
- 1SpringBoot实现登陆注册(附源码)_spring boot登录页面设计代码
- 2mitmdump的使用及踩坑记录
- 3如何保护linux服务器远程使用的安全
- 4AI对比:ChatGPT与文心一言的异同与未来
- 5XCTF:Normal_RSA[WriteUP]
- 6软件测试面试问答
- 7【Ubuntu】配置 Jetson Nano 基础环境(一)_jetson nano ubuntu pyserial配置
- 8初识C语言之——static修饰变量及函数的认知。_c语言static修饰函数
- 9nvidia driver、cuda、cudnn、nvidia-docker 安装、配置和部署(Ubuntu 18.04 LTS)_nvidia docker 版本
- 10获取微信聊天窗口的小程序入口参数_vba 微信扫码
推荐系统(十六)多任务学习:腾讯PLE模型(Progressive Layered Extraction model)
赞
踩
推荐系统(十六)多任务学习:腾讯PLE模型(Progressive Layered Extraction model)
推荐系统系列博客:
- 推荐系统(一)推荐系统整体概览
- 推荐系统(二)GBDT+LR模型
- 推荐系统(三)Factorization Machines(FM)
- 推荐系统(四)Field-aware Factorization Machines(FFM)
- 推荐系统(五)wide&deep
- 推荐系统(六)Deep & Cross Network(DCN)
- 推荐系统(七)xDeepFM模型
- 推荐系统(八)FNN模型(FM+MLP=FNN)
- 推荐系统(九)PNN模型(Product-based Neural Networks)
- 推荐系统(十)DeepFM模型
- 推荐系统(十一)阿里深度兴趣网络(一):DIN模型(Deep Interest Network)
- 推荐系统(十二)阿里深度兴趣网络(二):DIEN模型(Deep Interest Evolution Network)
- 推荐系统(十三)阿里深度兴趣网络(三):DSIN模型(Deep Session Interest Network)
- 推荐系统(十四)多任务学习:阿里ESMM(完整空间多任务模型)
- 推荐系统(十五)多任务学习:谷歌MMoE(Multi-gate Mixture-of-Experts )
PLE模型是腾讯发表在RecSys ’20上的文章,这篇paper获得了recsys’20的best paper award,也算为腾讯脱离技术贫民的大业添砖加瓦了。这篇文章号称极大的缓解了多任务学习中存在的两大顽疾:负迁移(negative transfer)现象和跷跷板(seesaw phenomenon),由此带来了相比较其他MTL模型比较大的性能提升。从论文呈现的实验结果也确实是这样的,但从模型结构上来看,更像是大力出奇迹,即性能的提升是由参数量变多而带来的(仅仅是个人看法~)。这篇paper能拿best paper,一方面是实验结果所呈现出来的比较大的性能提升,另一方面是数据分析做的很好,实验做的也很全,因此看起来工作做的很扎实,这是非常值得学习的地方。
本篇博客依然延续之前博客的大纲,会从动机、模型细节结构、代码实现来介绍PLE模型。
一、动机
说到动机,先来说说多任务学习领域中存在的两大问题:
- 负迁移(negative transfer):MTL提出来的目的是为了不同任务,尤其是数据量较少的任务可以借助transfer learning(通过共享embedding,当然你也可以不仅共享embedding,再往上共享基层全连接网络等等这些很常见的操作)。但经常事与愿违,当两个任务之间的相关性很弱(比如一个任务是判断一张图片是否是狗,另一个任务是判断是否是飞机)或者非常复杂时,往往发生负迁移,即共享了之后效果反而很差,还不如不共享。
- 跷跷板现象:还是当两个task之间相关性很弱或者很复杂时,往往出现的现象是:一个task性能的提升是通过损害另一个task的性能做到的。这种现象存在很久,PLE论文里给它起了个非常贴切的名字『跷跷板』,想象一下你小时候玩跷跷板的情形吧,胖子把瘦子跷起来。
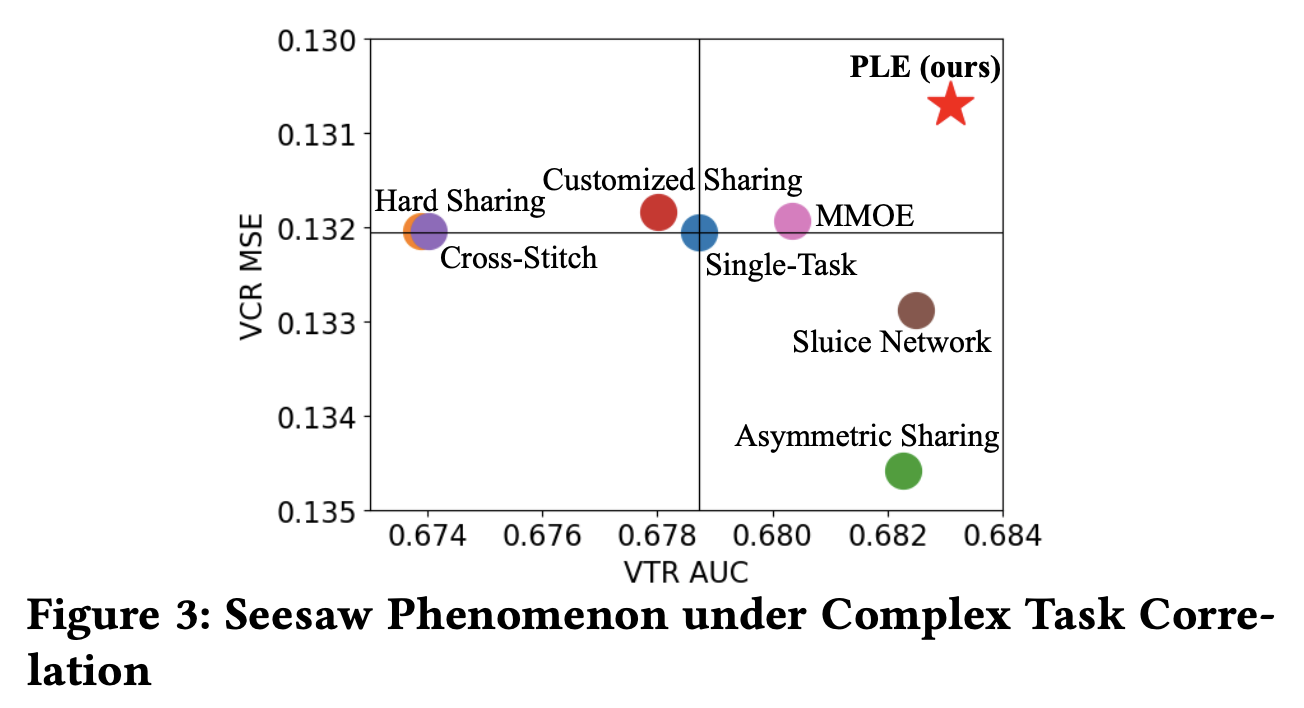
PLE这篇论文,通过大量的实验发现,当前的MTL模型跷跷板现象非常严重(从数据实验中发现问题,进而提出解决办法,会让你的motivation显得非常扎实)。如下图所示,这里的VTR(View-Through Rate)是有效观看率,其定义是用户观看某个视频超过一定时间即认为是一次有效观看,所以是个二分类任务;VCR(View Completion Ratio)是视频观看完成率,是一个回归任务。下面这个图越靠近右上角说明模型在两个task上表现都比较好,左下角则是都很差,因此明显看出,目前MTL领域中主流的模型基本上都存在跷跷板问题(至少在腾讯视频的数据场景下),表现比较好的也就是上一篇博客中介绍的谷歌的MMoE,但还是存在。
