
- 1使用VScode通过内网穿透在公网环境下远程连接进行开发
- 2Linux:vim的简单使用
- 3sql语句用法大全_sql语句大全及用法
- 4数据结构奇妙旅程之栈和队列
- 5金九银十面试题之《数据结构和算法》
- 6docker容器的网络相关操作_e: list directory /var/lib/apt/lists/partial is mi
- 7华为OD机试 - 篮球比赛(Python) | 机试题+算法思路+考点+代码解析 【2023】_算法 篮球比赛
- 8凌华APM204C运控控制卡,判断运动完成_amp204motion
- 9Web自动化之Selenium常用操作_driver.find_element
- 10Android 13 - Media框架(9)- NuPlayer::Decoder_android nuplayer
深度学习 - 53.Bert 简介与 Keras-Bert 常用示例
赞
踩
目录
一.引言
Bert 是 Google 在 18 年发布的 <Pre-training of Deep Bidirectional Transformers for Language Understanding> 中提到的预训练模型,其适用于 NLP 场景且可以基于自己的文本数据进行微调,下面简单介绍下其原理以及 Keras-Bert 的一些基本应用。
二.Bert 简介
Bert 主要由一个 Embedding 层和多个 Encoder 层堆叠而成,下面做简单介绍。
1.Embedding Layer

在构建 bert 输入时,会在每个 Text 的最前面增加一个特殊符号 '[CLS]',除此之外,不同 Sentence 之间还会加入 '[SEP]' 分隔符,标识一个句子的结束。
以上图的句子为例:
- sentence_1 = "my dog is cute"
- sentence_2 = "he likes playing"
- print('Tokens:', tokenizer.tokenize(first=sentence_1, second=sentence_2))
- indices, segments = tokenizer.encode(first=sentence_1, second=sentence_2)
- print('Indices:', indices)
- print('Segments:', segments)

Token 可以认为是分词以及增加特殊符号标识后的句子,通过 tokenizer 转换得到其 index。
Segment 代表每个字符属于第几个句子,上面第一个句子对应索引为0,第二个句子为1。
Position 代表每个字符在整个 Text 的位置信息索引。
Bert 实际使用中输入层使用了 Token Embedding、Segment Embedding 与 Position Embedding 三类向量,将每个类型的 Embedding concat 后再将对应位置的 Embedding 相加就得到原始的 Input。这里 Bert 预训练模型的 Embedding 维度为 768。
2.Encoder layer

