention = d2l.DotProductAttention(dropout) self.W_q = nn.Linear(query_size, num_hiddens, bias=bias) self.W_k = nn.Linear(key_size, num_hiddens, bias=bias) self.W_v = nn.Linear(value_size, num_hiddens, bias=bias) self.W_o = nn.Linear(num_hiddens, num_hiddens, bias=bias) def forward(self, queries, keys, values, valid_lens): # queries,keys,values的形状: # (batch_size,查询或者“键-值”对的个数,num_hiddens) # valid_lens 的形状: # (batch_size,)或(batch_size,查询的个数) # 经过变换后,输出的queries,keys,values 的形状: # (batch_size*num_heads,查询或者“键-值”对的个数, # num_hiddens/num_heads) queries = transpose_qkv(self.W_q(queries), self.num_heads) keys = transpose_qkv(self.W_k(keys), self.num_heads) values = transpose_qkv(self.W_v(values), self.num_heads) if valid_lens is not None: # 在轴0,将第一项(标量或者矢量)复制num_heads次, # 然后如此复制第二项,然后诸如此类。 valid_lens = torch.repeat_interleave( valid_lens, repeats=self.num_heads, dim=0) # output的形状:(batch_size*num_heads,查询的个数, # num_hiddens/num_heads) output = self.attention(queries, keys, values, valid_lens) # output_concat的形状:(batch_size,查询的个数,num_hiddens) output_concat = transpose_output(output, self.num_heads) return self.W_o(output_concat)

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
使多个头并行(为了省去循环操作,所以使用大量的维度变换,节省效率):
def transpose_qkv(X, num_heads): """为了多注意力头的并行计算而变换形状""" # 输入X的形状:(batch_size,查询或者“键-值”对的个数,num_hiddens) # 输出X的形状:(batch_size,查询或者“键-值”对的个数,num_heads, # num_hiddens/num_heads) X = X.reshape(X.shape[0], X.shape[1], num_heads, -1) # 输出X的形状:(batch_size,num_heads,查询或者“键-值”对的个数, # num_hiddens/num_heads) X = X.permute(0, 2, 1, 3) # 最终输出的形状:(batch_size*num_heads,查询或者“键-值”对的个数, # num_hiddens/num_heads) return X.reshape(-1, X.shape[2], X.shape[3]) def transpose_output(X, num_heads): """逆转transpose_qkv函数的操作""" X = X.reshape(-1, num_heads, X.shape[1], X.shape[2]) X = X.permute(0, 2, 1, 3) return X.reshape(X.shape[0], X.shape[1], -1)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
测试:
num_hiddens, num_heads = 100, 5
attention = MultiHeadAttention(num_hiddens, num_hiddens, num_hiddens,
num_hiddens, num_heads, 0.5)
attention.eval()
- 1
- 2
- 3
- 4
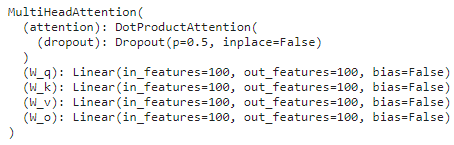
batch_size, num_queries = 2, 4
num_kvpairs, valid_lens = 6, torch.tensor([3, 2])
# X 维度(2, 4, 100)
X = torch.ones((batch_size, num_queries, num_hiddens))
# Y 维度(2, 6, 100)
Y = torch.ones((batch_size, num_kvpairs, num_hiddens))
attention(X, Y, Y, valid_lens).shape
- 1
- 2
- 3
- 4
- 5
- 6
- 7
2.2 基于位置的前馈网络
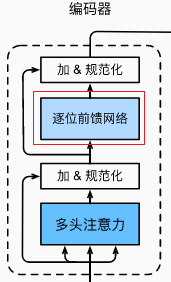
实际上就是 MLP:
class PositionWiseFFN(nn.Module):
"""基于位置的前馈网络"""
def __init__(self, ffn_num_input, ffn_num_hiddens, ffn_num_outputs,
**kwargs):
super(PositionWiseFFN, self).__init__(**kwargs)