二、PLE模型细节
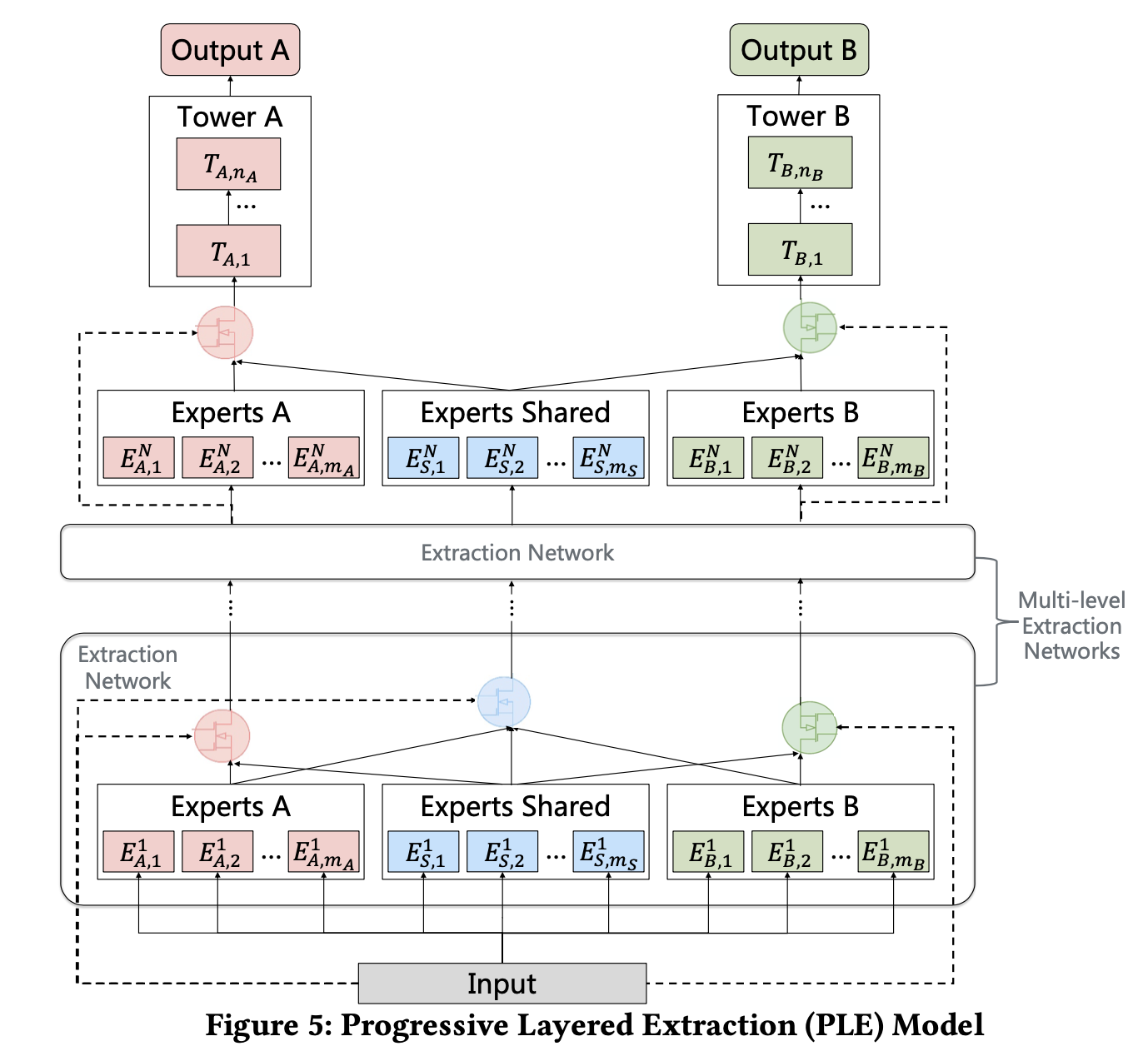
先来从整体上看看这个模型,大家自行对比下MMoE(参见我的博客推荐系统(十五)多任务学习:谷歌MMoE(Multi-gate Mixture-of-Experts )),可能就能体会到我前面说PLE性能提升更像是复杂参数所带来的这句话了,因为粗略的看,PLE做了deep化(expert完后再来一层expert),显然要比浅层的效果来得好。
我们来自底向上的拆解下PLE:
2.1、Extraction Network
PLE这里相比较MMoE做了比较大的创新,在MMoE里,不同task通过gate(网络)共享相同的expert(网络),而PLE中则把expert分为了两种:共享的expert(即上图中的experts Shared)和每个task单独的expert(task-specific experts)。因此,这种设计即保留了transfer learning(通过共享expert)能力,又能够避免有害参数的干扰(避免negative transfer)。
同样的,在gate网络部分,也分为了task-specific和Shared,以上图左边的这个gate(即上图中红色的gate)为例,它的输入有两部分,分别为Experts A和Experts Shared。而shared gate(上图中蓝颜色的gate)的输入则为三部分:Experts A、Experts Shared和Experts B。最终三部分直接作为下一层的输入,分别对应到下一层的Experts A、Experts Shared和Experts B。有一说一,图figure5如果把中间那个extraction network去掉,会更加清晰。算了,原来想偷个懒,不想画图的,我还是上个简化版的图吧。
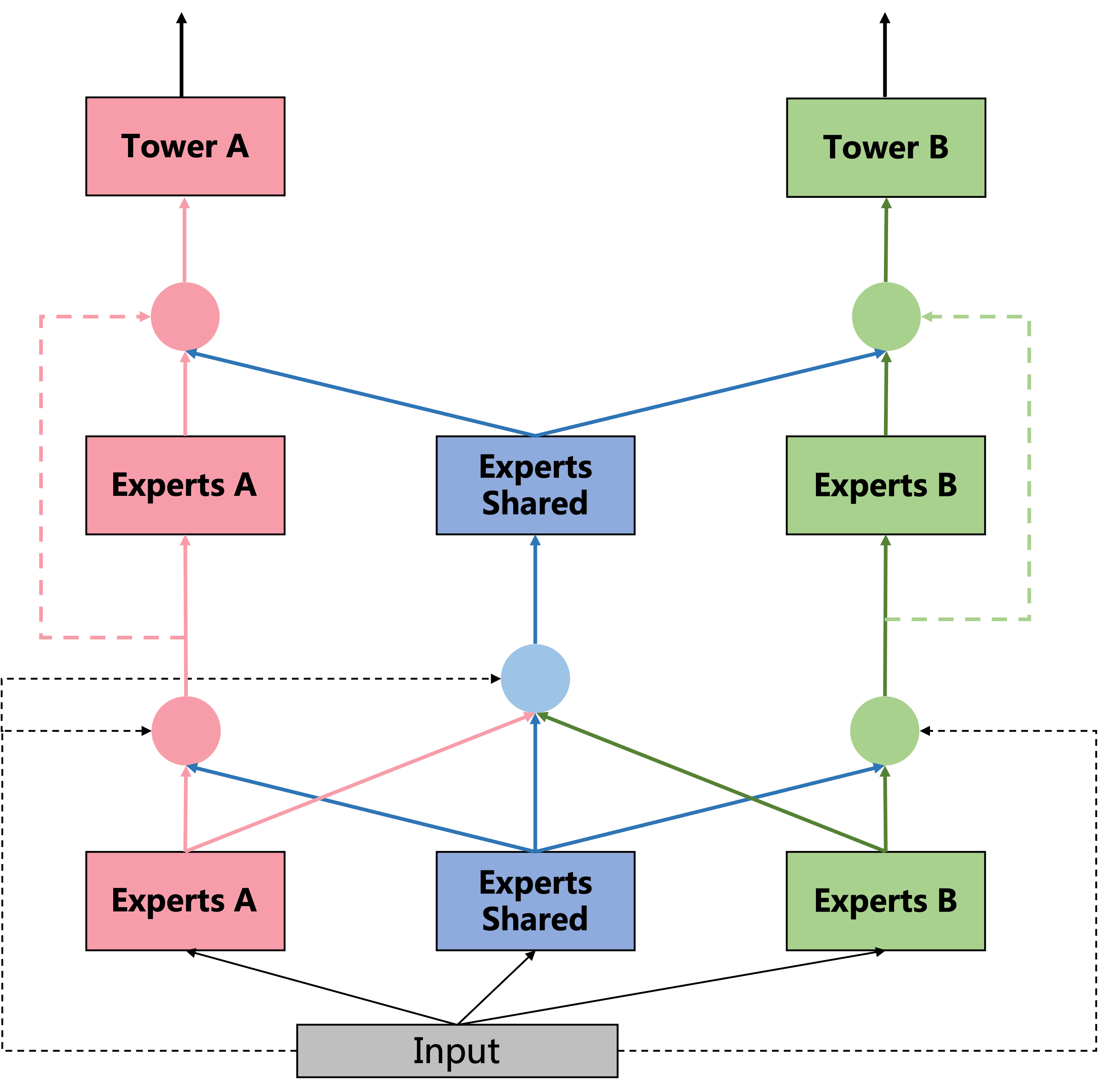
再来总结下一些细节,有助于我们代码实现。
- Gate网络的数量取决于task数量,第一层由于多了个shared gate,所以数量等于task数量+1,第二层gate网络数量与task数量相同。Gate网络最后一层全连接层的隐藏单元(即输出)size必须等于expert个数。另外,Gate网络最后的输出会经过softmax进行归一化。
- gate网络作用机制与MMoE相同,以task A为例:输出维度(假设为 ( g 1 , g 2 , g 3 , g 4 , g 5 ) (g_1, g_2, g_3, g_4, g_5) (g1,g2,g3,g4,g5))等于expert数量(3个task-specific expert,2个shared expert),意味着 g 1 g_1 g1广播作用于 e x p e r t 1 expert_1 expert1的每一个输出元素上, g 2 g_2 g2广播作用于 e x p e r t 2 expert_2 expert2的每一个输出元素上,以此类推。然后把每一个expert输出向量做element-wise add,即对应位置元素想加,最终得到第二层的expert A。 此外,第二层的Expert shared由第一层全部的expert做element-wise add得到。(建议结合上图理解)
- 每个task的expert数量以及shared expert是个超参,比如最后paddle代码里,每个task有3个expert,shared expert数量为2。实际上每个task的expert数量为3+2=5。
- 相比较MMoE,PLE除了做了一些创新后,网络结构上深度变深了,变成了2层,这也是为什么我说性能提升像是通过增加参数带来的。
- PLE第二层gate网络数量与task数量相同,第一层多了一个shared gate。
2.2、其他一些细节
- 腾讯视频rerank模块的公式为: s c o r e = P V T R W V T R × P V C R W V C R × P S H R W S H R × . . . × P C M R W C M R × f ( v i d e o _ l e n ) score={P_{VTR}}^{W_{VTR}} \times {P_{VCR}}^{W_{VCR}} \times {P_{SHR}}^{W_{SHR}} \times ... \times{P_{CMR}}^{W_{CMR}} \times f(video\_len) score=PVTRWVTR×PVCRWVCR×PSHRWSHR×...×PCMRWCMR×f(video_len),其中,VCR(View Completion Ratio)为视频观看完成率,VTR(View- Through Rate)为视频是否为有效观看,CMR(Comment Rate)为评论率,SHR(Share Rate)为分享率。 W W W为权重因子,用于调整每个指标的权重。
- 关于loss函数,每个task的loss加了个可学习的权重参数 w w w,用于模型自动学习每个task的loss的权重。
