
- 1Centos 7上实现Python3程序开机自启动_centos7 如何把python程序设为自启动
- 2props与state的区别_state和props
- 3有向图环路_有向图中找到所有环
- 4Linux命令大全(超详细版)_linux命令行大全
- 5最新最全的前端面试题集锦之 Vue 全家桶篇(从基础到高级,最新最全最详细解答)_vue全家桶面试题
- 6nohup命令解决SpringBoot/java -jar命令启动项目运行一段时间自动停止问题_jar更新时怎么避免服务停止
- 7OpenShift从入门到精通系列之二:深入了解OpenShift与K8S的关系
- 8Vue实现大文件分片上传、断点续传_vue大文件分片上传
- 9python threadPool 与 multiprocessing.Pool
- 10Java排序方法sort的使用详解_java中sort
深度学习 - 21.TF x Keras DSSM 理论与实践_keras分类实战 共享双塔实战
赞
踩
一.引言
DSSM (Learning Deep Structured Semantic Models for Web Search using Clickthrough Data) 一文利用点击数据挖掘词语的深层语义模型,其思路是构建一个 Query 塔和一个 Doc 塔,利用深度学习进行特征挖掘,最终计算两个塔的向量相似度,结合标签进行反向传播训练,所以 DSSM 又叫双塔,其应用场景主要以搜索,召回等场景为主,当然也可用于给定 user-item 计算其向量与相似度,下面就看看双塔如何构造。
二.DSSM 理论
1.模型简介
DSSM 相关论文可以参考 《 Learning Deep Structured Semantic Models for Web Search using Clickthrough Data》,其主要模型结构如下:

Q 为 Query 塔,D是 Doc 塔,由于文本特征的 one-hot 表征多为稀疏向量,DSSM 通过多层 DNN 将高维的稀疏文本特征映射到低维度的语义空间,如图所示这里原始文本的 one-hot 维度为 500k 维度,最终通过 Dense 层压缩到 128 维的语义空间。
第一层 W1 Word Hashing,除了 DNN,还可以尝试 CNN,LSTM 等模型进行特征提取,不过核心思想都是压缩原始语义空间,将高维度映射到低维。这里 DNN 默认的激活函数采用 Tanh,不是常用的 Relu,需要注意。

最终的概率计算采用的是 条件概率 + SoftMax,相似度计算采用的是余弦相似度。通过最小化条件概率函数与 SGD 随机梯度下降更新迭代模型。

2.模型应用
由于 DSSM 采用双塔结构将高维语义映射到低维空间,所以 DSSM 模型也多用于获取特征向量, 模型经过训练后给定 Query 样本和 Doc 样本通过 Query 和 Doc 塔两个模型即可获取各自的 K 维向量作为其表征,也可以利用向量计算文本语义特征等等,也有同学结合 MF,Word2vec,LDA,PCA 等方法进行语义特征的向量化,其目的都是要抽象化语义表征。
三.DSSM 实践
这里模拟构造了一批 user-item 的数据,以及 user 对 item的行为,有行为记为1,无行为记为0,通过 DSSM 双塔模型训练得到 user-tower 和 item-tower 获取 user 与 item 的向量并计算其匹配程度。
1.数据准备
- # 1.生成用户,商品 one-hot 特征
- num_samples = 10000
- max_length = 500
-
- # one-hot 多维序列
- def one_hot_sequences(sequences, dimension=500):
- result = np.zeros((len(sequences), dimension))
- for i, sequence in enumerate(sequences):
- result[i, sequence] = 1
- return result
-
-
- user_feat = np.random.randint(0, max_length, size=(num_samples, 200))
- item_feat = np.random.randint(0, max_length, size=(num_samples, 200))
-
- user_feat = one_hot_sequences(user_feat, max_length)
- item_feat = one_hot_sequences(item_feat, max_length)
-
-
- # 2.构建预测标签
- predict_label = np.random.randint(0, 2, size=num_samples)
num_sample 代表模拟样本的条数,max_length 代表最大的特征索引,最终得到的用户数据,商品数据如下:
- 用户矩阵维度: (10000, 500)
- 商品矩阵维度: (10000, 500)
- 预测标签维度: (10000,)
- 预测标签实例: [0 1 0 1 1 1 0 0 1 1]
user,item的原始特征都是 500 维的 one-hot 特征,样例如下:

2.DSSM 双塔构建
K=16,参考模型简介处最后一层 semantic 的维度,即映射文本空间的维度,K值可以根据场景以及特征维度的不同进行调节。
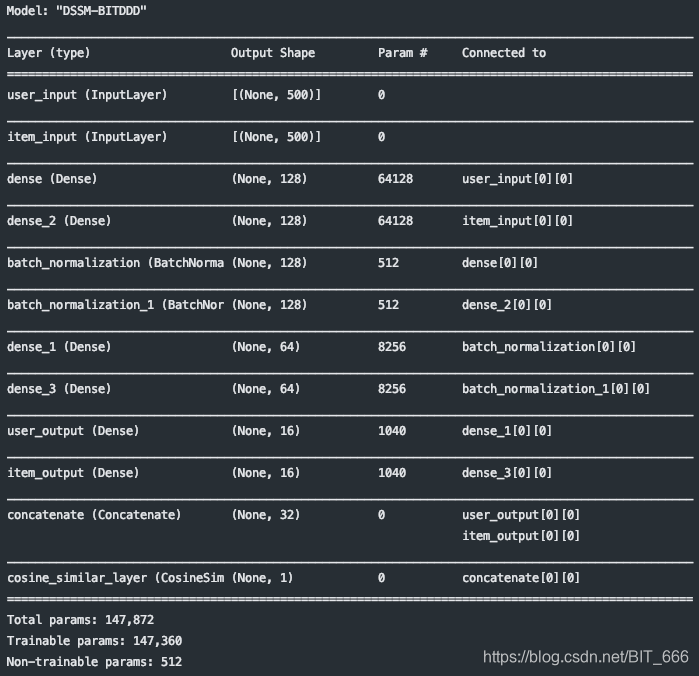
由于输入样本格式一致,所以 User 塔和 Item 塔的构造相同,三个 Dense 层的堆叠,激活函数采用 Tanh,这里在第一层 Dense 后加了一层 BN 防止特征过于稀疏导致模型梯度消失 or 爆炸。
最后通过 concatLayer 结合双塔并计算相似度,DSSM 其实就是扩展版的多输入模型,多输入模型的使用之前也有提到:多输入模型 Demo,可以参考。
- k = 16
- # User 塔
- user_input = Input(shape=max_length, name="user_input")
- user_dense1 = Dense(128, activation='tanh')(user_input)
- bn1 = BatchNormalization(trainable=True)(user_dense1)
- user_dense2 = Dense(64, activation='tanh')(bn1)
- user_dense3 = Dense(k, activation='tanh', name='user_output')(user_dense2)
-
- # item 塔
- item_input = Input(shape=max_length, name="item_input")
- item_dense1 = Dense(128, activation='tanh')(item_input)
- bn2 = BatchNormalization(trainable=True)(item_dense1)
- item_dense2 = Dense(64, activation='tanh')(bn2)
- item_dense3 = Dense(k, activation='tanh', name="item_output")(item_dense2)
-
- concat = concatenate([user_dense3, item_dense3], axis=-1)
-
- # 双塔相似度计算
- similar = CosineSimilarLayer()(concat)
- model = Model([user_input, item_input], similar, name="DSSM")
- model.summary()
模型结构如下图:
3.模型编译与训练
预测标签为0,1值,所以采用二分类交叉熵,也有同学使用 MSE,场景不同使用方式不同。其他超参实际应用中大家也可以多多尝试。
- model.compile(optimizer='rmsprop',
- loss='binary_crossentropy',
- metrics=['accuracy'])
-
- model.fit([user_feat, item_feat], predict_label, epochs=10, batch_size=128)
由于是 numpy 随机的数据,相关指标就不做参考,只为验证流程是否可用。
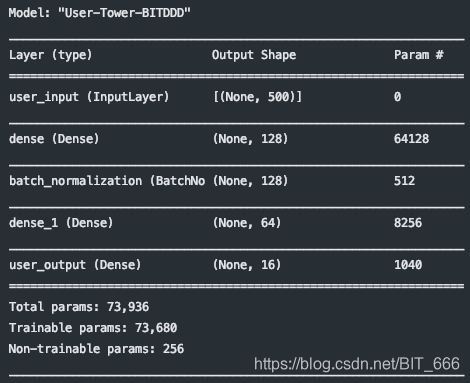
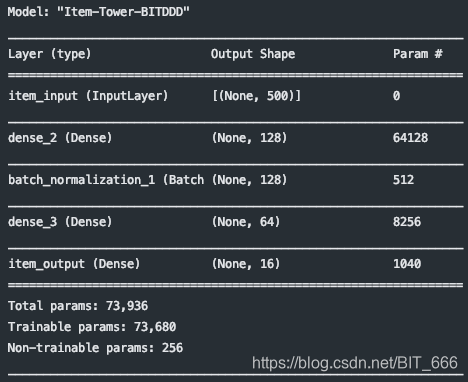
4.利用模型构建 User-tower 与 Item-tower
DSSM 训练结束后,分别构建用户塔与商品塔,给定测试样本即可获取 K 维向量表征用户与商品,同时计算 user-item 的相似度。
- # 7.构建双塔 - 用户塔 vs 商品塔
- user_tower = Model(user_input, user_dense3, name="User-Tower")
- item_tower = Model(item_input, item_dense3, name="Item-Tower")
-
- test_samples = 1
- test_user_feat = one_hot_sequences(np.random.randint(0, max_length, size=(test_samples, 200)), max_length)
- test_item_feat = one_hot_sequences(np.random.randint(0, max_length, size=(test_samples, 200)), max_length)
- user_vector = user_tower.predict([test_user_feat])[0]
- print("测试用户向量 K=16")
- print(user_vector)
- item_vector = item_tower.predict([test_item_feat])[0]
- print("测试商品向量 K=16")
- print(item_vector)
-
- # 8.计算匹配程度
- similar_score = K.sum(user_vector * item_vector, axis=-1, keepdims=True)
- print("相似度: ", similar_score.numpy())
User-tower :
Item-tower :
user-1 与 item-1 的向量表征与相似度:

四.总结
上述实现了基础版的 DSSM,除此之外 WordHash方法的选取,模型深度与大小,激活函数,向量的相似度计算都可以进行不同的尝试,至于使用场景与使用效果就仁者见仁智者见智了。转载请注明出处~
更多推荐算法相关深度学习:深度学习导读专栏


