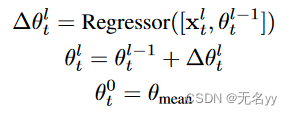- 1Centos/Ubuntu 替换yum/apt源?_ubuntu换yum源
- 2lvgl 移植 stm32F429_如何将lvgl粗略的移植到stm32f429上
- 3怎么关闭 Windows 安全中心,手动关闭 Windows Defender 教程_关闭windows defender安全中心
- 4探索PyMuPDF:Python中的强大PDF处理库_python pdf读取 哪个库好用
- 5【Windows】Antimalware Service Executable cpu占用过高_antimalware service占用率极高win11
- 6数据仓库、数据湖、流批一体,终于有大神讲清楚了!_请画出批式数仓架构、流式数仓架构、流批一体数仓架构、湖仓一体架构,并阐述主要
- 7【快速见刊|投稿优惠】2024年机电一体与自动化技术国际学术会议(IACMAT 2024)_international conference on measuring technology a
- 8Kafka常用运维操作命令_kafka常用的运维操作有哪些
- 9c语言编程在现实生活中,C语言编程的问题
- 10AI大模型能带来强人工智能吗 这是值得思考的问题_大模型是否就是强人工智能
3D人体姿态估计 & transformer_三维位姿估计 持续学习
赞
踩
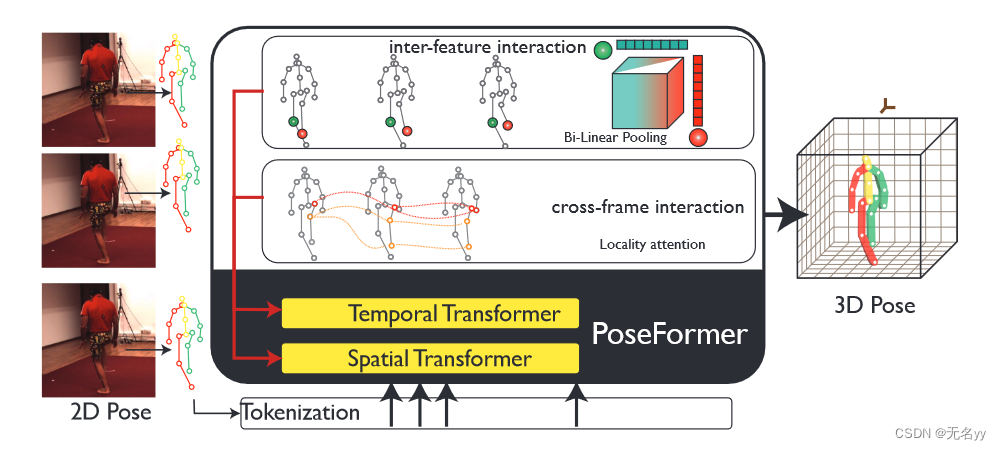
1.3D Human Pose Estimation with Spatial and Temporal Transformers(ICCV 2021)
想解决的问题:
①基于 CNN 的方法通常依赖于扩张技术,该技术本质上具有有限的时间连接性
②循环网络主要受限于简单的顺序相关性。
③将每一帧当做一个token忽略了关节之间的空间关系,然而将每个关节视作一个token时,当使用长序列的时候,token数量太多,内存要求太大(图示两种问题)
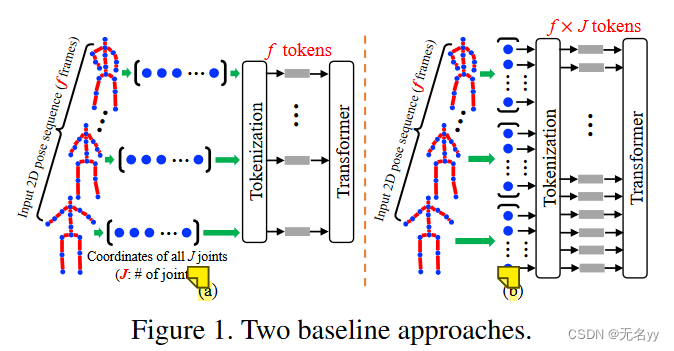
解决方法:
①PoseFormer使用两个维度不同的Transformer直接对空间和时间维度进行建模
贡献:
①我们提出了第一个基于纯 Transformer 的模型 PoseFormer,用于 2D 到 3D 提升类别下的 3D HPE。
②我们设计了一个有效的时空变换器模型,其中空间变换器模块对人体关节之间的局部关系进行编码,而时间变换器模块捕获整个序列中帧之间的全局依赖关系。
③没有花里胡哨的东西,我们的 PoseFormer 模型在 Human3.6M 和 MPI-INF-3DHP 数据集上都取得了最先进的结果。
网络架构:
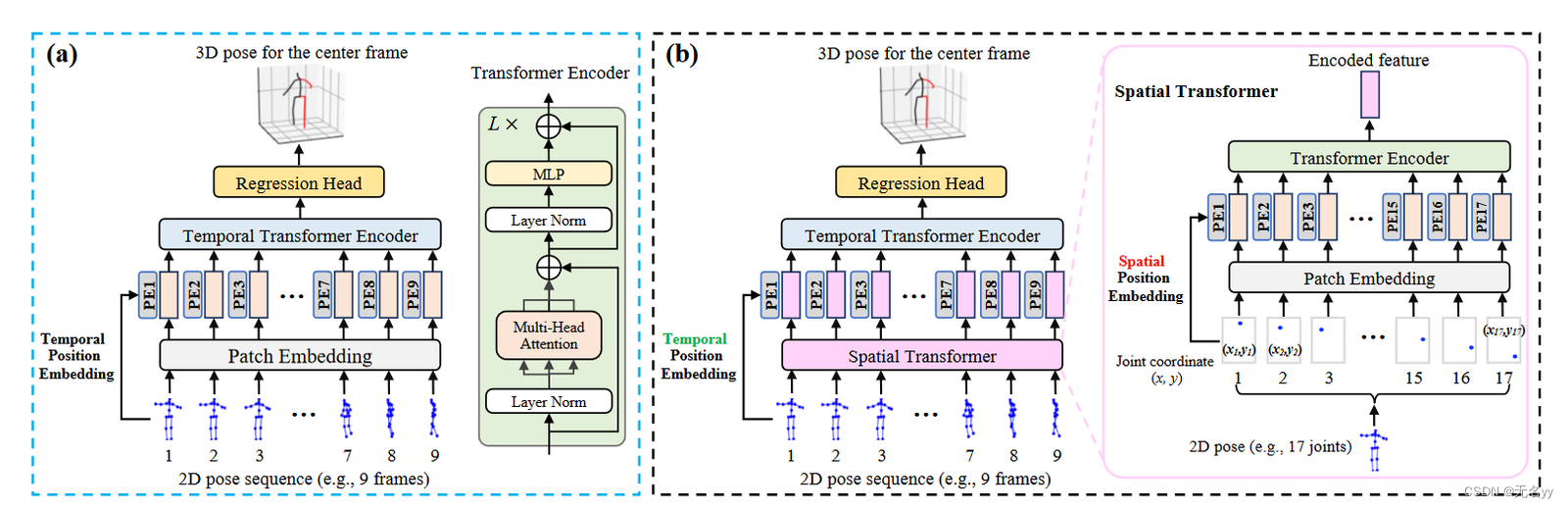
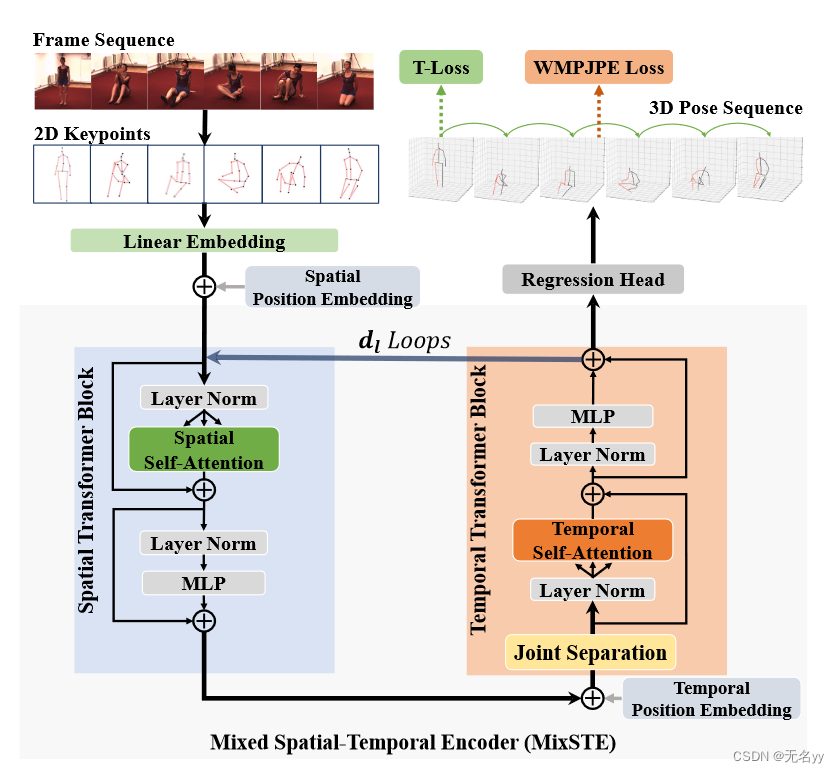
2.MixSTE: Seq2seq Mixed Spatio-Temporal Encoder for 3D Human Pose Estimation in Video(CVPR 2022)
想解决的问题:
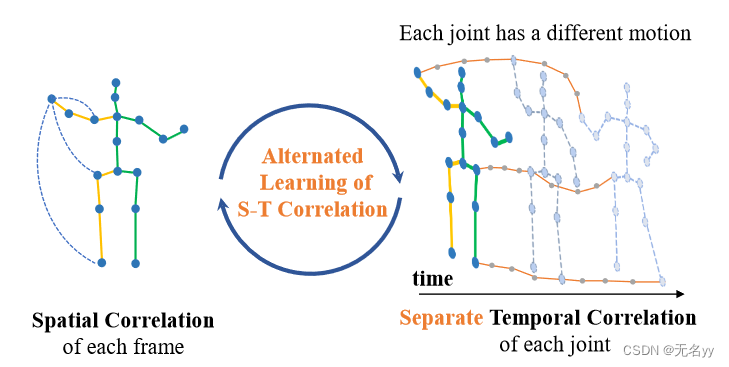
①PoseFormer忽视了关节之间的运动差异性,导致了时空相关性学习的不足,此外PoseFormer增加了时间Transformer模块的维度,这限制了较长输入序列的使用。
②将PoseFormer中将一段视频作为输入,而只输出中间一帧的方法叫做seq2frame,作者认为这种方法单帧输出会忽视序列一致性,此外,在推理过程中,这些 seq2frame 解决方案需要重复输入大重叠的 2D 关键点序列才能获得所有帧的 3D 位姿,这带来了冗余计算。
③当前的 seq2seq 网络(LSTM、GCN)缺乏输入和输出序列之间的全局建模能力,在长序列的输出姿势中往往过于平滑("过度平滑"指的是模型在生成长序列时倾向于生成过于平坦或过于简单的输出,导致丢失了一些细节或者变化。在自然语言处理中,这可能表现为生成的文本过于简单、缺乏变化,或者缺乏上下文的丰富性。这可能会导致生成的文本不够丰富生动,或者与真实语言的表达方式相比显得过于单调)。