三、代码实现
老规矩,直接上paddle给出的实现代码,我这里把向量维度加了注释,方便理解。
组网代码:
import paddle import paddle.nn as nn import paddle.nn.functional as F class PLELayer(nn.Layer): def __init__(self, feature_size, task_num, exp_per_task, shared_num, expert_size, tower_size, level_number): super(PLELayer, self).__init__() """ feature_size: 499 """ self.task_num = task_num # 2 self.exp_per_task = exp_per_task # 3 self.shared_num = shared_num # 2 self.expert_size = expert_size # 16 self.tower_size = tower_size # 8 self.level_number = level_number # 2 # ple layer """ ple_layers: [SinglePLELayer( (lev_0_exp_0_0): Linear(in_features=499, out_features=16, dtype=float32, name=lev_0_exp_0_0) (lev_0_exp_0_1): Linear(in_features=499, out_features=16, dtype=float32, name=lev_0_exp_0_1) (lev_0_exp_0_2): Linear(in_features=499, out_features=16, dtype=float32, name=lev_0_exp_0_2) (lev_0_exp_1_0): Linear(in_features=499, out_features=16, dtype=float32, name=lev_0_exp_1_0) (lev_0_exp_1_1): Linear(in_features=499, out_features=16, dtype=float32, name=lev_0_exp_1_1) (lev_0_exp_1_2): Linear(in_features=499, out_features=16, dtype=float32, name=lev_0_exp_1_2) (lev_0_exp_shared_0): Linear(in_features=499, out_features=16, dtype=float32, name=lev_0_exp_shared_0) (lev_0_exp_shared_1): Linear(in_features=499, out_features=16, dtype=float32, name=lev_0_exp_shared_1) (lev_0_gate_0): Linear(in_features=499, out_features=5, dtype=float32, name=lev_0_gate_0) (lev_0_gate_1): Linear(in_features=499, out_features=5, dtype=float32, name=lev_0_gate_1) (lev_0_gate_shared_): Linear(in_features=499, out_features=8, dtype=float32, name=lev_0_gate_shared_) (_param_gate_shared): Linear(in_features=499, out_features=8, dtype=float32, name=lev_0_gate_shared_)), SinglePLELayer( (lev_1_exp_0_0): Linear(in_features=16, out_features=16, dtype=float32, name=lev_1_exp_0_0) (lev_1_exp_0_1): Linear(in_features=16, out_features=16, dtype=float32, name=lev_1_exp_0_1) (lev_1_exp_0_2): Linear(in_features=16, out_features=16, dtype=float32, name=lev_1_exp_0_2) (lev_1_exp_1_0): Linear(in_features=16, out_features=16, dtype=float32, name=lev_1_exp_1_0) (lev_1_exp_1_1): Linear(in_features=16, out_features=16, dtype=float32, name