Bert 在模型结构上主要使用了 Encoder 的堆叠,其中应用了 Multi-Head Attention 与 Scaled Dot-Product,关于 Multi-Head Attention 与 Scaled Dot Product 我们前面 Attention 的文章已经做了介绍。其可以看作是只使用了 Transformer 的 Encoder 结构,在 Input Embedding 的基础上 Add 了 Position Embedding,随后经过一层 Multi-Head Attention 并且将 Input 与 Attention 的结果相加,避免信息丢失,随后经过一层前馈网络,再执行一次 Add & Norm 进入下一个 Encoder。
3.Pre-training 与 Fine-Tuning
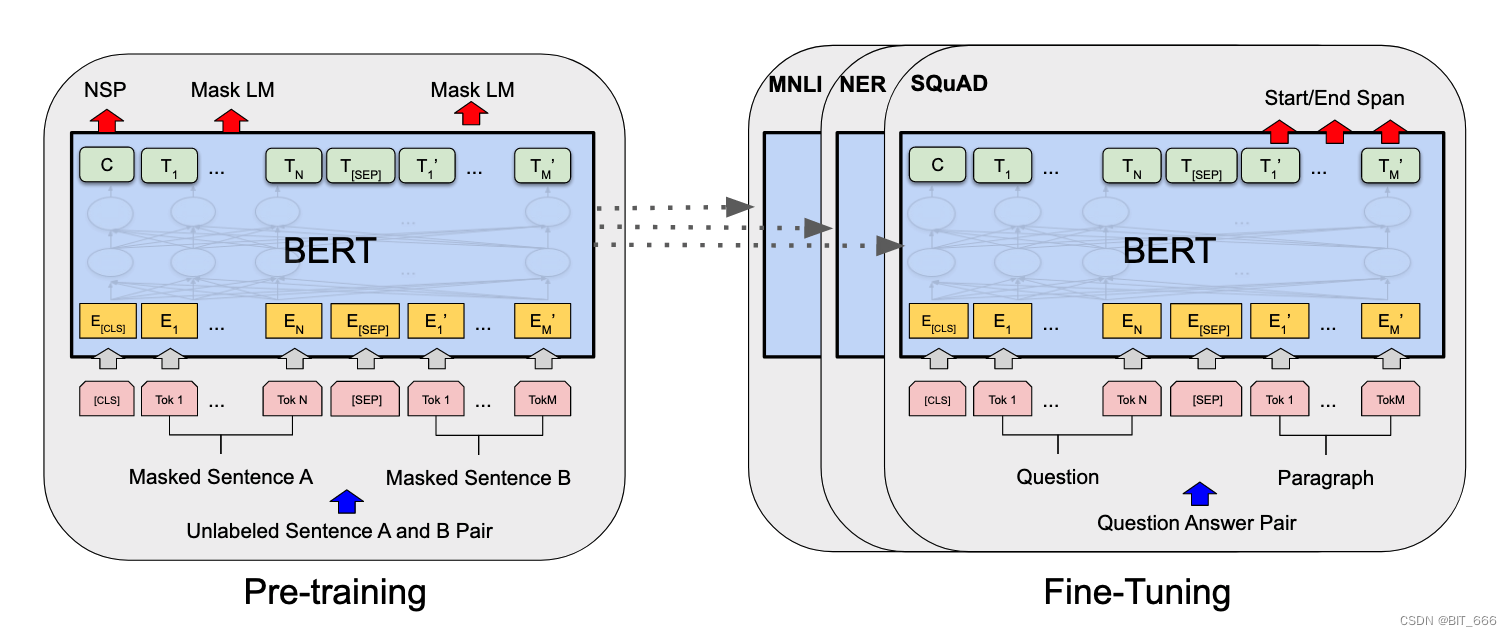
BERT 的全面预训练模型和微调模型。预训练和微调中除了输出层外其余部分使用了相同的架构。相同的预训练模型参数用于初始化不同下游任务的模型。在微调过程中,对所有参数进行微调。根据任务场景不同,Bert 可以完成不同的任务:

• Sentence Pair Classification Tasks 文本对分类任务
• Single Sentence Classification Tasks 单句分类任务
• Question Answering Task 问答任务
• Single Sentence Tagging Task 单句标记任务
上面不同类型任务图下给出了不同的数据集,可用于 Bert 模型的微调,大家也可以使用自己场景的文本问答、新闻报刊等数据进行训练。
三.Keras-Bert 常用 Demo
下述代码运行使用的环境为:
- import tensorflow as tf
- import platform
-
- print("TF: %s Keras: %s Python: %s" % (tf.__version__, tf.keras.__version__, platform.python_version()))
TF: 2.4.0-rc0 Keras: 2.4.0 Python: 3.8.61.获取预训练模型

一般情况下,我们主要使用预训练好的 Bert 进行一些基本的 NLP 任务或者通过 Fine-Tuning 对 Bert 进行一些微调,这里我们加载预训练模型 Bert-Base uncased_L-12_H-768_A-12,其模型名称代表 12-Layer、768-Hidden, 12-Heads 共计约 110M parameters,可以通过 wget 获取该预训练模型:
wget -q https://storage.googleapis.com/bert_models/2018_10_18/uncased_L-12_H-768_A-12.zip

除了 Bert-Base 外,还有 Bert-Large,其包含 340M 个参数的模型,包含 24-Layer 以及 1024-Hidden 以及 16-Heads。一些基础的 Bert 模型可以到 Bert 的 github 选择下载:

2.加载预训练模型
- import numpy as np
- from keras_bert import load_vocabulary, load_trained_model_from_checkpoint, Tokenizer, get_checkpoint_paths
- from keras_bert.datasets import get_pretrained, PretrainedList
-
-
- class Bert:
- _token_dict = None # word ->index
- _token_dict_inv = None # index -> word
- _model = None
- _export_model = None
- _tokenizer = None
-
- def __init__(self, _model_path):
- self._model_path = model_path
- self.loadBertModel(self._model_path)
- self._tokenizer = Tokenizer(self._token_dict)
-
- def loadBertModel(self, path):
-
- paths = get_checkpoint_paths(path)
-
- # 加载预训练模型
- self._model = load_trained_model_from_checkpoint(paths.config, paths.checkpoint, training=True, seq_len=None)
- self._export_model = load_trained_model_from_checkpoint(paths.config, paths.checkpoint, seq_len=10)
- self._model.summary(line_length=120)
-
- # 字典映射与反映射
- self._token_dict = load_vocabulary(paths.vocab)
- self._token_dict_inv = {v: k for k, v in self._token_dict.items()}
通过 load_trained_model_from_checkpoint 读取预训练模型,seq_len = None 的模型主要处理不定长的 sentence 问题,seq_len 固定的 export 模型主要用于 Embedding 获取。token_dict 和 token_dict_inv 为 kv 相反的 map,token_dict 形式如下,共包含不同的符号 21128 个:

顺便调用 model.summary() 看下模型结构:
• Embedding

包含 Token、Segment 与 Position Embedding,最后经过 Dropout 与 Norm 进入后续逻辑。
• Encoder
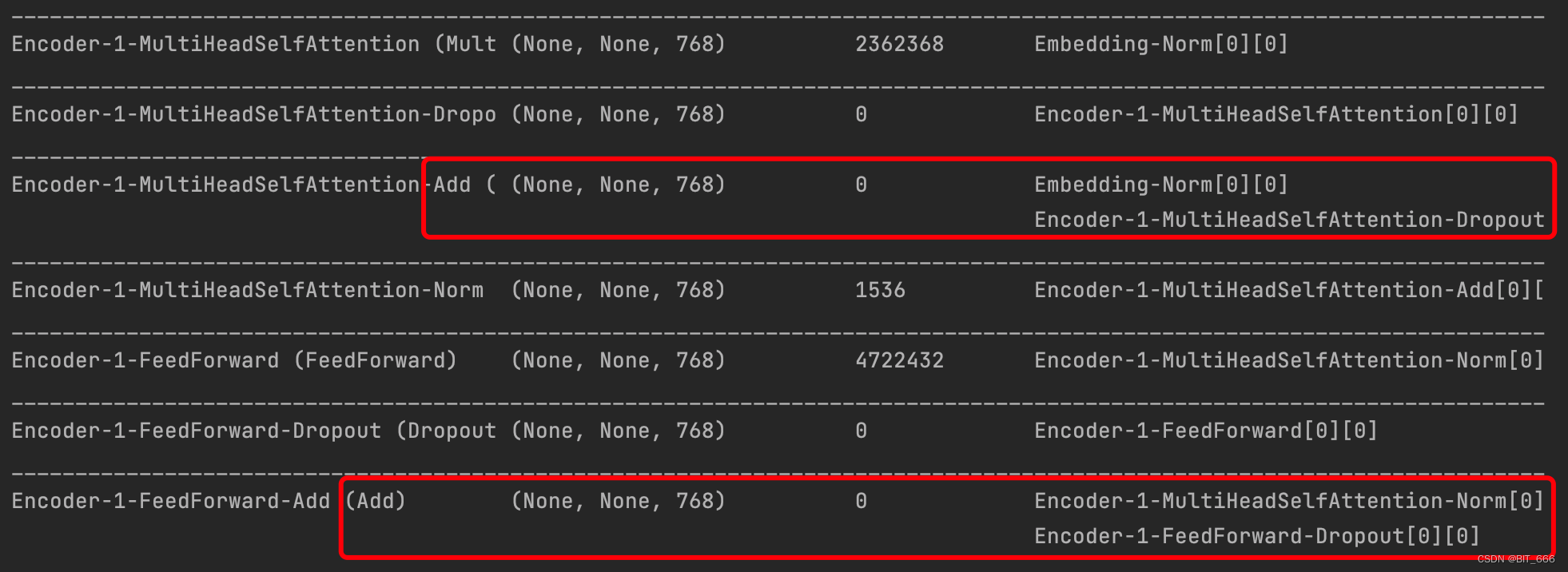
将 Embedding 层得到的 Embedding-Norm 进行 MultiHeadSelfAttention,以及 Dropout 以及 Norm 随后接 FeedForward 前馈网络接着继续 Dropout。注意两个红框位置,MultiHeadAttention 与 FeedForward 后得到的向量斗鱼原始输入的向量进行了 Add 操作:

这里 Add 操作可以避免随着 Encoder 堆叠层数的增加,原始信息的不断衰减。
• Output
最后的输出层 MLM (masked) 代表 Masked Language Model 可以进行序列重建,NSP 代表 Next Sentence Prediction 可以进行句子间的二分类任务,例如判断后一句话与前一句话是否有关联。由于加载的是 Bert-Base,所以最后的 Layer 是 Encoder-12,且模型的 Total params 约为 102882442 即 100m。

