
热门标签
热门文章
- 1Unity bundle的制作和使用_unity buildbundle
- 2web网页设计—— 中国餐饮协会(HTML+CSS)
- 3带你玩转新一代无服务器产品:IBM Cloud Code Engine(一)_code engine 和 functions的区别
- 4【React】如何使antd禁用状态的表单输入组件响应点击事件?
- 5Kafka 安装部署及使用(单节点/集群)_kafka0.9集群安装
- 6游戏开发小结——Unity 2.5D 平台游戏:跳墙(新输入系统)_unity2.5d可以实现跳跃吗
- 7android 换肤框架搭建及使用 (3 完结篇)_android 系统源码级换肤框架
- 8拉普拉斯锐化详解_拉普拉斯锐化原理
- 9java进阶笔记线程与并发之高性能随机数ThreadLocalRandom_threadlocalrandom.current().nextint 并发 重复
- 10Java常用类库之集合概念_java常用类库概念
当前位置: article > 正文
bert-embedding 安装及使用入门_bert_embedding库的安装
作者:编程变革者 | 2024-01-30 14:40:16
赞
踩
bert_embedding库的安装
安装
- pip install bert-embedding
- #如果要使用GPU
- pip install mxnet-cu92
Note:
1. 安装过程中如果遇到WinError 5的权限问题,需要添加--user参数,即pip install --user mxnet-cu92
2. 若要支持cuda10.0需使用命令 pip install mxnet-cu100安装
3. 验证: 进入python 交互编辑器,输入命令from bert-embedding import BertEmbedding。如没有报错,则表示安装成功。
使用
- from bert_embedding import BertEmbedding
-
- bert_abstract = """We introduce a new language representation model called BERT, which stands for Bidirectional Encoder Representations from Transformers.
- Unlike recent language representation models, BERT is designed to pre-train deep bidirectional representations by jointly conditioning on both left and right context in all layers.
- As a result, the pre-trained BERT representations can be fine-tuned with just one additional output layer to create state-of-the-art models for a wide range of tasks, such as question answering and language inference, without substantial task-specific architecture modifications.
- BERT is conceptually simple and empirically powerful.
- It obtains new state-of-the-art results on eleven natural language processing tasks, including pushing the GLUE benchmark to 80.4% (7.6% absolute improvement), MultiNLI accuracy to 86.7 (5.6% absolute improvement) and the SQuAD v1.1 question answering Test F1 to 93.2 (1.5% absolute improvement), outperforming human performance by 2.0%."""
-
- sentences = bert_abstract.split('\n')
- bert_embedding = BertEmbedding()
- result = bert_embedding(sentences)
执行结果为如下图所示的包含元组(tokens, tokens embedding)的列表。
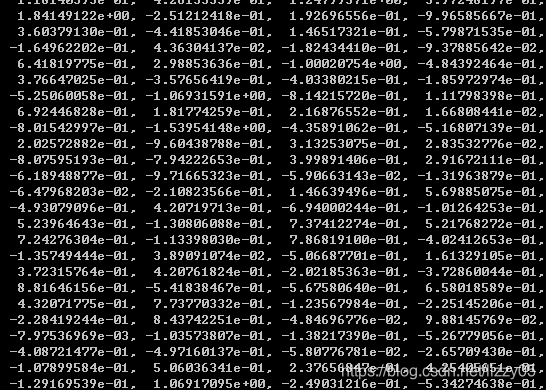
- first_sentence = result[0]
-
- first_sentence[0]
- # ['we', 'introduce', 'a', 'new', 'language', 'representation', 'model', 'called', 'bert', ',', 'which', 'stands', 'for', 'bidirectional', 'encoder', 'representations', 'from', 'transformers']
- len(first_sentence[0])
- # 18
-
-
- len(first_sentence[1])
- # 18
- first_token_in_first_sentence = first_sentence[1]
- first_token_in_first_sentence[1]
- # array([ 0.4805648 , 0.18369392, -0.28554988, ..., -0.01961522,
- # 1.0207764 , -0.67167974], dtype=float32)
- first_token_in_first_sentence[1].shape
- # (768,)


可用的预训练BERT模型
| book_corpus_wiki_en_uncased | book_corpus_wiki_en_cased | wiki_multilingual | wiki_multilingual_cased | wiki_cn | |
|---|---|---|---|---|---|
| bert_12_768_12 | ✓ | ✓ | ✓ | ✓ | ✓ |
| bert_24_1024_16 | x | ✓ | x | x | x |
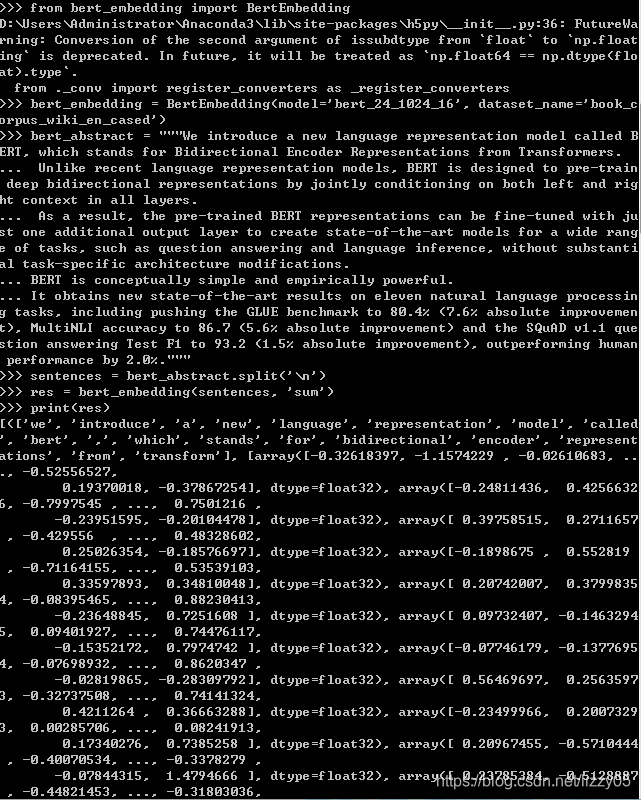
- from bert_embedding import BertEmbedding
-
- bert_embedding = BertEmbedding(model='bert_24_1024_16', dataset_name='book_corpus_wiki_en_cased')
下载了 1.35G的bert_24_1024_16_book_corpus_wiki_en_cased-4e685a96.params。
处理OOV(未识别词)有三种方法:avg (默认), sum, and last。
这里用的是sum来处理的OOV,即bert_embedding(sentences,'sum')。执行结果如下所示:
参考文献:
声明:本文内容由网友自发贡献,转载请注明出处:【wpsshop博客】
推荐阅读
相关标签