解决方法:
①身体不同的关节点的运动轨迹因帧而异,因此需要单独学习
②提出seq2seq的交替设计,灵活地在长序列内获得更好的序列一致性,从而减少冗余计算和过度平滑
贡献:
①MixSTE被提出来有效地捕获长序列上不同身体关节的时间运动,这有助于建模足够的时空相关性。
②我们提出了一种基于 Transformer 的 seq2seq 模型的新颖交替设计,以学习序列之间的全局一致性,从而提高重建姿势的准确性。
③我们的方法在三个基准上实现了最先进的性能,并且具有出色的泛化能力。
网络架构:
3.Cross-Attention of Disentangled Modalities for 3D Human Mesh Recovery with Transformers(ECCV 2022)
想解决的问题:
①由于复杂的人体关节,一些任务(例如人体运动分析和人机交互)本质上具有挑战性,并且由于单目环境中的遮挡和深度模糊而变得更加困难。
②基于编码器的transformer 共享类似的 Transformer 编码器架构。他们将 K 个关节和 N 个顶点标记作为输入来估计 3D 人体关节和网格顶点,其中 K 和 N 分别表示 3D 人体网格中的关节和顶点数量。每个标记都是由全局图像特征向量 x ∈ RC 和人体网格中关节或顶点的 3D 坐标串联而成。这导致维度为 R(K+N)×(C+3) 的输入token被作为transformer编码器的输入。这种token设计引入了相同的性能瓶颈来源:1) 空间信息丢失全局图像特征x,以及2)以过度重复的方式使用相同的图像特征x。前者是通过平均池化操作获得全局图像特征x引起的。后者会导致相当低的效率,因为需要昂贵的计算来处理大部分重复的信息,其中独特的信息信号仅占输入token的 0.15%。
③
解决方法:
①相比之下,我们的 FastMETRO 不会连接图像特征向量来构建输入标记。我们通过编码器-解码器架构解开图像编码部分和mesh估计部分。我们的关节和顶点标记通过transformer解码器中的交叉注意模块专注于某些图像区域。
②为了有效捕获非局部关节顶点关系和局部顶点-顶点关系,我们根据人体三角形网格的拓扑屏蔽非相邻顶点的自注意力。
③为了避免人体mesh顶点的空间局部性引起的冗余,我们执行从coarse-to-fine的网格上采样。通过利用人体形态关系的先验知识,我们大大降低了优化难度。
贡献:
①我们提出 FastMETRO,它采用一种新颖的 Transformer 编码器-解码器架构,用于从单个图像恢复 3D 人体网格。我们的方法解决了基于编码器的变压器的性能瓶颈,并提高了Pareto-front的准确性和效率。
②通过降低优化难度,所提出的模型收敛速度更快。我们的 FastMETRO 利用人体形态关系的先验知识,例如,根据人体网格拓扑屏蔽注意力。
③我们展示 FastMETRO 的模型尺寸变体。小变体以更少的参数和更快的推理速度显示出有竞争力的结果。大变体在 Human3.6M 和 3DPW 数据集上明显优于现有的基于图像的方法,而且更轻量、更快
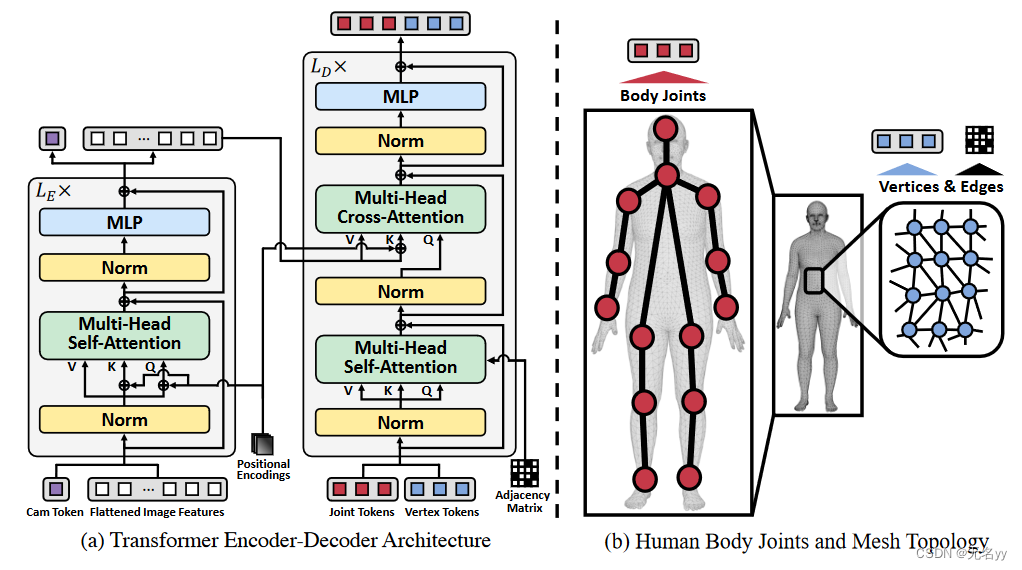
网络架构:
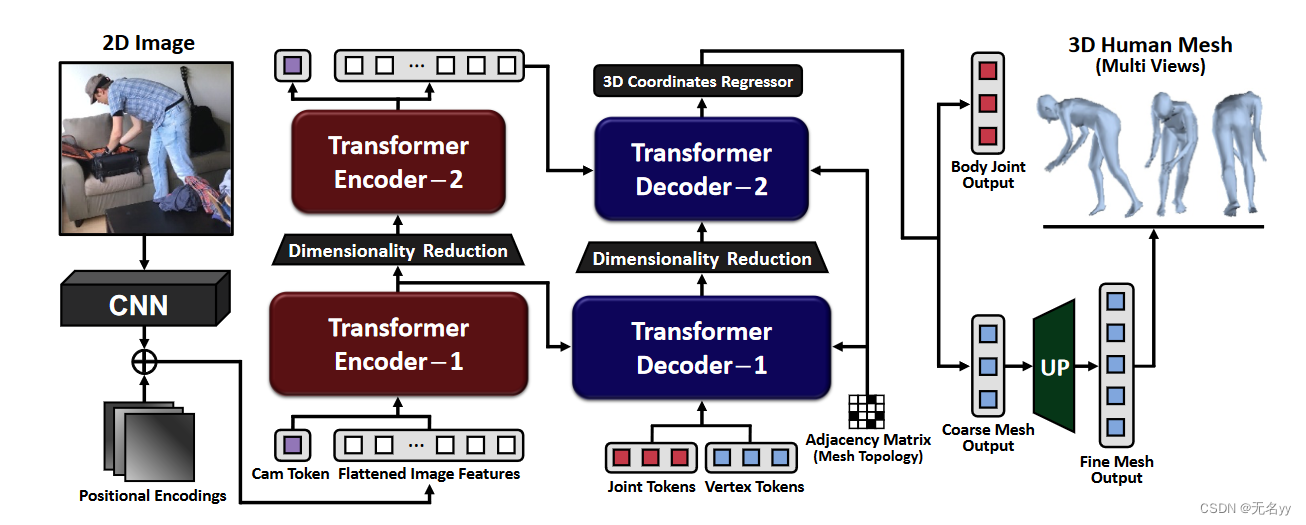
Feature Extractor:给一个图像,首先通过一个CNN backbone提取图像特征XI∈RH*W*C,然后过一个1D卷积层,减少特征维度,后拉伸图像特征为XF∈RHW*D。
Cam Token:相机token捕获基本特征,通过transformer中的注意力机制来预测弱视角相机参数;相机参数用于将 3D 估计人体mesh拟合到 2D 输入图像。给定相机标记和图像特征,transformer编码器产生相机特征和聚合图像特征 XA ∈ RHW ×D。
Transformer Decoder:除了输入来自编码器图像特征 XA 之外,还输入一组可学习的关节token和顶点token。给定图像特征和token,解码器通过自注意力和交叉注意力模块产生关节特征XJ∈RK*D,和顶点特征XV∈RN*D,