3.Fill Text
句子填字可以实现句子补全与填空,让 bert 填入最合适 [概率最大的词]。
- # 填字
- def fillText(self, _text, _st, _end):
- tokens = self._tokenizer.tokenize(_text)
-
- for i in range(_st, _end + 1):
- tokens[i] = '[MASK]'
- print('Tokens:', tokens)
-
- # 映射后的索引、代表句子、代表Mask掩码
- indices = np.array([[self._token_dict[token] for token in tokens]])
- segments = np.array([[0] * len(tokens)])
-
- masks = np.array([[0] * len(tokens)])
- for i in range(_st, _end + 1):
- masks[0][i] = 1
-
- # 填字预测
- predicts = self._model.predict([indices, segments, masks])[0].argmax(axis=-1).tolist()
- print('Fill with: ', list(map(lambda x: self._token_dict_inv[x], predicts[0][_st:_end + 1])))
text 为对应填词的文本,st 与 end 可以指定 mask 掩码的位置然后让 bert 在这个范围内进行填充,注意由于 bert Input Embedding 时会在开头添加 '[CLS]',所有对应位置的索引需要 +1,所以下面示例中 1、2 对应的是 '数学':
- # 填充字符
- text = '数学是利用符号语言研究数量、结构、变化以及空间等概念的一门学科'
- st, end = 1, 2
- bert.fillText(text, st, end)
- st, end = 4, 5
- bert.fillText(text, st, end)
原文的前五个字为 '数学是利用',我们分别将 '数学' 和 '利用' 进行 MASK 处理,这里分别填充了 '数学' 和 '使用',基本匹配:

4.IsCorrelation
是否相关判断 sentence_1 和 sentence_2 在语料训练后的文本场景下,前后语句是否有关联。
- # 两个句子是否有关联
- def hasCorrelation(self, _sentence_1, _sentence_2):
- indices, segments = self._tokenizer.encode(first=_sentence_1, second=_sentence_2)
- masks = np.array([[0] * len(indices)])
-
- predicts = self._model.predict([np.array([indices]), np.array([segments]), masks])[1]
- is_correlation = bool(np.argmax(predicts, axis=-1)[0])
- print('%s && %s is has Correlation: ' % (_sentence_1, _sentence_2), is_correlation)
- return is_correlation
给定三个学科相关的语句,让 Bert-Base 判断前后语句是否存在关联:
- # 判断前后逻辑是否一致
- sentence_1 = '数学是利用符号语言研究數量、结构、变化以及空间等概念的一門学科。'
- sentence_2 = '从某种角度看屬於形式科學的一種。'
- sentence_3 = '任何一个希尔伯特空间都有一族标准正交基。'
- bert.hasCorrelation(sentence_1, sentence_2)
- bert.hasCorrelation(sentence_1, sentence_3)
sentence_1 与 sentence_2 无关,sentenct_1 与 sentenct_3 相关:
![]()
5.Get Embedding
上篇介绍多样性时介绍了 MMR 算法,其通过预训练向量计算不同 item 之间的 sim(i,j),这里 bert 就可以作为预训练 Embedding 获取的模型。
• 获取词向量
获取向量时需要用 expert_model,且 encode 的 max_len 参数要与模型的 max_len 参数对应。这里实际获取的向量维度为 768,大家也可以不使用 [:5] 截断。
- def getCharEmbedding(self, _text):
- tokens = self._tokenizer.tokenize(_text)
- print('Tokens:', tokens)
- indices, segments = self._tokenizer.encode(first=_text, max_len=10)
- predicts = self._export_model.predict([np.array([indices]), np.array([segments])])[0]
-
- for i, token in enumerate(tokens):
- print(token, predicts[i].tolist()[:5])

• 获取文本向量
- def getTextEmbedding(self, _text):
- tokens = self._tokenizer.tokenize(text)
- print('Tokens:', tokens)
- indices, segments = self._tokenizer.encode(first=text, max_len=10)
-
- predicts = self._export_model.predict([np.array([indices]), np.array([segments])])[0]
- pooled = np.array(np.sum(predicts, axis=0))
- print('Pooled:', pooled.shape)
- return pooled
虽然传入的 text 只有 6 个字符,但是默认了 max_len = 10, 所以 tokenizer 对原句进行了 Padding,最后 pooling 的方式不局限于 sum pooling ,也可以 mean_pooling、max_pooling 等,输出的向量维度为 max_len x 768,由于后四位是 padding 得来的,如果想要更准确的向量,可以通过 mask 擦除对应 padding 的向量。