=lev_1_exp_1_1) (lev_1_exp_1_2): Linear(in_features=16, out_features=16, dtype=float32, name=lev_1_exp_1_2) (lev_1_exp_shared_0): Linear(in_features=16, out_features=16, dtype=float32, name=lev_1_exp_shared_0) (lev_1_exp_shared_1): Linear(in_features=16, out_features=16, dtype=float32, name=lev_1_exp_shared_1) (lev_1_gate_0): Linear(in_features=16, out_features=5, dtype=float32, name=lev_1_gate_0) (lev_1_gate_1): Linear(in_features=16, out_features=5, dtype=float32, name=lev_1_gate_1))] """ self.ple_layers = [] for i in range(0, self.level_number): if i == self.level_number - 1: ple_layer = self.add_sublayer( name='lev_' + str(i), sublayer=SinglePLELayer( feature_size, task_num, exp_per_task, shared_num, expert_size, 'lev_' + str(i), True)) self.ple_layers.append(ple_layer) break else: ple_layer = self.add_sublayer( name='lev_' + str(i), sublayer=SinglePLELayer( feature_size, task_num, exp_per_task, shared_num, expert_size, 'lev_' + str(i), False)) self.ple_layers.append(ple_layer) feature_size = expert_size # task tower self._param_tower = [] self._param_tower_out = [] for i in range(0, self.task_num): # [16, 8] linear = self.add_sublayer( name='tower_' + str(i), sublayer=nn.Linear( expert_size, tower_size, weight_attr=nn.initializer.Constant(value=0.1), bias_attr=nn.initializer.Constant(value=0.1), #bias_attr=paddle.ParamAttr(learning_rate=1.0), name='tower_' + str(i))) self._param_tower.append(linear) # [8, 2] linear = self.add_sublayer( name='tower_out_' + str(i), sublayer=nn.Linear( tower_size, 2, weight_attr=nn.initializer.Constant(value=0.1), bias_attr=nn.initializer.Constant(value=0.1), name='tower_out_' + str(i))) self._param_tower_out.append(linear) def forward(self, input_data): """ input_data: Tensor(shape=[2, 499], 2--->batch_size """ inputs_ple = [] # task_num part + shared part # task_num-->2 for i in range(0, self.task_num + 1): inputs_ple.append(input_data) # multiple ple layer ple_out = [] # level_number-->2 for i in range(0, self.level_number): print "^^^^^number: %d^^^^^^"%i ple_out = self.ple_layers[i](inputs_ple) inputs_ple = ple_out # ple_out, [Tensor(shape=[2, 16], Tensor(shape=[2, 16]] #assert len(ple_out) == self.task_num