self.dense1 = nn.Linear(ffn_num_input, ffn_num_hiddens)
self.relu = nn.ReLU()
self.dense2 = nn.Linear(ffn_num_hiddens, ffn_num_outputs)
def forward(self, X):
return self.dense2(self.relu(self.dense1(X)))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
测试:
ffn = PositionWiseFFN(4, 4, 8)
ffn.eval()
ffn(torch.ones((2, 3, 4))).shape
- 1
- 2
- 3
2.3 层归一化(LayerNorm)
对比 BN 和 LN:
ln = nn.LayerNorm(3)
bn = nn.BatchNorm1d(3)
X = torch.tensor([[1, 3, 5],
[1, 2, 3]], dtype=torch.float32)
# 在训练模式下计算X的均值和方差
print('layer norm:', ln(X), '\nbatch norm:', bn(X))
- 1
- 2
- 3
- 4
- 5
- 6

2.4 加入残差连接
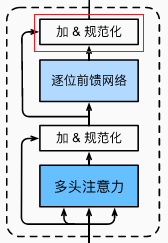
class AddNorm(nn.Module):
"""残差连接后进行层规范化"""
def __init__(self, normalized_shape, dropout, **kwargs):
super(AddNorm, self).__init__(**kwargs)
self.dropout = nn.Dropout(dropout)
self.ln = nn.LayerNorm(normalized_shape)
def forward(self, X, Y):
return self.ln(self.dropout(Y) + X)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
add_norm = AddNorm([3, 4], 0.5)
add_norm.eval()
add_norm(torch.ones((2, 3, 4)), torch.ones((2, 3, 4))).shape
- 1
- 2
- 3
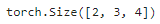
2.5 EncoderBlock
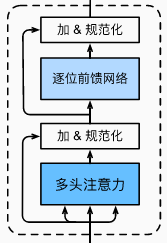
class EncoderBlock(nn.Module): """transformer编码器块""" def __init__(self, key_size, query_size, value_size, num_hiddens, norm_shape, ffn_num_input, ffn_num_hiddens, num_heads, dropout, use_bias=False, **kwargs): super(EncoderBlock, self).__init__(**kwargs) self.attention = d2l.MultiHeadAttention( key_size, query_size, value_size, num_hiddens, num_heads, dropout, use_bias) self.addnorm1 = AddNorm(norm_shape, dropout) self.ffn = PositionWiseFFN( ffn_num_input, ffn_num_hiddens, num_hiddens) self.addnorm2 = AddNorm(norm_shape, dropout) def forward(self, X, valid_lens): Y = self.addnorm1(X, self.attention(X, X, X, valid_lens)) return self.addnorm2(Y, self.ffn(Y))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
Transformer 编码器中的任何层都不会改变其输入的形状:
X = torch.ones((2, 100, 24))
valid_lens = torch.tensor([3, 2])
encoder_blk = EncoderBlock(24, 24, 24, 24, [100, 24], 24, 48, 8, 0.5)
encoder_blk.eval()
encoder_blk(X, valid_lens).shape
- 1
- 2
- 3
- 4
- 5
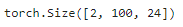
2.6 TransformerEncoder
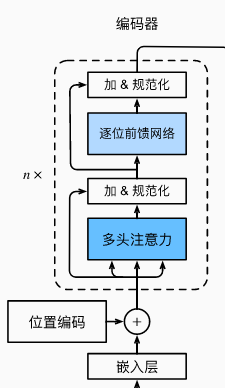
class TransformerEncoder(d2l.Encoder): """transformer编码器""" def __init__(self, vocab_size, key_size, query_size, value_size, num_hiddens, norm_shape, ffn_num_input, ffn_num_hiddens, num_heads, num_layers, dropout, use_bias=False, **kwargs): super(TransformerEncoder, self).