Attention Masking based on Mesh Topology:为了有效捕获局部顶点-顶点和非局部关节-顶点关系,我们根据人体三角形网格的拓扑结构屏蔽非相邻顶点的自注意力。
4.CrossFormer: Cross Spatio-Temporal Transformer for 3D Human Pose Estimation(2022)
想解决的问题:
①2D 到 3D 姿势回归是一个未确定的问题,其中许多 3D 姿势可能对应于几乎相同的二维投影。在这种情况下,即使关节位置和外观最轻微的变化也可以提供信息。
②尽管PoseFormer在HPE领域取得了巨大的成功,其核心是ViT,但ViT具有较差的局限性,这个问题体现在注意力模块关注所有token上
解决方法:
①为了解决上述问题,我们建议集成局部性和丰富的特征间交互(如下图),同时保留原始 PoseFormer 的关键优势(即处理大量令牌的能力和空间)时间建模。
②为了捕获突出潜在微弱但有效细节的丰富特征, 我们通过修改进一步将双线性池集成到局部注意模块中:使用外积来计算注意力中的交叉项。因此,将注意力扩展到所有通道(与跨通道维度合并信息的原始内积不同)。
③受非局部神经网络的启发,我们选择局部注意力来利用跨帧关节的特征表示。
④跨关节交互(CJI)模块被插入 Transformer 架构的空间编码器中,以对框架内身体部位之间的运动学约束进行编码。除了跨关节交互模块之外,我们还提出了跨框架交互(CFI)模块来处理跨框架的关节之间的交互。
贡献:
①用于空间变换器架构的跨关节交互模块 CJI,用于编码身体关节之间的运动依赖性,同时考虑每个关节的局部连接。
②用于时间转换器架构的跨框架交互模块 CFI,用于捕获跨框架的身体关节之间的显式相关性。
③在两个流行的基准数据集上实现了最先进的性能; Human3.6 和 MPI-INF-3DHP。
网络架构:
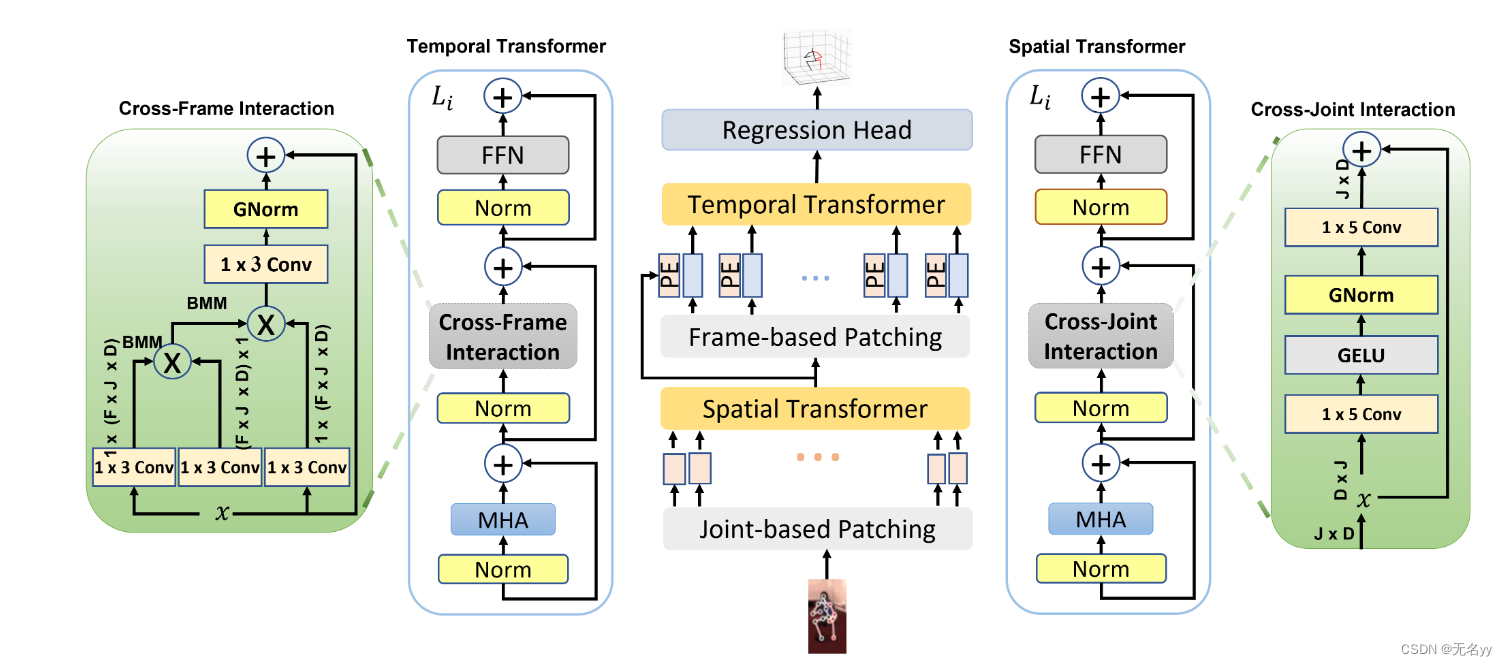
CJI:每个关节的2D坐标首先使用线性操作进行转换,然后计算自我注意力分数,这种操作忽视了低分关系,因为Transformer的非局部特性
- 让 Transformer 考虑人体部位的局部性及其局部相互作用,就像编码其非局部相互作用(即远程依赖性)一样
- 显式编码身体部位关节之间的相互作用跨通道,这丰富了注意力分数较低的关节的表示。
CFI:时间编码器中的全部注意力基于通道之间的依赖性(即 Rf×(J×D)),其中帧之间的显式交互被忽略。根据 SoftMax 计算产生的分数,分数较低的关节可能会在此过程中被忽略。例如,部分可见或遮挡的关节将无法在 3D 空间中正确表示和反映
使用双线性池操作,而不是传统的 SoftMax 显式编码跨帧的相同关节之间的关系。这有助于明确学习通道之间的相关性,并反映输出空间的运动学约束。
5.Exploiting Temporal Contexts with Strided Transformer for 3D Human Pose Estimation(IEEE Transactions on Multimedia 25 2022)
想解决的问题:
①尽管 2D 到 3D 提升方法受益于 2D 位姿检测器的可靠性能,但由于深度固有的模糊性,它仍然是一个高度不适定的问题,因为多个 3D 解释可以投影到相同的 2D 位姿图像空间。
②使用多帧图像来辅助预测中间帧的3D姿态的时候,其输入的帧中的2D姿态存在大量冗余,即动作在相邻帧中变化不大(如下图)

③预测单帧的3D姿态可能会破坏视频帧之间的时间平滑性,而且在一堆输入序列帧无法明确指定要学习的是哪一帧的3D姿态
解决方法:
①我们建议逐渐合并附近的姿势以缩小序列长度,直到获得目标姿势的一种表示。
②我们建议用跨步卷积替换 FFN 中的全连接层,以逐步减少序列长度。
③因此,基于VTE和STE的输出,在全尺度和单尺度上设计了全对单监督方案,该方案可以在全序列尺度上施加额外的时间平滑度约束,并在单目标帧尺度上细化估计。
贡献:
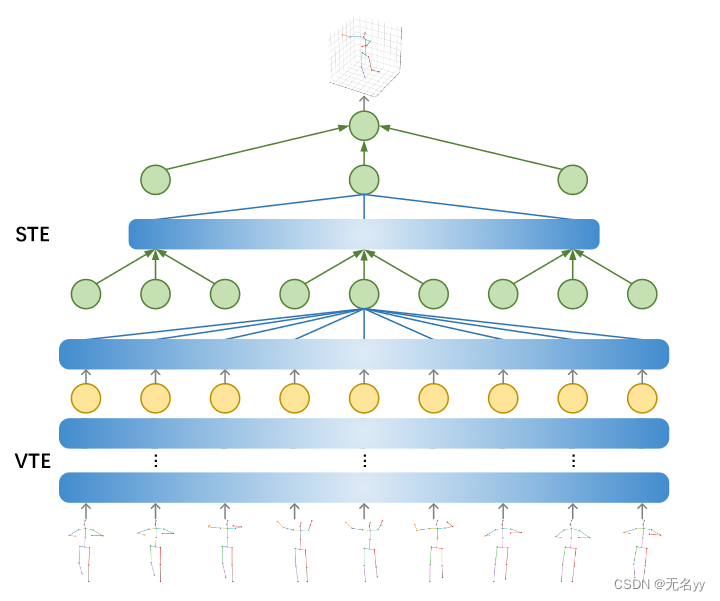
①我们提出了一种新的基于 Transformer 的 3D 人体姿势估计架构,称为 Strided Transformer,它可以简单有效地将长 2D 姿势序列提升为单个 3D 姿势。