output_layers = [] for i in range(0, self.task_num): # Tensor(shape=[2, 8] cur_tower = self._param_tower[i](ple_out[i]) cur_tower = F.relu(cur_tower) out = self._param_tower_out[i](cur_tower) out = F.softmax(out) out = paddle.clip(out, min=1e-15, max=1.0 - 1e-15) output_layers.append(out) return output_layers class SinglePLELayer(nn.Layer): def __init__(self, input_feature_size, task_num, exp_per_task, shared_num, expert_size, level_name, if_last): super(SinglePLELayer, self).__init__() # input_feature_size: first layer: 499, second layer=expert_size-->16 self.task_num = task_num # 2 self.exp_per_task = exp_per_task # 3 self.shared_num = shared_num # 2 self.expert_size = expert_size # 16 self.if_last = if_last # 1 self._param_expert = [] # task-specific expert part for i in range(0, self.task_num): for j in range(0, self.exp_per_task): # [499, 16] linear = self.add_sublayer( name=level_name + "_exp_" + str(i) + "_" + str(j), sublayer=nn.Linear( input_feature_size, expert_size, weight_attr=nn.initializer.Constant(value=0.1), bias_attr=nn.initializer.Constant(value=0.1), name=level_name + "_exp_" + str(i) + "_" + str(j))) self._param_expert.append(linear) # shared expert part for i in range(0, self.shared_num): # [499, 16] linear = self.add_sublayer( name=level_name + "_exp_shared_" + str(i), sublayer=nn.Linear( input_feature_size, expert_size, weight_attr=nn.initializer.Constant(value=0.1), bias_attr=nn.initializer.Constant(value=0.1), name=level_name + "_exp_shared_" + str(i))) self._param_expert.append(linear) # task gate part self._param_gate = [] cur_expert_num = self.exp_per_task + self.shared_num for i in range(0, self.task_num): # [499, 5] linear = self.add_sublayer( name=level_name + "_gate_" + str(i), sublayer=nn.Linear( input_feature_size, cur_expert_num, weight_attr=nn.initializer.Constant(value=0.1), bias_attr=nn.initializer.Constant(value=0.1), name=level_name + "_gate_" + str(i))) self._param_gate.append(linear) # shared gate if not if_last: # 8 cur_expert_num = self.task_num * self.exp_per_task + self.shared_num # [499, 8] linear = self.add_sublayer( name=level_name + "_gate_shared_", sublayer=nn.Linear( input_feature_size, cur_expert_num, weight_attr=nn.initializer.Constant(value=0.1), bias_attr=nn.initializer.Constant(value=0.1), name=level_name + "_gate_shared_")) self._param_gate_shared = linear def forward(self, input_data): print "****SinglePLELayer forward****" expert_outputs = [] # task-specific expert part # task_num: 2 # exp_per_task: 3 """ _param_expert: level0: [Linear(in_features=499, out_features=16, dtype=float32, name=lev_0_exp_0_0), Linear(in_features=499, out_features=16, dtype=float32, name=lev_0_exp_0_1), Linear(in_features=499, out_features=16, dtype=float32, name=lev_0_exp_0_2), Linear(in_features=499, out_features=16, dtype=float32, name=lev_0_exp_1_0), Linear(in_features=499, out_features=16, dtype=float32, name=lev_0_exp_1_1), Linear(in_features=499, out_features=16, dtype=float32, name=lev_0_exp_1_2), Linear(in_features=499, out_features=16, dtype=float32, name=lev_0_exp_shared_0), Linear(in_features=499, out_features=16, dtype=float32, name=lev_0_exp_shared_1)] level1: [Linear(in_features=16, out_features=16, dtype=float32, name=lev_1_exp_0_0), Linear(in_features=16, out_features=16, dtype=float32, name=lev_1_exp_0_1), Linear(in_features=16, out_features=16, dtype=float32, name=lev_1_exp_0_2), Linear(in_features=16, out_features=16, dtype=float32, name=lev_1_exp_1_0), Linear(in_features=16, out_features=16, dtype=float32, name=lev_1_exp_1_1), Linear(in_features=16, out_features=16, dtype=float32, name=lev_1_exp_1_2), Linear(in_features=16, out_features=16, dtype=float32, name=lev_1_exp_shared_0), Linear(in_features=16, out_features=16, dtype=float32, name=lev_1_exp_shared_1)] """ # [0, 1] for i in range(0, self.task_num): for j in range(0, self.exp_per_task): # [0,1,2] # 0,1,2, 2,3,4 linear_out = self._param_expert[i * self.task_num + j]( # bug, task_num-->exp_per_task input_data[i]) # Tensor(shape=[2, 16] expert_output = F.relu(linear_out) expert_outputs.append(expert_output) # shared expert part # shared_num: 2 # [0, 1] for i in range(0, self.shared_num): # self.exp_per_task * self.task_num = 3*2 linear_out = self._param_expert[self.exp_per_task * self.task_num + i](input_data[-1]) # Tensor(shape=[2, 16] expert_output = F.relu(linear_out) expert_outputs.append(expert_output) # task gate part outputs = [] """ self._param_gate: [Linear(in_features=499, out_features=5, dtype=float32, name=lev_0_gate_0), Linear(in_features=499, out_features=5, dtype=float32, name=lev_0_gate_1)] """ # [0, 1] for i in range(0, self.task_num): # 5 cur_expert_num = self.exp_per_task + self.shared_num # Tensor(shape=[2, 5] linear_out = self._param_gate[i](input_data[i]) cur_gate = F.softmax(linear_out) # Tensor(shape=[2, 5, 1] cur_gate = paddle.reshape(cur_gate, [-1, cur_expert_num, 1]) # f^{k}(x) = sum_{i=1}^{n}(g^{k}(x)_{i} * f_{i}(x)) # expert_outputs[0:3], expert_outputs[3:6] # expert_outputs[-2:] cur_experts = expert_outputs[i * self.exp_per_task:(i + 1) * self.exp_per_task] + \ expert_outputs[-int(self.shared_num):] # Tensor(shape=[2, 80]) expert_concat = paddle.concat(x=cur_experts, axis=1) # [2, 5, 16] expert_concat = paddle.reshape( expert_concat, [-1, cur_expert_num, self.expert_size]) # Tensor(shape=[2, 5, 16] # [2, 5, 16] * Tensor(shape=[2, 5, 1]) cur_gate_expert = paddle.multiply(x=expert_concat, y=cur_gate) # Tensor(shape=[2, 16] cur_gate_expert = paddle.sum(x=cur_gate_expert, axis=1) outputs.append(cur_gate_expert) # shared gate if not self.if_last: # 8 cur_expert_num = self.task_num * self.exp_per_task + self.shared_num # Tensor(shape=[2, 8], [2, 499] * [499, 8] linear_out = self._param_gate_shared(input_data[-1]) cur_gate = F.softmax(linear_out) # Tensor(shape=[2, 8, 1] cur_gate = paddle.reshape(cur_gate, [-1, cur_expert_num, 1]) cur_experts = expert_outputs # Tensor(shape=[2, 128] expert_concat = paddle.concat(x=cur_experts, axis=1) # Tensor(shape=[2, 8, 16]) expert_concat = paddle.reshape( expert_concat, [-1, cur_expert_num, self.expert_size]) # Tensor(shape=[2, 8, 16]), --->[2, 8, 16]*[2, 8, 1] cur_gate_expert = paddle.multiply(x=expert_concat, y=cur_gate) # Tensor(shape=[2, 16]) cur_gate_expert = paddle.sum(x=cur_gate_expert, axis=1) outputs.append(cur_gate_expert) return outputs

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
- 140
- 141
- 142
- 143
- 144
- 145
- 146
- 147
- 148
- 149
- 150
- 151
- 152
- 153
- 154
- 155
- 156
- 157
- 158
- 159
- 160
- 161
- 162
- 163
- 164
- 165
