
- 1初识鸿蒙跨平台开发框架ArkUI-X_鸿蒙开发平台
- 2[HTML]Web前端开发技术3(HTML5、CSS3、JavaScript )超链接,target,scrolling,marginwidth,frameborder,iframe——喵喵画网页
- 3C# Cad2016二次开发选择文本信息导出(六)
- 4数据库总结之高级篇_具体实现还是要看表选择的存储引擎
- 5Unity零基础到入门 ☀️| 游戏引擎 Unity 从0到1的 系统学习 路线【全面总结-建议收藏】!_unity学习路线
- 6《Linux从练气到飞升》No.21 Linux简单实现一个shell
- 7vue+face-api.js实现前端人脸识别功能
- 8MySQL练习《单表操作2》_在student表中查询年龄大于18的学生的所有信息
- 9关于“Python”的核心知识点整理大全45
- 10主机windows与虚拟机Ubuntu联动复制粘贴
机器学习小白修炼之路---多变量线性回归(回归问题)_回归问题的数据集
赞
踩
一、监督学习
给算法一个数据集,其中包含着正确的答案;
该算法的目的:输入一组数,给出更多预测的正确答案。
回归问题就是监督学习中的某个分支,本篇文章以斯坦福大学的吴老师所讲的房价预测为例,解释多变量线性回归模型。
二、多变量线性回归例子—房价预测
1、房价预测的处理流程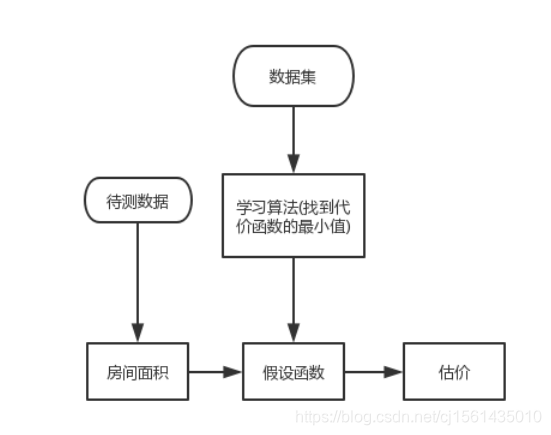
2、线性假设函数(也叫线性回归函数)

上面的图是视频上截图的,基本意思直接看下面的图吧:

最后的价格等于矩阵Xxtheta(列向量,就是权重),通常要把X矩阵的第一列置成1。因为一次函数的原型是f(X)=axX+b,如果我们要表示成上面形式的话,令x0等于1,等价于f(theta)=x0xtheta0+x1xtheta1(假设此时只有two variables)。
最后假设函数的公式就是hθ(X) = X x θ
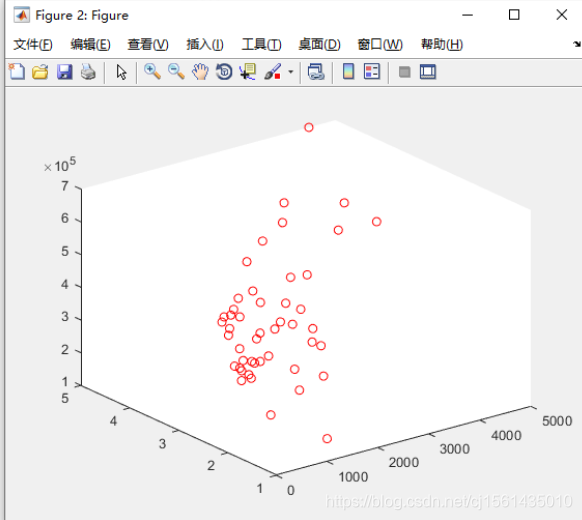
3、数据集下载
Matlab可视化文件中的47个点。
4、梯度下降(stimultaneously update every theta!)
多变量的假设函数(在本文也可以叫线性回归函数) ,用假设函数来模拟。下面要讲的梯度下降法和正则方程法都是试图找到一条直线,使所有样本到直线上的损失之和最小;
多变量的代价函数(这里用均方误差损失函数),用代价函数来表示误差值。打草稿的时候最后代价函数忘了平均了,忘记除以2m了。。。


手动求导:

5、Matlab实现
计算损失函数的m文件:
function result = cost_1_FunctionJ( x,y,theta )
m=length(x(:,1));
n=length(x(1,:));
prediction=x*theta; %预测值,这里的theta是列向量
sqrErrors=(prediction-y).^2; %方差
result=1/(2*m)*sum(sqrErrors);
end
- 1
- 2
- 3
- 4
- 5
- 6
- 7
梯度下降的m文件:
function destination = gradient_decline( X,y,theta ) alpha=0.01; i=1; iter=1000; m=length(X(:,1)); %样本数 J=zeros(1,iter); while i<iter, %注释是当theta为列向量时候的做法 %J(i)=cost_1_FunctionJ(X,y,theta); %offset=((X*theta-y)'*X)'; J(i)=cost_1_FunctionJ(X,y,theta'); offset=(X*theta'-y)'*X; theta=theta-1/m*alpha*offset; i=i+1; end; plot(1:iter,J); title('loss funciton'); destination=theta; end

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
线性回归demo,此处采用最标准的特征缩放。当然也可以采用简单的缩放,比如直接除以那一列特征值中的最大数。
function theta_new = line_regression( ) x=load('D:\machineLearning\线性回归模型\ex3Data\ex3x.dat'); y=load('D:\machineLearning\线性回归模型\ex3Data\ex3y.dat'); plot3(x(:,1), x(:,2), y, 'r*'); n=length(x(1,:)); m=length(x(:,1)); %样本数 %x(:,2)=x(:,2)./max(x(:,2)); 较为简单的特征缩放 直接除以某个特征值中的最大值 %x(:,3)=x(:,3)./max(x(:,3)); x(:,1)=(x(:,1)-mean(x(:,1)))./std(x(:,1)); %特征缩放 mean表示某个特征值中的平均值,std表示某个特征值中的标准差 x(:,2)=(x(:,2)-mean(x(:,2)))./std(x(:,2)); x=[ones(m,1), x]; %x0为1 %theta=[0;0;0]; %theta为列向量时候做出相应修改 theta=[0 0 0]; theta_new=gradient_decline(x,y,theta); end
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
最后在Matlab的实时脚本里面实现整个逻辑。


最后,这个误差值的数量级是非常大的,因为房价的都是百万为单位的,不是算法实现有问题。是data有问题。
第一次写博客,有点小激动!
6、正规方程
当X的转置矩阵和X矩阵乘积的矩阵不可逆的时候,Matlab里面用pinv()函数可以解决这个问题。不可逆问题的本质是矩阵的特征值有相同的,所以只要去掉重复的特征值,确保特征值不同,在对矩阵缩放也可以搞出来。