②为了减少序列冗余和计算成本,引入了跨步变换编码器(STE)来逐渐降低时间维度,并将远程信息以分层全局和局部方式聚合成姿势序列的单向量表示。
③设计了全到单监督方案,以在全序列尺度的训练期间施加额外的时间平滑度约束,并进一步细化单目标帧尺度的估计
④在两个常用的基准数据集上使用更少的参数即可实现最先进的结果,使我们的方法成为基于 Transformer 的 3D 姿态估计的强大基线。
网络架构:
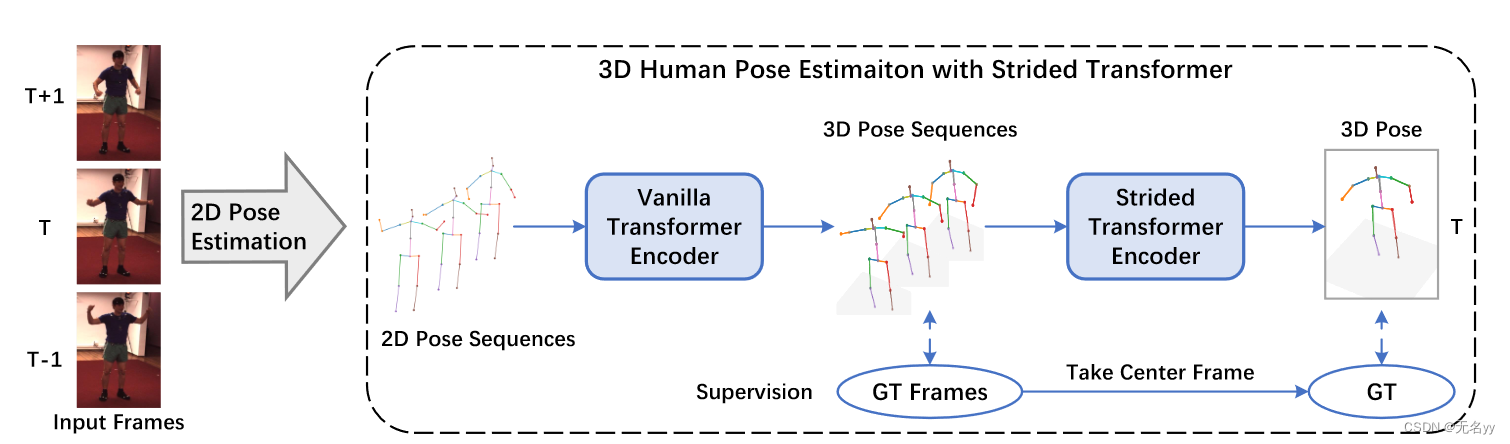
该网络首先通过 VTE 对远程信息进行建模,然后将信息聚合成来自所提出的 STE 的一个目标姿态表示。该模型在全序列和单目标帧尺度上进行端到端训练
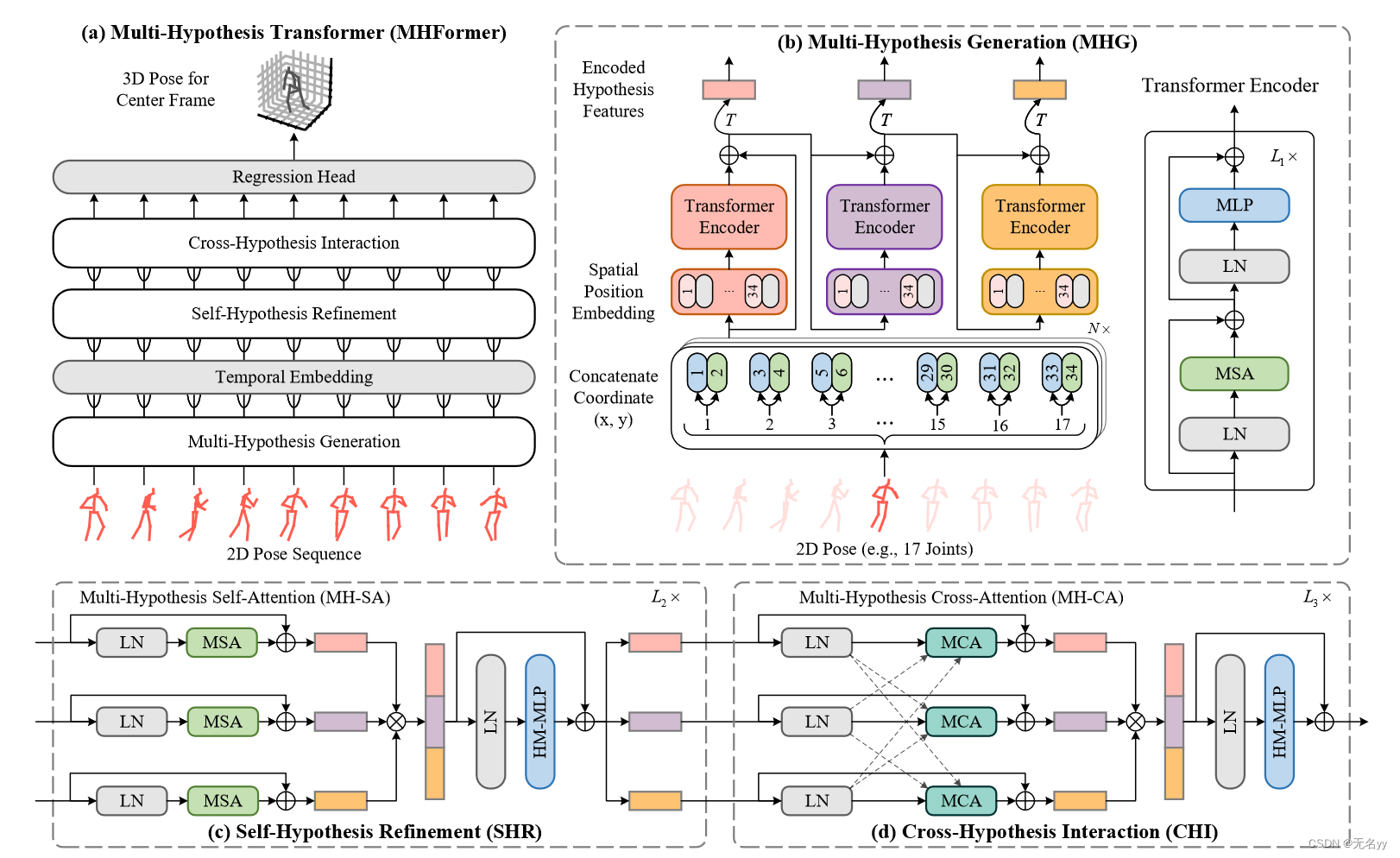
6.MHFormer: Multi-Hypothesis Transformer for 3D Human Pose Estimation(CVPR 2022)
想解决的问题:
①从单目视频的 2D 到 3D 提升是一个逆问题 ,其中由于缺失深度 的不适定性质,存在多个可行的解决方案(即假设)。这些方法忽略了这个问题,只估计单个解决方案,这通常会导致结果不令人满意,特别是当人被严重遮挡时。
②目前产生多个假设的方法通常依靠一对多映射,通过将多个输出头添加到具有共享特征提取器的现有架构中,而无法建立不同假设的特征之间的关系。
解决方法:
①我们认为首先进行一对多映射,然后使用各种中间假设进行多对一映射更为合理,因为这种方式可以丰富特征的多样性并为最终的3D姿势产生更好的合成。
②具体来说,在第一阶段,构建Multi-Hypothesis Generation(MHG)模块来对人体关节的内在结构信息进行建模,并在空间域中生成多个多层次特征。这些特征包含从浅到深不同深度的不同语义信息,因此可以被视为多个假设的初始表示。在第二阶段,提出了Self-Hypothesis Refinement(SHR)模块来细化每个单一假设特征。尽管这些假设经过 SHR 的细化,但不同假设之间的联系不够强。为了解决这个问题,在最后阶段,Cross-Hypothesis Interaction(CHI)模块对多假设特征之间的交互进行建模。(如下图)
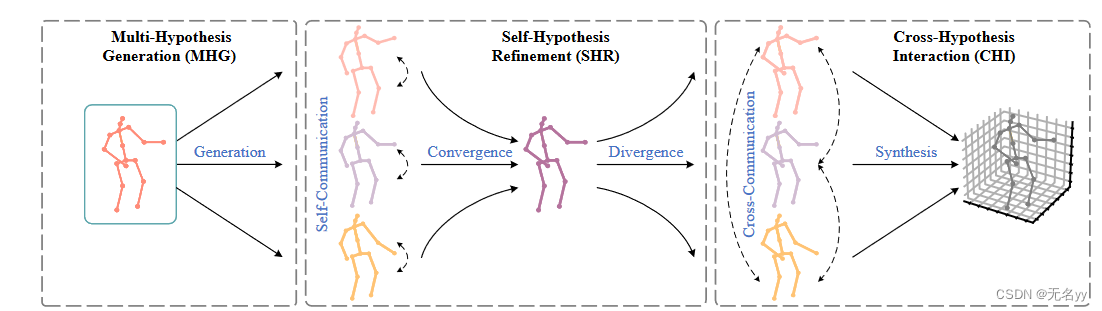
贡献:
①我们提出了一种基于 Transformer 的新方法,称为多假设 Transformer (MHFormer),用于单目视频的 3D HPE。 MHFormer 可以以端到端的方式有效地学习多个姿势假设的时空表示。
②我们建议在多假设特征之间独立和相互进行通信,提供强大的自假设和跨假设消息传递,以及假设之间的牢固关系。
③我们的 MHFormer 在 3D HPE 的两个具有挑战性的数据集上实现了最先进的性能,显着优于 PoseFormer 3%,在 Human3.6M 上误差减少了 1.3 mm。
网络架构:
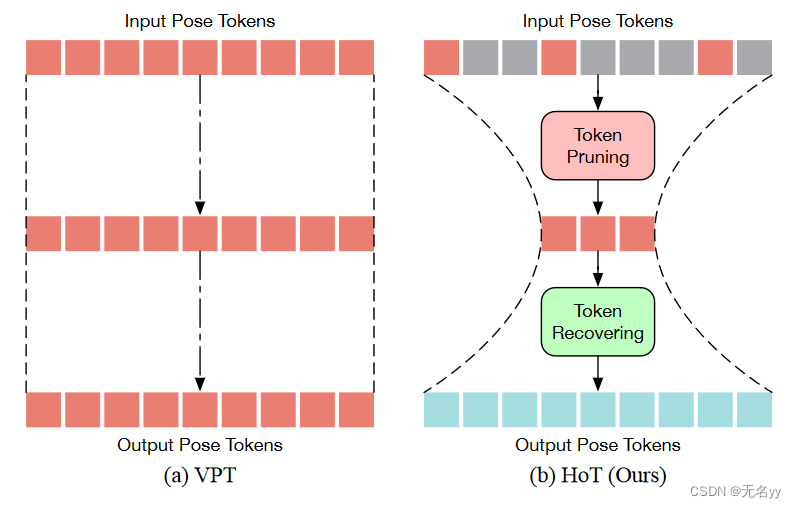
7.Hourglass Tokenizer for Efficient Transformer-Based 3D Human Pose Estimation(CVPR 2024)
想解决的问题:
①这些视频姿势变换器 (VPT) 通常将每个视频帧视为姿势标记,并利用极长的视频序列来实现卓越的性能,这些方法不可避免地会受到高计算要求的影响,因为 VPT 的自注意力复杂度随着token(即帧)的数量呈二次方增长,从而阻碍了这些重型 VPT 在计算资源有限的设备上的部署
②直接减少帧数可以提高VPT的效率,但会导致时间感受野较小,限制了模型捕获更丰富的时空信息以提高性能
③由于附近姿势的相似性,视频序列中的相邻帧包含冗余信息。
解决方法:
①与维持所有块的全长序列的现有 VPT 不同,我们的方法从修剪冗余帧的姿态标记开始,到恢复全长标记结束。通过使用这两种设计,我们可以在中间Transformer块中仅保留少量令牌,从而提高模型效率(如下图)
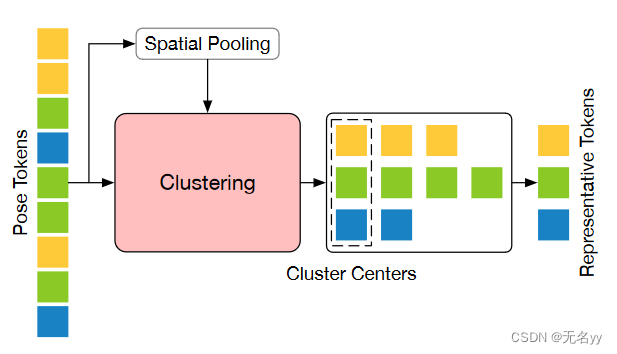