__init__(**kwargs) self.num_hiddens = num_hiddens self.embedding = nn.Embedding(vocab_size, num_hiddens) self.pos_encoding = d2l.PositionalEncoding(num_hiddens, dropout) self.blks = nn.Sequential() for i in range(num_layers): self.blks.add_module("block"+str(i), EncoderBlock(key_size, query_size, value_size, num_hiddens, norm_shape, ffn_num_input, ffn_num_hiddens, num_heads, dropout, use_bias)) def forward(self, X, valid_lens, *args): # 因为位置编码值在-1和1之间, # 因此嵌入值乘以嵌入维度的平方根进行缩放, # 然后再与位置编码相加。 X = self.pos_encoding(self.embedding(X) * math.sqrt(self.num_hiddens)) self.attention_weights = [None] * len(self.blks) for i, blk in enumerate(self.blks): X = blk(X, valid_lens) self.attention_weights[i] = blk.attention.attention.attention_weights return X
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
创建一个两层的 Transformer 编码器:
encoder = TransformerEncoder(
200, 24, 24, 24, 24, [100, 24], 24, 48, 8, 2, 0.5)
encoder.eval()
encoder(torch.ones((2, 100), dtype=torch.long), valid_lens).shape
- 1
- 2
- 3
- 4
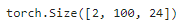
2.7 DecoderBlock
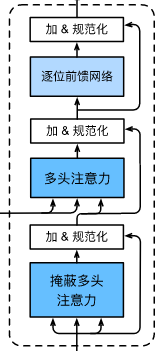
class DecoderBlock(nn.Module): """解码器中第i个块""" def __init__(self, key_size, query_size, value_size, num_hiddens, norm_shape, ffn_num_input, ffn_num_hiddens, num_heads, dropout, i, **kwargs): super(DecoderBlock, self).__init__(**kwargs) self.i = i self.attention1 = d2l.MultiHeadAttention( key_size, query_size, value_size, num_hiddens, num_heads, dropout) self.addnorm1 = AddNorm(norm_shape, dropout) self.attention2 = d2l.MultiHeadAttention( key_size, query_size, value_size, num_hiddens, num_heads, dropout) self.addnorm2 = AddNorm(norm_shape, dropout) self.ffn = PositionWiseFFN(ffn_num_input, ffn_num_hiddens, num_hiddens) self.addnorm3 = AddNorm(norm_shape, dropout) def forward(self, X, state): enc_outputs, enc_valid_lens = state[0], state[1] # 训练阶段,输出序列的所有词元都在同一时间处理, # 因此state[2][self.i]初始化为None。 # 预测阶段,输出序列是通过词元一个接着一个解码的, # 因此state[2][self.i]包含着直到当前时间步第i个块解码的输出表示 if state[2][self.i] is None: key_values = X else: key_values = torch.cat((state[2][self.i], X), axis=1) state[2][self.i] = key_values if self.training: batch_size, num_steps, _ = X.shape # dec_valid_lens的开头:(batch_size,num_steps), # 其中每一行是[1,2,...,num_steps] dec_valid_lens = torch.arange( 1, num_steps + 1, device=X.device).repeat(batch_size, 1) else: dec_valid_lens = None # 自注意力 X2 = self.attention1(X, key_values, key_values, dec_valid_lens) Y = self.addnorm1(X, X2) # 编码器-解码器注意力。 # enc_outputs的开头:(batch_size,num_steps,num_hiddens) Y2 = self.attention2(Y, enc_outputs, enc_outputs, enc_valid_lens) Z = self.addnorm2(Y, Y2) return self.addnorm3(Z, self.ffn(Z)), state
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
decoder_blk = DecoderBlock(24, 24, 24, 24, [100, 24], 24, 48, 8, 0.5, 0)
decoder_blk.eval()
X = torch.ones((2, 100, 24))