MMR 时我们可以通过传入文本的内容再 getTextEmbedding 获取文本 Embedding 然后计算向量相似度,不过这里是 Base-Bert,如果有自己文本的训练微调,效果会更好。
6.完整代码
- import numpy as np
- from keras_bert import load_vocabulary, load_trained_model_from_checkpoint, Tokenizer, get_checkpoint_paths
- from keras_bert.datasets import get_pretrained, PretrainedList
-
-
- class Bert:
- _token_dict = None # word ->index
- _token_dict_inv = None # index -> word
- _model = None
- _export_model = None
- _tokenizer = None
-
- def __init__(self, _model_path):
- self._model_path = model_path
- self.loadBertModel(self._model_path)
- self._tokenizer = Tokenizer(self._token_dict)
-
- def loadBertModel(self, path):
-
- paths = get_checkpoint_paths(path)
-
- # 加载预训练模型
- self._model = load_trained_model_from_checkpoint(paths.config, paths.checkpoint, training=True, seq_len=None)
- self._export_model = load_trained_model_from_checkpoint(paths.config, paths.checkpoint, seq_len=10)
- self._model.summary(line_length=120)
-
- # 字典映射与反映射
- self._token_dict = load_vocabulary(paths.vocab)
- self._token_dict_inv = {v: k for k, v in self._token_dict.items()}
-
- # 填字
- def fillText(self, _text, _st, _end):
- tokens = self._tokenizer.tokenize(_text)
-
- for i in range(_st, _end + 1):
- tokens[i] = '[MASK]'
- print('Tokens:', tokens)
-
- # 映射后的索引、代表句子、代表Mask掩码
- indices = np.array([[self._token_dict[token] for token in tokens]])
- segments = np.array([[0] * len(tokens)])
-
- masks = np.array([[0] * len(tokens)])
- for i in range(_st, _end + 1):
- masks[0][i] = 1
-
- # 填字预测
- predicts = self._model.predict([indices, segments, masks])[0].argmax(axis=-1).tolist()
- print('Fill with: ', list(map(lambda x: self._token_dict_inv[x], predicts[0][_st:_end + 1])))
-
- # 两个句子是否有关联
- def hasCorrelation(self, _sentence_1, _sentence_2):
- indices, segments = self._tokenizer.encode(first=_sentence_1, second=_sentence_2)
- masks = np.array([[0] * len(indices)])
-
- predicts = self._model.predict([np.array([indices]), np.array([segments]), masks])[1]
- is_correlation = bool(np.argmax(predicts, axis=-1)[0])
- print('%s && %s is has Correlation: ' % (_sentence_1, _sentence_2), is_correlation)
- return is_correlation
-
- def getCharEmbedding(self, _text):
- tokens = self._tokenizer.tokenize(_text)
- print('Tokens:', tokens)
- indices, segments = self._tokenizer.encode(first=_text, max_len=10)
- predicts = self._export_model.predict([np.array([indices]), np.array([segments])])[0]
-
- for i, token in enumerate(tokens):
- print(token, predicts[i].tolist()[:5])
-
- def getTextEmbedding(self, _text):
- tokens = self._tokenizer.tokenize(text)
- print('Tokens:', tokens)
- indices, segments = self._tokenizer.encode(first=text, max_len=10)
- print('Indices:', indices)
- print('Segments:', segments)
-
- predicts = self._export_model.predict([np.array([indices]), np.array([segments])])[0]
- pooled = np.array(np.sum(predicts, axis=0))
- print('Pooled:', pooled.shape)
- return pooled
-
-
- if __name__ == '__main__':
- # 获取模型路径
- model_path = get_pretrained(PretrainedList.chinese_base)
-
- # 加载模型
- bert = Bert(model_path)
-
- # 填充字符
- text = '数学是利用符号语言研究数量、结构、变化以及空间等概念的一门学科'
- st, end = 1, 2
- bert.fillText(text, st, end)
- st, end = 4, 5
- bert.fillText(text, st, end)
-
- # 判断前后逻辑是否一致
- sentence_1 = '数学是利用符号语言研究數量、结构、变化以及空间等概念的一門学科。'
- sentence_2 = '从某种角度看屬於形式科學的一種。'
- sentence_3 = '任何一个希尔伯特空间都有一族标准正交基。'
- bert.hasCorrelation(sentence_1, sentence_2)
- bert.hasCorrelation(sentence_1, sentence_3)