②由于聚类中心可以保留原始信号的语义多样性,因此我们提出了一种token pruning cluster(TPC)模块,该模块利用聚类动态选择聚类中心作为代表token。此外,我们开发了一个轻量级的token recovering attention(TRA)模块,用于根据所选token恢复详细的时空信息,将剪枝操作引起的低时间分辨率扩展到全时间分辨率。该策略使网络能够估计所有帧的连续 3D 姿态,从而有利于快速推理。
③我们的方法可以轻松集成到现有的 VPT 中,只需进行最少的修改。来自 TRA 的附加参数和 FLOP 可以忽略不计。由于token的数量首先通过剪枝减少,然后通过恢复增加,因此我们将该框架称为沙漏,并将其命名为Hourglass Tokenizer(HoT)。
贡献:
①我们推出了 HoT,这是一种即插即用的修剪和恢复框架,用于从视频中高效地实现基于 Transformer 的 3D HPE。我们的 HoT 揭示了维护全长姿势序列是多余的,并且代表帧的一些姿势标记可以实现高效率和性能。
②为了有效加速 VPT,我们提出了一个 TPC 模块来选择一些代表性令牌来减少视频冗余,并提出一个 TRA 模块来恢复原始时间分辨率以进行快速推理。
③在最近的三个 VPT 上进行的大量实验表明,HoT 在显着提高效率的同时取得了极具竞争力甚至优越的结果。
网络架构:
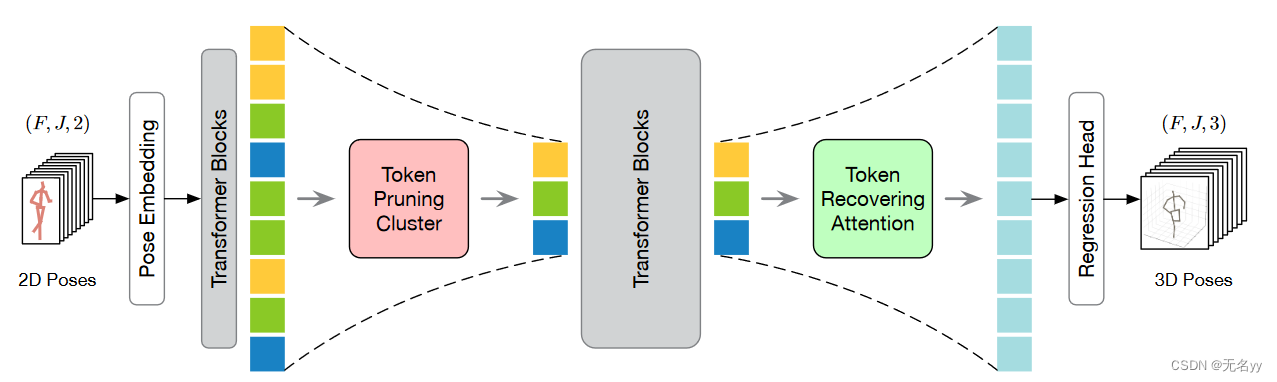
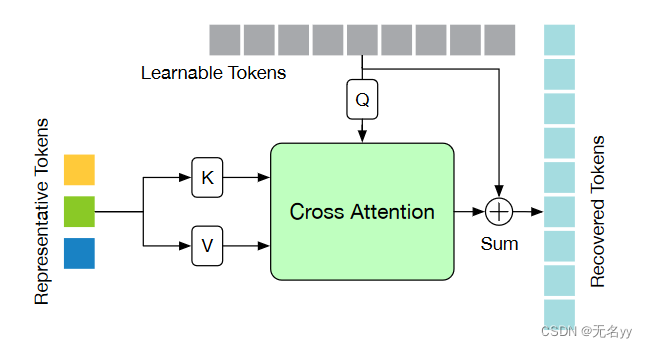
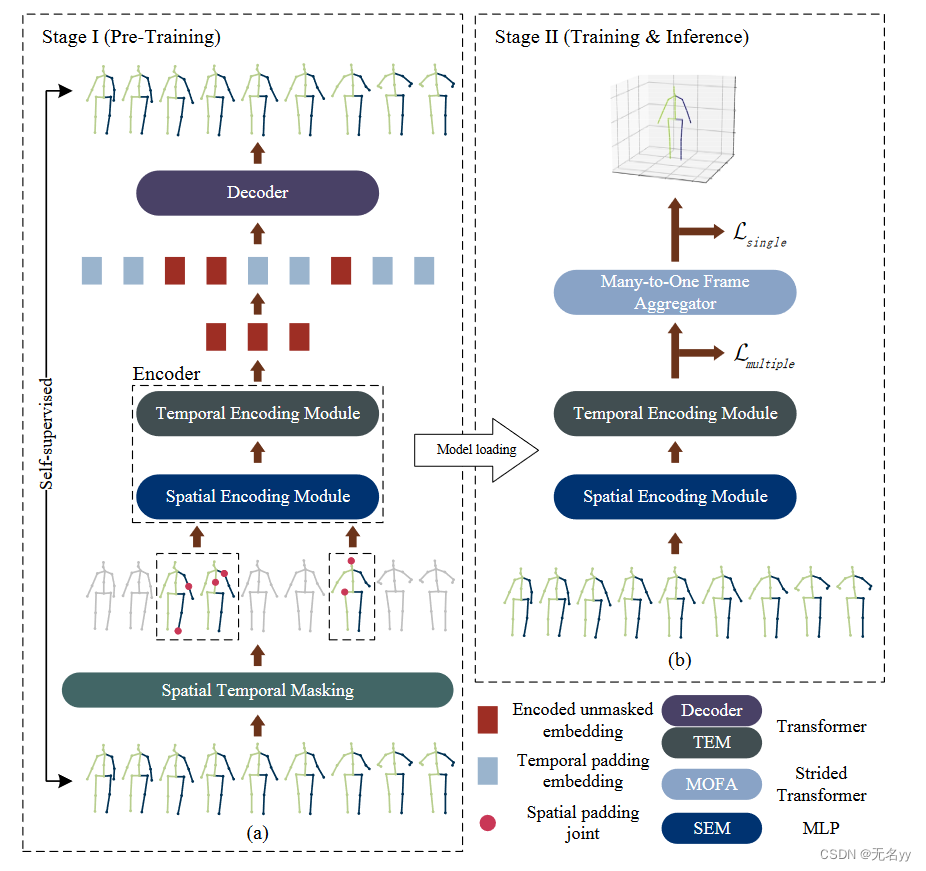
8.P-STMO: Pre-Trained Spatial Temporal Many-to-One Model for 3D Human Pose Estimation(ECCV 2022)
想解决的问题:
①利用 Transformer 的自注意力机制来描述每个帧中关节之间的空间依赖性或序列中帧之间的时间依赖性。然而,这些方法有两个缺点:(1)它们直接学习 2D 到 3D 的空间和时间相关性,这是一项具有挑战性的任务。这可能会使优化模型变得困难。 (2)之前的工作表明Transformer比卷积神经网络需要更多的训练数据。
解决方法:
①对于这两个问题,Transformer 的自监督预训练是一种很有前途的解决方案,它已被证明在自然语言处理(NLP)和计算机视觉(CV)方面是有效的。先前的方法随机屏蔽一部分输入数据,然后恢复屏蔽的内容。通过这种方式,模型能够表示数据中的固有特征。因此,我们有动力利用自监督预训练方法进行 3D 人体姿态估计。
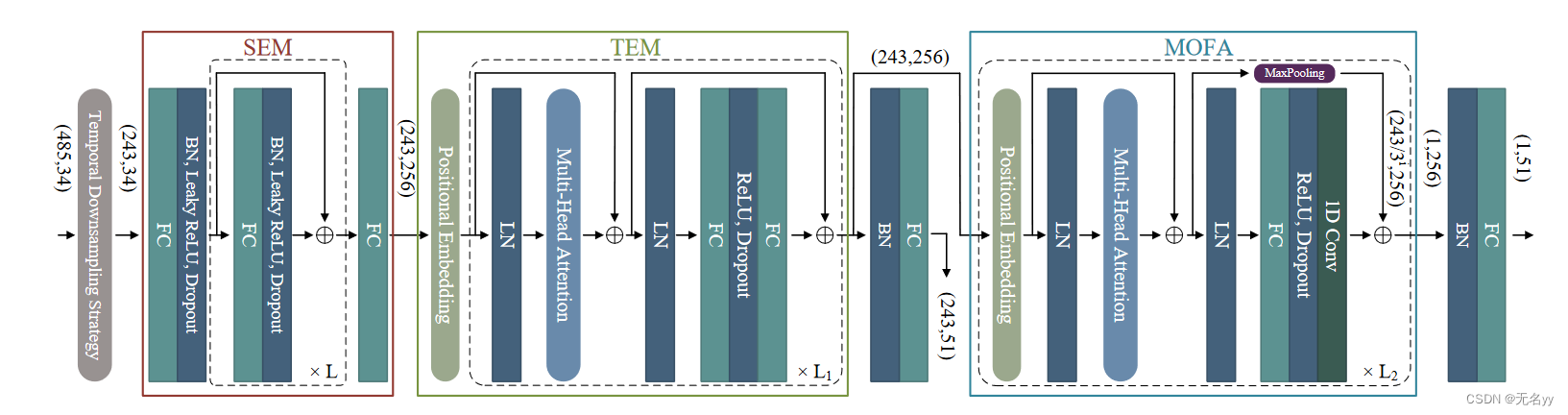
②在本文中,我们提出了一种用于 2D 到 3D 人体姿态估计的Pre-trained Spatial Temporal Many-to-One (P-STMO) 模型。整个过程分为两个阶段:pre-training(第一阶段)和fine-tuning(第二阶段)。在第一阶段,我们随机屏蔽了一些帧(时间上)以及剩余帧中的一些2D关节(空间上)。此阶段的模型是去噪自动编码器的通用形式,旨在重建损坏的二维姿势。这为网络提供了有利的初始化。在第二阶段,预训练的编码器与多对一帧聚合器相结合,通过使用 2D 姿势序列作为输入来重新训练来预测当前(中间)帧的 3D 姿势。通过这种两阶段策略,编码器应该在第一阶段捕获 2D 时空依赖性,并在第二阶段提取 3D 空间和时间特征。

贡献:
①据我们所知,P-STMO 是第一个将预训练技术引入 3D 人体姿态估计的方法。预训练任务,以自监督的方式提出,以更好地捕获空间和时间依赖性。
②所提出的 STMO 模型简化了每个模块的职责,因此显着降低了优化难度。 MLP 块被用作 SEM 的有效空间特征提取器。此外,还采用时间下采样策略来缓解 TEM 的数据冗余问题。
③与其他方法相比,我们的方法以更少的参数和更小的计算预算在两个基准上实现了最先进的性能。
网络框架:
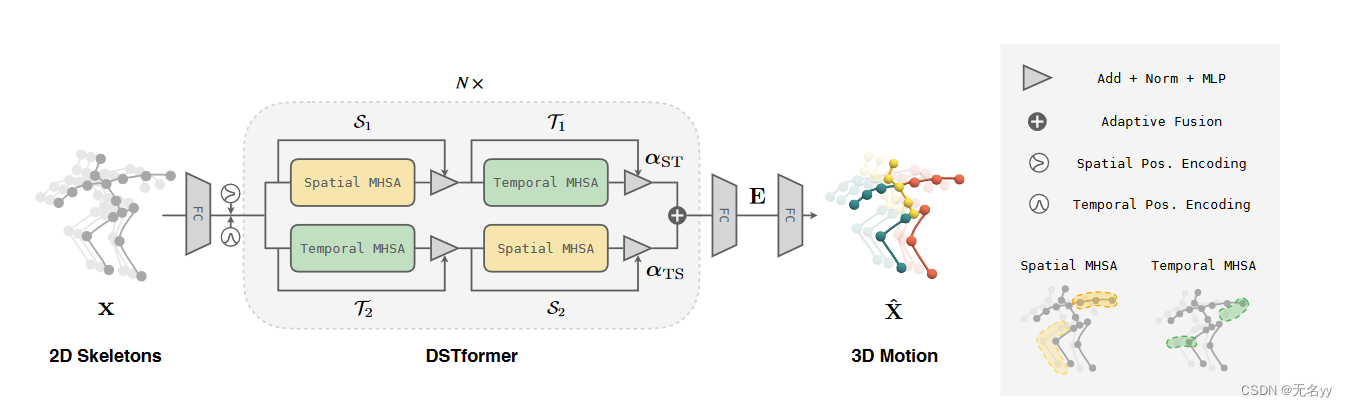
9.MotionBERT: A Unified Perspective on Learning Human Motion Representations(ICCV 2023)
