
- 1Docker在windows下使用教程,通过Dockerfile创建镜像/容器,以YOLO系列为例_怎么在windous环境下用vscode制作vue的docker镜像
- 2MySQL高可用解决方案演进:从主从复制到InnoDB Cluster架构
- 3MVC模式
- 4推荐系统(十六)多任务学习:腾讯PLE模型(Progressive Layered Extraction model)
- 5BERT实践详解_bert_base_chinese
- 6docker基本使用_部署docker的硬件环境要求
- 7KALI--入门教程--kali下载(vm),更新国内源,更换中文界面_kali环境下载
- 8【GPT】如何拥有离线版本的GPT以及部署过程中的问题_离线部署gpt3
- 9jquery重写自定义鼠标右键弹出菜单列表_icon fa-plus
- 10linux下部署php页面
TensorBoard训练可视化(一)_tensorboard 模型训练图片可视化
赞
踩
如果本文对您有帮助,欢迎点赞支持!
目录
前言
1、TensorBoard可以做什么?
TensorBoard是谷歌推出的基于TensorFlow的一个绘图工具。TensorBoard不生产数据,它只是数据的搬运工。它的主要作用可以总结为两点:
1、可视化计算图结构。tensorflow的Graph对象本质上就是具象化的算法模型,tensorflow系统会自动维护一个默认的计算图对象,所以一般情况下我们都是直接调用这个默认的计算图对象。
2、监控变量的变化情况。TensorBoard可以记录和查看模型的训练过程数据,例如迭代过程中的损失值,准确率,过程中的图片,学习速率等中间过程数据;当然这些数据的可视化也可以由开发者自己在模型训练中记录然后使用matplotlib库图像化。
2、TensorBoard的绘制流程
TensorFlow训练算法模型时会生成Graph和训练数据,经过tf.summary.FileWriter()可以将这些数据保存到磁盘中的Events文件中去;TensorBoard读取Events文件中的数据并将它们绘制出来。
其具体流程如下:
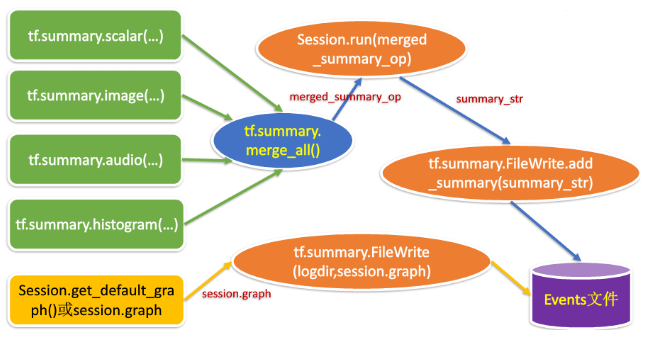
一、可视化计算图结构
首先,我们来实现第一个功能:可视化计算图结构。其基本步骤可以分为如下步骤:
1、为计算图结构添加name和name_scope
首先在定义计算图结构时为了让我们的可视化的计算图结构看起来更简介,我们要尽可能为Tensor自定义name和name_scope。下面给出一小段代码示范:
# 定义计算图的输入结构
with tf.name_scope('input'):
self.x_input = tf.placeholder(tf.float32, [None, self.n_input],name='x_input') # 数据集中的28*28的784个像素数据作为xs
self.y_input = tf.placeholder(tf.float32, [None, self.n_output],name='y_input') # 数据集中的0-9的10个标签数据作为ys
# 定义计算图的网络结构
with tf.name_scope('output'):
self.output = self._define_net(self.x_input)
# 定义计算图的损失函数
with tf.name_scope('loss'):
cross_entropy = tf.reduce_mean(-tf.reduce_sum(self.y_input * tf.log(self.output), reduction_indices=[1])) # 使用交叉熵计算损失函数
# 定义计算图的准确率
with tf.name_scope('accuracy'):
correct_prediction = tf.equal(tf.argmax(self.output, 1), tf.argmax(self.y_input, 1)) # 计算本次预测是否正确
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32)) # 将正确值转化为浮点类型,再转化为概率
# 定义计算图的优化器
with tf.name_scope('optimizer'):
self.optimizer = tf.train.GradientDescentOptimizer(self.learn_rate).minimize(cross_entropy)
2、生成graph Events文件
上述代码只是定义了我们的计算图中各个变量的命名和命名空间,想要从TensorBoard中显示效果则需要将上述graph输出生成graph Events文件:
train_writer = tf.summary.FileWriter("./logs/", sess.graph)