-
- # 获取字符 Embedding
- text = '语言模型'
- bert.getCharEmbedding(text)
-
- # 获取 Text Pooling 后的 Embedding
- bert.getTextEmbedding(text)
代码中给出了模型加载以及上面几个常用方法示例。
四. Fine-Tuning
Kreas-Bert 给出了基于 TPU 的 Imdb 数据的 Fine-Tuning 示例,由于原代码版本为 TF1,博主环境为 TF2,博主对代码进行了修改实现 TF2 的兼容,但是训练第一个 Epoch 时会无报错退出,这里给出代码,如果有可以跑通的同学可以评论区交流 ~
- import codecs
- from keras_bert import load_trained_model_from_checkpoint
- import os
- import numpy as np
- from tqdm import tqdm
- from keras_bert import Tokenizer
- import tensorflow as tf
-
- tf.compat.v1.disable_eager_execution()
- SEQ_LEN = 128
- BATCH_SIZE = 128
- EPOCHS = 5
- LR = 1e-4
-
- if __name__ == '__main__':
-
- pretrained_path = './uncased_L-12_H-768_A-12'
- config_path = os.path.join(pretrained_path, 'bert_config.json')
- checkpoint_path = os.path.join(pretrained_path, 'bert_model.ckpt')
- vocab_path = os.path.join(pretrained_path, 'vocab.txt')
-
- # TF_KERAS must be added to environment variables in order to use TPU
- os.environ['TF_KERAS'] = '1'
-
- token_dict = {}
- with codecs.open(vocab_path, 'r', 'utf8') as reader:
- for line in reader:
- token = line.strip()
- token_dict[token] = len(token_dict)
-
- # with strategy.scope():
- model = load_trained_model_from_checkpoint(
- config_path,
- checkpoint_path,
- training=True,
- trainable=True,
- seq_len=SEQ_LEN,
- )
-
- dataset = tf.keras.utils.get_file(
- fname="aclImdb.tar.gz",
- origin="http://ai.stanford.edu/~amaas/data/sentiment/aclImdb_v1.tar.gz",
- extract=True,
- )
-
- tokenizer = Tokenizer(token_dict)
-
-
- def load_data(path):
- global tokenizer
- indices, sentiments = [], []
- for folder, sentiment in (('neg', 0), ('pos', 1)):
- folder = os.path.join(path, folder)
- for name in tqdm(os.listdir(folder)):
- with open(os.path.join(folder, name), 'r') as reader:
- text = reader.read()
- ids, segments = tokenizer.encode(text, max_len=SEQ_LEN)
- indices.append(ids)
- sentiments.append(sentiment)
- items = list(zip(indices, sentiments))
- np.random.shuffle(items)
- indices, sentiments = zip(*items)
- indices = np.array(indices)
- mod = indices.shape[0] % BATCH_SIZE
- if mod > 0:
- indices, sentiments = indices[:-mod], sentiments[:-mod]
- return [indices, np.zeros_like(indices)], np.array(sentiments)
-
-
- train_path = os.path.join(os.path.dirname(dataset), 'aclImdb', 'train')
- test_path = os.path.join(os.path.dirname(dataset), 'aclImdb', 'test')
-
- train_x, train_y = load_data(train_path)
- test_x, test_y = load_data(test_path)
-
- from tensorflow.python import keras
- from keras_radam import RAdam
-
- inputs = model.inputs[:2]
- dense = model.get_layer('NSP-Dense').output
- outputs = keras.layers.Dense(units=2, activation='softmax')(dense)
-
- model = keras.models.Model(inputs, outputs)
- model.compile(
- RAdam(lr=LR),
- loss='sparse_categorical_crossentropy',
- metrics=['sparse_categorical_accuracy'],
- )
-
- sess = tf.compat.v1.keras.backend.get_session()
-
- uninitialized_variables = set([i.decode('ascii') for i in sess.run(tf.compat.v1.report_uninitialized_variables())])
- init_op = tf.compat.v1.variables_initializer(
- [v for v in tf.compat.v1.global_variables() if v.name.split(':')[0] in uninitialized_variables]
- )
- sess.run(init_op)
-
- model.fit(
- train_x,
- train_y,
- epochs=EPOCHS,
- batch_size=BATCH_SIZE,
- )
-
- predicts = model.predict(test_x, verbose=True).argmax(axis=-1)
- print(np.sum(test_y == predicts) / test_y.shape[0])
五.Bert VS OpenAI GPT