想解决的问题:
①感知和理解人类活动一直是机器智能的核心追求。为此,研究者们定义了各种任务来从视频中估计人体运动的语义标签,例如骨骼关键点、行为类别、三维表面网格等。尽管现有的工作在这些任务上已经取得了显著的进步,但它们往往被建模为孤立的任务。理想情况下,我们可以构建一个统一的以人为中心的运动表征,其可以在所有相关的下游任务中共享。
②构建这种表征的一个重要挑战是人体运动数据资源的异质性。运动捕捉(MoCap)系统提供了基于标记和传感器的高精度 3D 运动数据,但其内容通常被限制在简单的室内场景。动作识别数据集提供了动作语义的标注,但它们要么不包含人体姿态标签,要么只有日常活动的有限动作类别。具备外观和动作多样性的非受限人类视频可以从互联网大量获取,但获取精确的姿势标注需要额外的努力,且获取准确真实(GT)的三维人体姿态几乎是不可能的。因此,大多数现有的研究都致力于使用单一类型的人体运动数据解决某一特定任务,而无法受益于其他数据资源的特性
③
解决方法:
①我们提出了一个包括预训练和微调两个阶段的框架,如下图所示。在预训练阶段,我们从多样化的运动数据源中提取 2D 关键点序列,并添加随机掩码和噪声。随后,我们训练运动编码器从损坏的 2D 关键点中恢复 3D 运动。这个具有挑战性的代理任务本质上要求运动编码器(i)从时序运动中推断出潜在的 3D 人体结构;(ii)恢复错误和缺失的数据。通过这种方式,运动编码器隐式地学习到人体运动的常识,如关节拓扑,生理限制和时间动态。在实践中,我们提出双流空间-时间变换器(DSTformer)作为运动编码器来捕获骨骼关键点之间的长距离关系。我们假设,从大规模和多样化的数据资源中学习到的运动表征可以在不同的下游任务之间共享,并有利于它们的性能。因此,对于每个下游任务,我们仅需要微调预训练的运动表征以及一个简单的回归头网络(1-2层 MLP)。
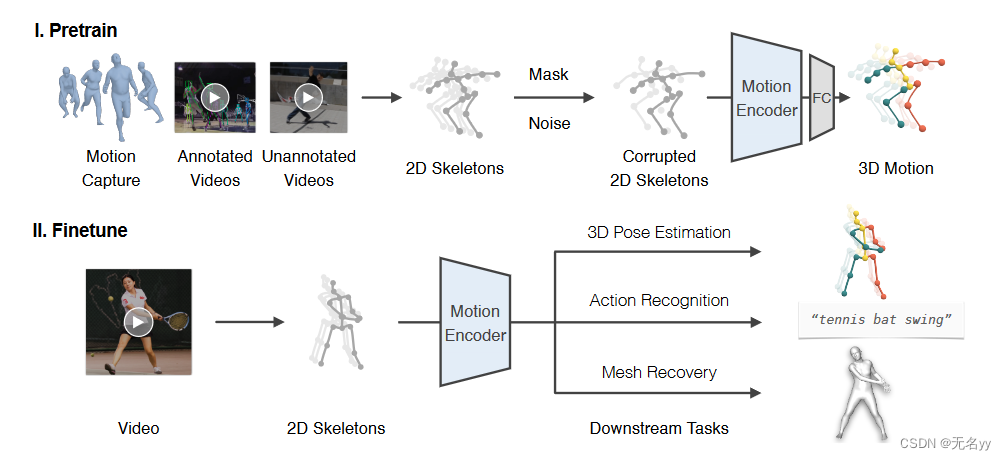
② 在设计统一的预训练框架时,我们面临两个关键挑战:1)如何构建合适的代理任务(pretext task)学习的运动表征;2) 如何使用大规模但异质的人体运动数据。针对第一个挑战,我们遵循了语言和视觉建模的成功实践来构建监督信号,即遮蔽输入的一部分,并使用编码的表征来重构整个输入。我们注意到这种“完形填空”任务在人体运动分析中自然存在,即从 2D 视觉观察中恢复丢失的深度信息,也就是 3D 人体姿态估计。受此启发,我们利用大规模的 3D 运动捕捉数据,设计了一个 2D 至 3D 提升(2D-to-3D lifting)的代理任务。我们首先通过正交投影 3D 运动来提取 2D 骨架序列 x。然后,我们通过随机遮蔽和添加噪声来破坏 x,从而产生破坏的 2D 骨架序列,这也类似于 2D 检测结果,因为它包含遮挡、检测失败和错误。在此之后,我们使用运动编码器来获得运动表征并重建 3D 运动。对于第二个挑战,我们注意到 2D 骨架可以作为一种通用的中介,因为它们可以从各种运动数据源中提取。因此,可以进一步将 RGB 视频纳入到 2D 到 3D 提升框架以进行统一训练。对于 RGB 视频,2D 骨架可以通过手动标注或 2D 姿态估计器给出。由于这一部分数据缺少三维姿态真值(GT),我们使用加权的二维重投影误差作为监督。
③
贡献:
①我们通过学习人体运动表示的共享框架提供了解决各种以人为中心的视频任务的新视角。
②我们提出了一种预训练方法来利用大规模但异构的人体运动资源并学习可泛化的人体运动表示。我们的方法可以同时利用 3D 动作捕捉数据的精度和野外 RGB 视频的多样性。
③我们设计了一个具有级联时空自注意力块的双流 Transformer 网络,可以作为人体运动建模的通用骨干。实验表明,上述设计实现了多功能的人体运动表示,可以转移到多个下游任务,优于特定于任务的最先进方法。
网络框架:
10Pose-Oriented Transformer with Uncertainty-Guided Refinement for 2D-to-3D Human Pose Estimation(Proceedings of the AAAI Conference on Artificial Intelligence 2023)