- 166
- 167
- 168
- 169
- 170
- 171
- 172
- 173
- 174
- 175
- 176
- 177
- 178
- 179
- 180
- 181
- 182
- 183
- 184
- 185
- 186
- 187
- 188
- 189
- 190
- 191
- 192
- 193
- 194
- 195
- 196
- 197
- 198
- 199
- 200
- 201
- 202
- 203
- 204
- 205
- 206
- 207
- 208
- 209
- 210
- 211
- 212
- 213
- 214
- 215
- 216
- 217
- 218
- 219
- 220
- 221
- 222
- 223
- 224
- 225
- 226
- 227
- 228
- 229
- 230
- 231
- 232
- 233
- 234
- 235
- 236
- 237
- 238
- 239
- 240
- 241
- 242
- 243
- 244
- 245
- 246
- 247
- 248
- 249
- 250
- 251
- 252
- 253
- 254
- 255
- 256
- 257
- 258
- 259
- 260
- 261
- 262
- 263
- 264
- 265
- 266
- 267
- 268
- 269
- 270
- 271
- 272
- 273
- 274
- 275
- 276
- 277
- 278
- 279
- 280
- 281
- 282
- 283
- 284
- 285
- 286
- 287
- 288
- 289
- 290
- 291
- 292
- 293
loss函数代码:
def net(self, inputs, is_infer=False): input_data = inputs[0] label_income = inputs[1] label_marital = inputs[2] PLE = PLELayer(self.feature_size, self.task_num, self.exp_per_task, self.shared_num, self.expert_size, self.tower_size, self.level_number) pred_income, pred_marital = PLE.forward(input_data) pred_income_1 = paddle.slice( pred_income, axes=[1], starts=[1], ends=[2]) pred_marital_1 = paddle.slice( pred_marital, axes=[1], starts=[1], ends=[2]) auc_income, batch_auc_1, auc_states_1 = paddle.static.auc( #auc_income = AUC( input=pred_income, label=paddle.cast( x=label_income, dtype='int64')) #auc_marital = AUC( auc_marital, batch_auc_2, auc_states_2 = paddle.static.auc( input=pred_marital, label=paddle.cast( x=label_marital, dtype='int64')) if is_infer: fetch_dict = {'auc_income': auc_income, 'auc_marital': auc_marital} return fetch_dict cost_income = paddle.nn.functional.log_loss( input=pred_income_1, label=paddle.cast( label_income, dtype="float32")) cost_marital = paddle.nn.functional.log_loss( input=pred_marital_1, label=paddle.cast( label_marital, dtype="float32")) avg_cost_income = paddle.mean(x=cost_income) avg_cost_marital = paddle.mean(x=cost_marital) cost = avg_cost_income + avg_cost_marital self._cost = cost fetch_dict = { 'cost': cost, 'auc_income': auc_income, 'auc_marital': auc_marital } return fetch_dict
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
参考文献