state = [encoder_blk(X, valid_lens), valid_lens, [None]]
decoder_blk(X, state)[0].shape
- 1
- 2
- 3
- 4
- 5
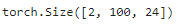
2.8 TransformerDecoder
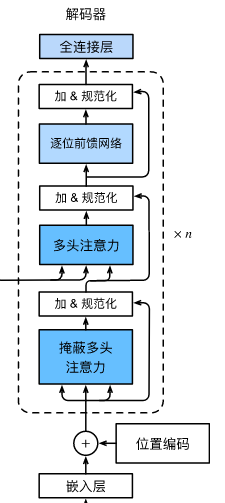
class TransformerDecoder(d2l.AttentionDecoder): def __init__(self, vocab_size, key_size, query_size, value_size, num_hiddens, norm_shape, ffn_num_input, ffn_num_hiddens, num_heads, num_layers, dropout, **kwargs): super(TransformerDecoder, self).__init__(**kwargs) self.num_hiddens = num_hiddens self.num_layers = num_layers self.embedding = nn.Embedding(vocab_size, num_hiddens) self.pos_encoding = d2l.PositionalEncoding(num_hiddens, dropout) self.blks = nn.Sequential() for i in range(num_layers): self.blks.add_module("block"+str(i), DecoderBlock(key_size, query_size, value_size, num_hiddens, norm_shape, ffn_num_input, ffn_num_hiddens, num_heads, dropout, i)) self.dense = nn.Linear(num_hiddens, vocab_size) def init_state(self, enc_outputs, enc_valid_lens, *args): return [enc_outputs, enc_valid_lens, [None] * self.num_layers] def forward(self, X, state): X = self.pos_encoding(self.embedding(X) * math.sqrt(self.num_hiddens)) self._attention_weights = [[None] * len(self.blks) for _ in range (2)] for i, blk in enumerate(self.blks): X, state = blk(X, state) # 解码器自注意力权重 self._attention_weights[0][i] = blk.attention1.attention.attention_weights # “编码器-解码器”自注意力权重 self._attention_weights[1][i] = blk.attention2.attention.attention_weights return self.dense(X), state @property def attention_weights(self): return self._attention_weights
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
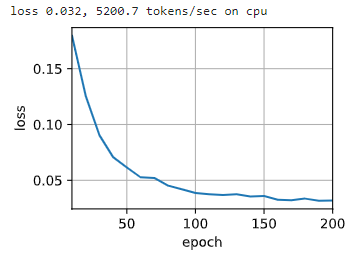
2.9 训练
Q,K,V 长度都是 32 32 32,多头注意力头数为 4 4 4,编码器和解码器个数都是 4 4 4。
num_hiddens, num_layers, dropout, batch_size, num_steps = 32, 2, 0.1, 64, 10 lr, num_epochs, device = 0.005, 200, d2l.try_gpu() ffn_num_input, ffn_num_hiddens, num_heads = 32, 64, 4 key_size, query_size, value_size = 32, 32, 32 norm_shape = [32] train_iter, src_vocab, tgt_vocab = d2l.load_data_nmt(batch_size, num_steps) encoder = TransformerEncoder( len(src_vocab), key_size, query_size, value_size, num_hiddens, norm_shape, ffn_num_input, ffn_num_hiddens, num_heads, num_layers, dropout) decoder = TransformerDecoder( len(tgt_vocab), key_size, query_size, value_size, num_hiddens, norm_shape, ffn_num_input, ffn_num_hiddens, num_heads, num_layers, dropout) net = d2l.EncoderDecoder(encoder, decoder) d2l.train_seq2seq(net, train_iter, lr, num_epochs, tgt_vocab, device)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
2.10 预测
engs = ['go .', "i lost .", 'he\'s calm .', 'i\'m home .']
fras = ['va !', 'j\'ai perdu .', 'il est calme .', 'je suis chez moi .']
