
- 1leetcode__前k个高频元素__python_leetcode+ 前 k 个高频元素+python
- 2互联网加竞赛 基于深度学习的目标检测算法
- 3python 文本分析库_Python有趣|中文文本情感分析
- 4Leetcode 24:两两交换链表中的节点
- 5[Python]-python画一朵花
- 6ardupilot编译过程记录_chibios build requires g++ version 10.2.1 or later
- 7操作系统刷题_如果一个计算机的硬盘为64g,每个块的大小为4k,如果用位示图来管理硬盘的空间,则位
- 8运行时的用法积累_[self willchangevalueforkey:@"mj_header"]; // kvo
- 9思科、华为、华三认证,网工心中的三大噩梦_国内服务器厂商 华为 思科 华三
- 10CENTOS上的网络安全工具(十五)cascade的部署_centos7 sysmon
Java基础数据结构之Map和Set
赞
踩
Map和Set接口
1.Set集合:独特性与无序性
Set是Java集合框架中的一种,它代表着一组无序且独特的元素。这意味着Set中的元素不会重复,且没有特定的顺序。Set接口有多个实现类,如HashSet、LinkedHashSet和TreeSet。
2.Map集合:键值对的存储
Map是Java集合框架中的另一种,它存储了一组键值对(Key-Value Pair)。每个键映射到一个值,使得通过键可以高效地检索对应的值。Map接口有多个实现类,如HashMapLinkedHashMap和TreeMap。
搜索树
1.概念
二叉搜索树又称二叉排序树,它或者是一棵空树,或者是具有以下性质的二叉树:
2.创建一个二叉搜索树
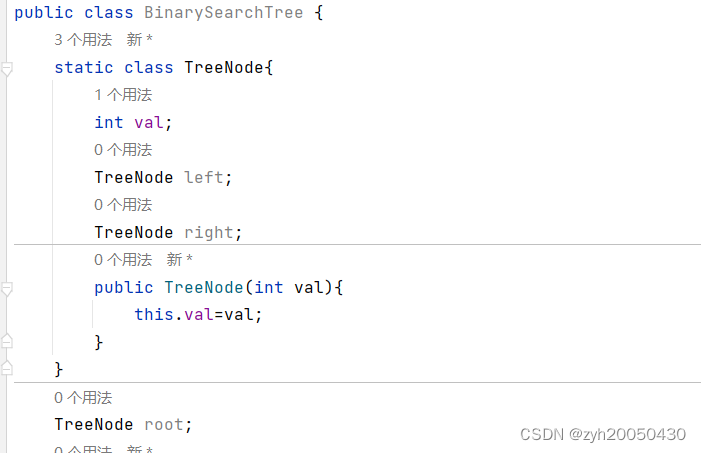
查找:
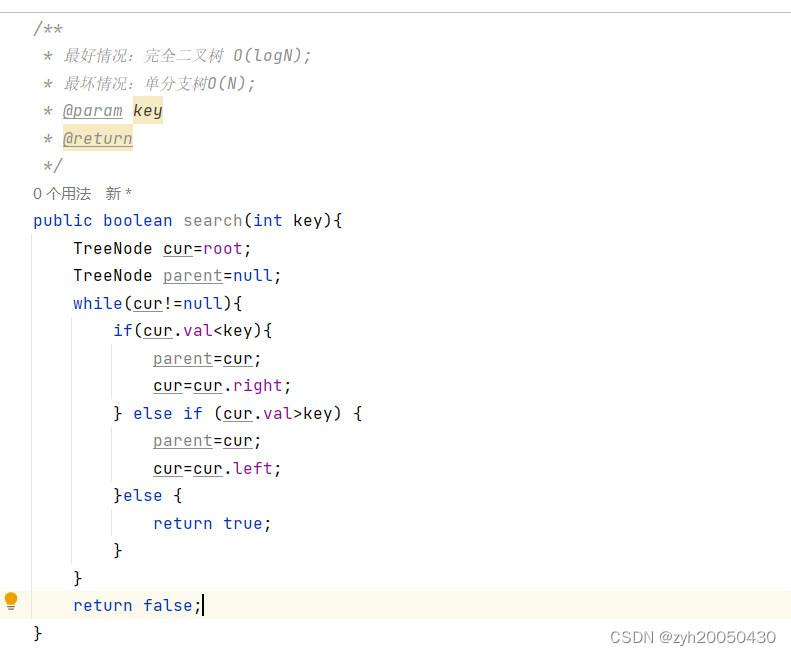
插入:
- public boolean insert2(int val){
- TreeNode node=new TreeNode(val);
- if(root==null){
- root=node;
- } else {
- TreeNode cur=root;
- while(cur!=null){
- if(cur.val<val){
- if(cur.right==null){
- cur.right=node;
- break;
- }else if(cur.right.val>val){
- node.right=cur.right;
- cur.right=node;
- break;
- }else{
- cur=cur.right;
- }
- }else if(cur.val>val){
- if(cur.left==null){
- cur.left=node;
- break;
- }else if(cur.left.val<val){
- node.left=cur.left;
- cur.left=node;
- break;
- }else{
- cur=cur.right;
- }
- }else{
- return false;
- }
- }
- }
- return true;
- }