论文中给出了 Bert、OpenAI GPT 以及 ELMo 的预训练模型架构差异。 BERT 使用双向 Transformer、OpenAI GPT使用从左到右的 Transformer、ELMo 使用独立训练的从左到右和从右到左的 lstm 的连接来为下游任务生成特征。在这三种表示中,只有 BERT 同时以所有层中的左右上下文为条件。除了架构差异之外,BERT 和 OpenAI GPT 是一种微调方法,而 ELMo 是一种基于特性的方法。当时对标的 GPT 其实是 GPT-2,这里提供一个简单的 demo 供大家参考:
- #!/usr/bin/env Python
- # coding=utf-8
-
- from transformers import GPT2LMHeadModel, GPT2Tokenizer
- import torch
-
- # 初始化GPT2模型的Tokenizer类.
- tokenizer = GPT2Tokenizer.from_pretrained("gpt2")
- # 初始化GPT2模型, 此处以初始化GPT2LMHeadModel()类的方式调用GPT2模型.
- model = GPT2LMHeadModel.from_pretrained('gpt2')
-
- # GPT模型第一次迭代的输入的上下文内容, 将其编码以序列化.同时, generated也用来存储GPT2模型所有迭代生成的token索引.
- generated = tokenizer.encode("The Tower bridge") # generated: [11708] => [11708, 13]
- # 将序列化后的第一次迭代的上下文内容转化为pytorch中的tensor形式.
- context = torch.tensor([generated]) # context: tensor([[11708]])
- # 第一次迭代时还无past_key_values元组.
- past_key_values = None
-
- iter_num = 30
-
- for i in range(iter_num):
- '''
- 此时模型model返回的output为CausalLMOutputWithPastAndCrossAttentions类,
- 模型返回的logits以及past_key_values对象为其中的属性,
- CausalLMOutputWithPastAndCrossAttentions(
- loss=loss, # tensor([[[-34.2719, -33.7875, -36.4804, ..., -40.9417, -40.9629, -33.9127]]], grad_fn=<UnsafeViewBackward0>)
- logits=lm_logits,
- past_key_values=transformer_outputs.past_key_values, #
- hidden_states=transformer_outputs.hidden_states,
- attentions=transformer_outputs.attentions,
- cross_attentions=transformer_outputs.cross_attentions,
- )
- '''
-
- output = model(context, past_key_values=past_key_values)
- past_key_values = output.past_key_values
- # 此时获取GPT2模型计算的输出结果hidden_states张量中第二维度最后一个元素的argmax值, 得出的argmax值即为此次GPT2模型迭代
- # 计算生成的下一个token. 注意, 此时若是第一次迭代, 输出结果hidden_states张量的形状为(batch_size, sel_len, n_state);
- # 此时若是第二次及之后的迭代, 输出结果hidden_states张量的形状为(batch_size, 1, n_state), all_head_size=n_state=nx=768.
- logits = output.logits
- v = logits[..., -1, :]
- token = torch.argmax(output.logits[..., -1, :]) # token: tensor(13)
-
- # 将本次迭代生成的token的张量变为二维张量, 以作为下一次GPT2模型迭代计算的上下文context.
- context = token.unsqueeze(0)
- # 将本次迭代计算生成的token的序列索引变为列表存入generated
- generated += [token.tolist()]
-
- # 将generated中所有的token的索引转化为token字符.
- sequence = tokenizer.decode(generated)
- sequence = sequence.split(".")[:-1]
- print(sequence)
给定 'The Tower Bridge' 和迭代次数,GPT-2 会不断迭代并通过 argmax 获取概率最大的词并 += 添加至 generated 中,最后将 generated decode 得到文本:
['The Tower bridge is a great place to get to know the city', " It's a great place to get to know the city"]
六.总结
昨天 MMR 算法中提到了 Bert 生成文本向量,今天趁热打铁简单介绍下 Bert。工业场景下,可以利用 Bert 和 GPT 进行业务场景的微调并应用于文案、文案 Embedding 生成等任务。
参考:
Pre-training of Deep Bidirectional Transformers for Language Understanding
更多推荐算法相关深度学习:深度学习导读专栏