想解决的问题:
①2D-3D pipeline受到从多个 3D 姿势到同一个 2D 投影的多对一映射导致的深度模糊性的限制。考虑到人体可以建模为高度结构化的图,可以通过利用身体关节之间的相互作用来缓解深度模糊问题。图卷积网络(GCN)已被自然地采用来利用这些相互作用,然而GCN 通常受到感受野的限制,阻碍了关系建模
②受到 Transformer 成功的启发,最近的工作中利用了自注意力机制以促进 3D HPE 的全球交互并产生最先进的性能。然而,这些方法将身体关节视为同等重要的输入标记,但在设计自注意力机制时忽略了人体先验(例如人体骨骼拓扑)。
③
解决方法:
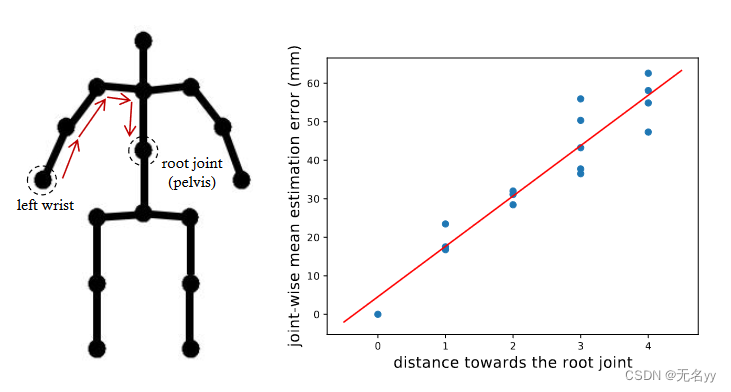
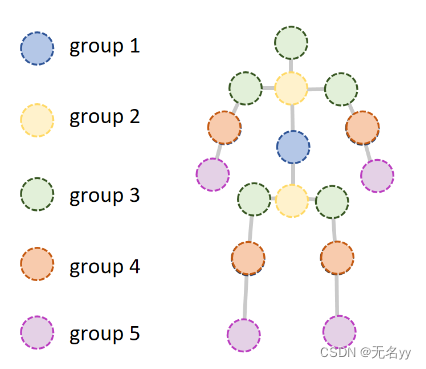
①计算每个关节对的相对距离,并将其作为注意偏差编码到自注意机制中,以增强对人体骨骼依赖性进行建模的能力。此外,如下图所示,我们凭经验发现远离根关节(骨盆)的关节往往具有较大的预测误差。为了更好地建模这些困难的关节,我们根据身体关节到根关节的距离将其分成几组,并将额外的与距离相关的位置嵌入分配给不同的组。
②我们还开发了第二阶段的姿势细化,以进一步改进困难关节的预测。具体来说,我们提出了一种基于Transformer的Uncertainty-Guided Refinement Network(UGRN),通过明确考虑预测不确定性来进行姿态细化。所提出的 UGRN 包括不确定性引导采样策略和不确定性引导自注意力(UG-SA)机制。不确定性引导采样策略将每个关节的估计不确定性(这意味着预测的难度)纳入学习过程。
贡献:
①我们提出了一种用于 3D HPE 的新颖的面向姿势的变压器,具有明确设计用于利用人体骨骼拓扑的自注意力和位置嵌入机制。
②我们提出了一种不确定性引导的细化网络,通过不确定性引导的采样策略和自注意力机制进一步改进困难关节的姿态预测。
③我们展示了我们的方法在 Human3.6M 和 MPI-INF-3DHP 基准上实现了 SOTA 性能,并阐明了用于单帧输入人体姿态估计的面向任务的变压器设计。
网络框架:
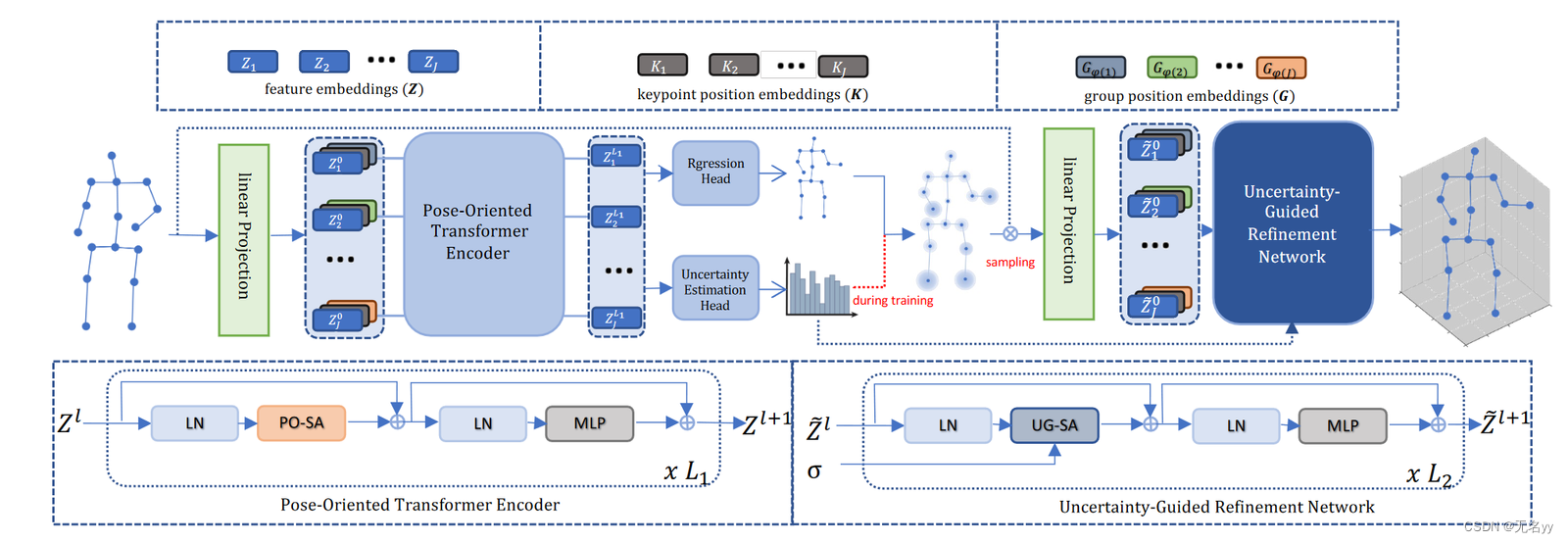
1)Linear Projection:对输入的2D关节点坐标x∈RJ*2投影到高维特征空间Z∈RJ*C,然后添加关键点位置嵌入 K(表示每个身体关节的绝对位置) 和我们提出的组位置嵌入 G 到 Z 作为 POT 编码器的输入。因此,额外的与距离相关的知识可以被编码到模型中,帮助 Transformer 更好地建模远离根部的困难身体关节。这样,面向位姿的Transformer编码器的输入Z(0)可以通过以下方式获得:
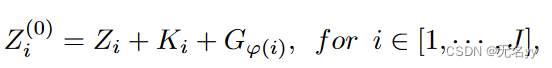
其中 i 是关节索引,φ(i) = D(i, 1) 表示第 i 个关节到根关节之间的最短路径距离。
2)PO-SA:我们计算每个关节对 (i, j) 的相对距离,并将其编码为自注意力机制的注意力偏差。这样,我们重写了自注意力,其中注意力矩阵A的第(i,j)个元素可以通过以下方式计算:
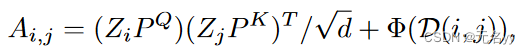
其中Φ是MLP网络,它将相对距离(一维)投影到H维向量
3)Uncertainty Estimation Head:POT 编码器 ZL1 的特征被发送到另一个不确定性估计头,通过使用不确定性估计损失 Lσ 产生第一阶段 3D 位姿的不确定性 σ ∈ RJ×32222
4)Uncertainty-Guided Sampling:我们没有直接利用第一阶段的 3D 预测Y,而是根据高斯分布 N(Y , σ) 围绕Y 随机采样 3D 坐标y ,并将预测的不确定性 σ 作为方差,并将采样的坐标发送到 UGRN 。这种不确定性引导采样策略确保采样的坐标在困难关节上有较大的方差,这要求模型更多地专注于利用其他关节的上下文来补偿困难关节预测,从而进一步增强模型的鲁棒性。