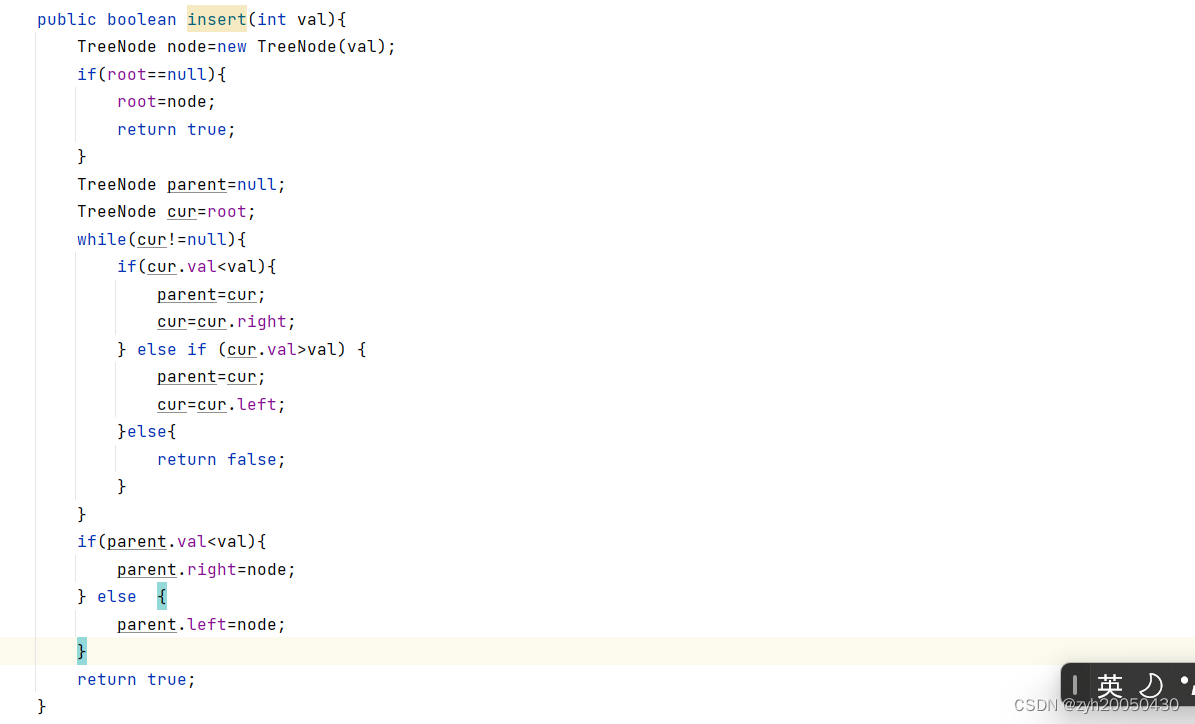
这段代码有问题,对于一个已经有俩个叉的节点,我们不能去更新它的左右孩子,所以对于二叉搜索树的插入操作,必须是在空节点上进行插入,代码如下:
删除:
- public boolean remove(int val){
- TreeNode cur=root;
- TreeNode parent=null;
- while(cur!=null){
- if(cur.val==val){
- break;
- }else if(cur.val<val){
- parent=cur;
- cur=cur.right;
- }else{
- parent=cur;
- cur=cur.left;
- }
- }
- if(cur==null){
- return false;
- } else if (cur.left==null) {
- if(cur==root){
- root=cur.right;
- } else if (cur==parent.left) {
- parent.left=cur.right;
- }else {
- parent.right = cur.right;
- }
- }else if(cur.right==null){
- if(cur==root){
- root=cur.left;
- } else if (cur==parent.left) {
- parent.left=cur.left;
- }else {
- parent.right = cur.left;
- }
- }else{
- TreeNode targetparent=cur;
- TreeNode target=cur.right;
- while(target.left!=null){
- targetparent=target;
- target=target.left;
- }
- if(targetparent==cur){
- cur.val=target.val;
- targetparent.right=target.right;
- }
- cur.val=target.val;
- targetparent.left=target.right;
- }
- return true;
- }
第一个while是找到待删除的节点,
如果待删节点左边为空:如果待删节点是根节点,则让待删节点的右边变成根;如果不是根节点,而是上一个结点的右面……是上一个结点的左面……
如果待删节点右面为空……
如果待删节点左右都不为空,我们的做法是:从待删结点的左边找到最大值(即左边子树的最右面的节点)或者从待删结点的右面找到最小值(即右面子树的最左边节点)。找到之后还要分类,分类如代码所示
3.和Java类集的关系
搜索
1.概念
2.模型
Map的使用
1.实例化子类

这是一个泛型的接口,要传入key和value的类型
假设要统计单词的次数,则对于key是String类型,value是Integer类型,所以如下:

如果实例化TreeMap子类,则其搜索的时间复杂度为O(logN),如果是HashMap,则是O(1)。所以其搜索的效率与其具体的实例化子类有关。
注意,使用时要导入对应的包:

其次,key是唯一的,不可以重复
2.Map中的常用方法

put方法返回值是放入的该单词的次数

get方法,参数是要得到的单词,返回值是单词的次数

getOrDefault方法,如果包含该单词,则返回对应的value,反之返回我们自己传入的defaultValue
boolean containsKey(Object key);判断是否包含key
boolean containsValue(Object value);判断是否包含value
V remove(Object key);删除key,即删除某个单词,返回对应的value即次数
void putAll(Map<? extends K, ? extends V> m);将m中的key和value全部放到map1中,其中,m的key的类型是map1的key的类型的子类,m的value类型是map1的value的类型的子类,如下:

Set<K> keySet();返回所有key的不重复集合,如下:


Collection<V> values();这个方法是返回所有value的集合
返回值是Collection<V>,那我进行向下转型,用ArrayList接收可以吗?试一试:


运行之后发现报错了?为什么呢?这不就是向下转型吗?实际上,这是非法的向下转型!!!看下面的例子,Student是Person的子类
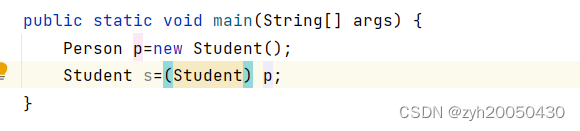
这样的代码在运行时没有报错


这个代码报错了。其实是没真正理解向下转型以及父类和子类的关系
在Java中,父类引用可以指向子类实例,反之则不可以
第一段代码中p是父类引用,它是指向了子类实例,然后将一个子类实例p给到了子类的引用自然是可以的;而第二段代码中p是父类引用并且指向父类实例,然后将哟个父类实例p给到一个子类引用就是不可以的
这也就是为什么不可以用ArrayList来接收Collection类的返回值!!!!!
那么如何存储到ArrayList中?用Arraylist的一个构造方法:

代码如下:
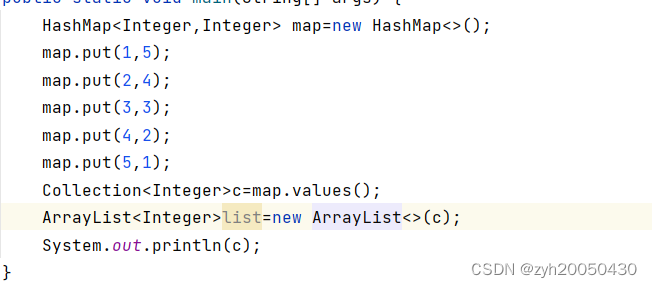
或者将它存放到HashSet中:

Set<Map.Entry<K, V>> entrySet();要想了解这个方法,首先要看一下Map.Entry:
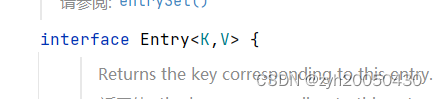
Entry是Map中的一个内部接口,包含了key和value,所以Set<Map.Entry<K, V>> entrySet();这个方法可以将key和value看成一个,都放到set中,如下:


或者如下打印:

3.注意
1.Map中存放的键值对的key是唯一的,value是可以重复的(就比如单词出现的次数的统计)
2.在TreeMap中插入键值对时,key不能为空,value可以为空;而HashMap中的key和value都可以为空
3.Map中的key可全部分离出来存到Set中进行访问
Set的使用
Set使用和Map类似,请详细看源码
只强调几个:
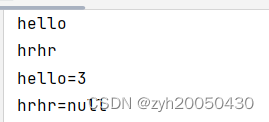
Iterator<E> iterator();用法如下:

boolean addAll(Collection<? extends E> c);
boolean containsAll(Collection<?> c);
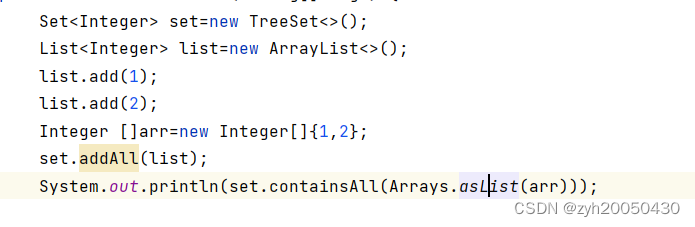
注意这俩个方法的参数是实现了Collection接口的类,所以单纯的整型数组不可以作为参数传递,要用到Arrays中的aslist方法
boolean retainAll(Collection<?> c);这个方法只保留这个集合中包含在指定集合中的元素(可选操作)。换句话说,从这个集合中删除所有不包含在指定集合中的元素
注意:
1.Set时继承自Collection的接口类
2.TreeSet的底层是一个TreeMap
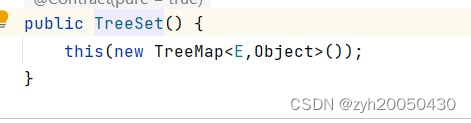
不管实例化一个什么样的TreeSet,value都是一个Object对象
3.Set中的key是唯一的
4.TreeSet的key不能是null,但HashSet可以
5.添加的对象必须是可以进行比较的