for eng, fra in zip(engs, fras):
translation, dec_attention_weight_seq = d2l.predict_seq2seq(
net, eng, src_vocab, tgt_vocab, num_steps, device, True)
print(f'{eng} => {translation}, ',
f'bleu {d2l.bleu(translation, fra, k=2):.3f}')
- 1
- 2
- 3
- 4
- 5
- 6
- 7

2.11 可视化 Transformer 的注意力权重
enc_attention_weights = torch.cat(net.encoder.attention_weights, 0).reshape((num_layers, num_heads,
-1, num_steps))
enc_attention_weights.shape
- 1
- 2
- 3
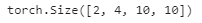
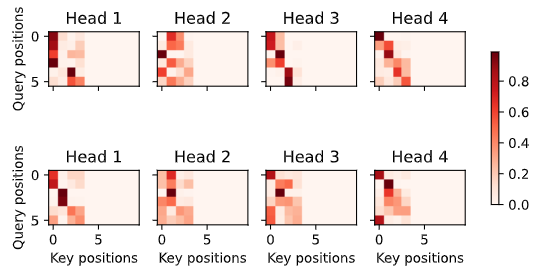
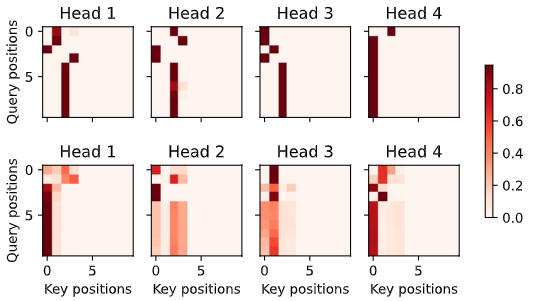
纵坐标表示 Query,横坐标表示 Key,每个点表示 Query 看到的 Key。
d2l.show_heatmaps(
enc_attention_weights.cpu(), xlabel='Key positions',
ylabel='Query positions', titles=['Head %d' % i for i in range(1, 5)],
figsize=(7, 3.5))
- 1
- 2
- 3
- 4
dec_attention_weights_2d = [head[0].tolist()
for step in dec_attention_weight_seq
for attn in step for blk in attn for head in blk]
dec_attention_weights_filled = torch.tensor(
pd.DataFrame(dec_attention_weights_2d).fillna(0.0).values)
dec_attention_weights = dec_attention_weights_filled.reshape((-1, 2, num_layers, num_heads, num_steps))
dec_self_attention_weights, dec_inter_attention_weights = \
dec_attention_weights.permute(1, 2, 3, 0, 4)
dec_self_attention_weights.shape, dec_inter_attention_weights.shape
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
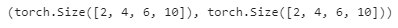
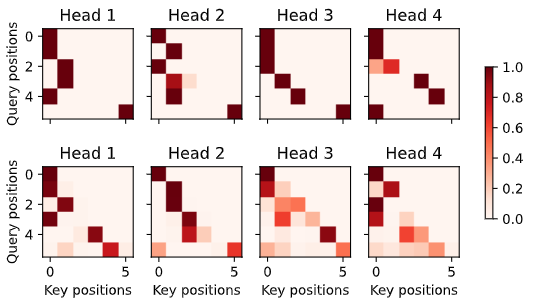
解码偏后的词会去看编码偏后的词:
# Plusonetoincludethebeginning-of-sequencetoken
d2l.show_heatmaps(
dec_self_attention_weights[:, :, :, :len(translation.split()) + 1],
xlabel='Key positions', ylabel='Query positions',
titles=['Head %d' % i for i in range(1, 5)], figsize=(7, 3.5))
- 1
- 2
- 3
- 4
- 5
与编码器的自注意力的情况类似,通过指定输入序列的有效长度,输出序列的查询不会与输入序列中填充位置的词元进行注意力计算:
d2l.show_heatmaps(
dec_inter_attention_weights, xlabel='Key positions',
ylabel='Query positions', titles=['Head %d' % i for i in range(1, 5)],
figsize=(7, 3.5))
- 1
- 2
- 3
- 4