上述代码的意思是将sess中的graph输出到当前目录下的logs文件夹中。
输出成功后,想要在TensorBoard查看,则需要在当前安装有TensorBoard的虚拟空间中启动TensorBoard。
3、启动TensorBoard
可以在以下指令来启动TensorBoard:
tensorboard --logdir=/path/to/log-directory
注意:/path/to/log-directory指的是输出的graph Events文件所在的绝对路径,并不是真的要输入/path/to/log-directory。假如说我的Event文件目录为:D:\MRL-Mnist-Number-Master\logs
在命令行中操作时,默认目录可能是C:\Users\Lab。
首先我们输入“D:”将目录切换到D盘,然后继续输入“cd D:\MRL-Mnist-Number-Master”将默认目录切换到当前工程目录,如下图:

最后我们输入“tensorboard --logdir=logs”来启动TensorBoard
一旦 TensorBoard 开始运行,我们便可以通过在浏览器中输入localhost:6006来查看 TensorBoard。
4、TensorBoard的显示效果
最后在TensorBoard中显示的效果如下:

整个模型的整体结构看起来一目了然。
二、监控训练过程数据
在上述讲解中我们只是实现了TensorBoard中显示计算图结构,更多情况下我们还想要监控训练数据的变化。下面我们继续讲解:
1、监控张量节点变化
最常见的就是监控计算图中某个张量的变化,例如损失loss和准确率accuracy,我们只需要:
# 定义计算图的损失函数
with tf.name_scope('loss'):
cross_entropy = tf.reduce_mean(-tf.reduce_sum(self.y_input * tf.log(self.output), reduction_indices=[1])) # 使用交叉熵计算损失函数
tf.summary.scalar("loss", cross_entropy)
# 定义计算图的准确率
with tf.name_scope('accuracy'):
correct_prediction = tf.equal(tf.argmax(self.output, 1), tf.argmax(self.y_input, 1)) # 计算本次预测是否正确
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32)) # 将正确值转化为浮点类型,再转化为概率
tf.summary.scalar("accuracy", accuracy)
如上述代码,我们仅仅使用了tf.summary.scalar(a,b)来记录下该张量即可。其中参数a为生成的图的名字,b为要记录的张量(节点)。
2、监控模型变量变化
如果我们想要查看模型中某类参数的变化,例如权重或者偏执等,我们可以进行如下设置:
with tf.name_scope('weights'):
weights = tf.Variable(tf.random_normal([in_size, out_size]), name='w')
tf.summary.histogram('weights', weights)
with tf.name_scope('biases'):
biases = tf.Variable(tf.zeros([1, out_size]) + 0.1, name='b')
tf.summary.histogram('biases', biases)
或者我们可以直接通过如下代码,将所有可以训练的变量都进行记录:
for var in tf.trainable_variables():
tf.summary.histogram(var.name, var)
如上述代码,我们仅仅使用了tf.summary.histogram(a,b)来记录下该张量即可。其中参数a为生成的图的名字,b为要记录的变量。
3、定期添加到TensorBoard
上述我们只是记录了这些变量或者张量节点,此时它们的数据还没有发生变化,只有在训练时才会发生变化。
在训练时,我们要多久记录一次数据并添加到TensorBoard中呢?这个我们可以自定义,例如每训练50次记录一下。如何将数据记录下来并添加到TensorBoard中呢?前面我们定义了多种类型的数据,我们可以直接先将这些节点的记录和添加操作合并为一个操作符节点:
merged_summary_op = tf.summary.merge_all()
然后我们运行该操作符节点,然后将其结果添加到我们前面定义的train_writer中即可:
summary=sess.run(merged_summary_op,feed_dict={x:xs,y_:ys})
train_writer.add_summary(summary, i) # i 是指这是第i次训练