5)Uncertainty-guided Refinement Network:获得采样的 3D 位姿y后,我们首先将其与输入的 2D 位姿x连接起来,得到X,即X= Concat(y , X)。然后我们将 X 投射到特征嵌入 Z 上,并为它们配备关键点位置嵌入 K 和组位置嵌入 G,接下来,Z被发送到 UGRN 的后续 L2 变换层以执行不确定性引导的细化。 UGRN 的变换层与 POT 的变换层类似,但我们替换了公式中与距离相关的项。用不确定性指导来动态调整注意力权重:
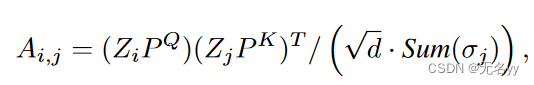
其中 σj ∈ R3 是第 j 个关节的预测不确定性。上述不确定性引导自注意力(UG-SA)保证了具有高不确定性的身体关节在自注意力机制中的贡献较小,这不仅可以减轻误差传播,还可以增强模型的上下文理解能力。
11.PoseBERT: A Generic Transformer Module for Temporal 3D Human Modeling(IEEE Transactions on Pattern Analysis and Machine Intelligence 2022)
想解决的问题:
①训练野外人体姿势估计模型时的一个主要挑战是数据:收集大量带有真实 3D 注释的训练图像非常麻烦,缺乏带有 3D 注释的真实世界数据对于视频而言更为重要,使得使用时间的模型变得困难,例如 Transformer ,众所周知,这些模型需要大量数据集进行训练。
②当前基于视频的人体姿势估计方法依赖于相当小的视频数据集上的弱(2D 姿势)和/或伪 3D 地面实况注释。
解决方法:
①广泛应用于视频游戏和电影行业的动作捕捉 (MoCap) 提供了一种解决方案,可以创建具有精确地面实况 3D 姿势的大型运动序列库。最近,其中几个 MoCap 数据集已使用 SMPL 统一到大型 AMASS 数据集中,SMPL 是一种可微参数化人体网格模型,用于多种最先进的人体网格恢复方法 。使用大规模 MoCap 数据进行基于视频的人体姿势估计主要集中于提高估计的 3D 姿势序列的真实感 。
②我们使用类似于 BERT 的掩模建模来学习 PoseBERT 的参数,并最终得到一个通用且高度通用的模块,无需对许多任务和数据集以及全身或仅手部姿势序列进行微调即可使用该模块造型。特别是,PoseBERT 可以插入任何最先进的基于图像的姿势估计模型之上,以便将其转换为利用时间信息的基于视频的模型。
贡献:
①我们引入了 PoseBERT,这是一种基于 Transformer 的模块,用于单目 RGB 视频的姿势序列建模,无需任何繁琐的 RGB 图像或帧姿势注释即可进行训练。相反,我们利用 MoCap 数据进行训练,相比之下,这种方式相对容易获取,并且大规模 MoCap 数据集已经可用。我们的方法适用于人体和手部建模;事实上,它可用于任何存在 3D 参数化模型且可使用 MoCap 数据对其进行训练的用例。
②我们通过掩码建模学习 PoseBERT 参数,最终得到一个通用的、独立于任务的模型,可以开箱即用,即无需对许多下游任务进行微调,例如去噪姿势序列、恢复缺失序列中的姿势,精炼 3D 中的初始姿势序列、运动完成或未来帧预测。 PoseBERT 是即插即用的,独立于用于提取输入姿势的基于帧的方法,并且可以轻松处理丢失预测的帧。
③我们在大量下游任务和数据集上广泛评估了具有不同输入类型的 PoseBERT 的许多变体,从 3D 骨架关键点到身体 (SMPL) 或手 (MANO) 的 3D 参数化模型的旋转。一些亮点是:a) 无论采用基于图像的现成方法作为输入,PoseBERT 始终能够提高姿态细化的性能,在 PA-MPJPE 中的改进范围为 1.0 到 10.3 点; b) 与强基线相比,对于 5 到 30 帧的未来视野,PoseBERT 为未来姿态预测任务带来了 10% 到 50% 的相对增益。我们的方法可以预测未来 1 秒内可能出现的未来姿势
④我们对所提出的模块及其训练策略进行了广泛的消融,并进行了许多分析,包括对丢失帧和运动完成的研究。
⑤PoseBERT 的计算成本较低,这使我们能够以在线方式实时(30 fps)使用该时间模型,而前向传递大约需要 5 毫秒。在基于图像的标准方法之上添加 PoseBERT 会在 FLOP 方面增加 10% 的计算开销,同时带来稳健的运动恢复。
网络框架:
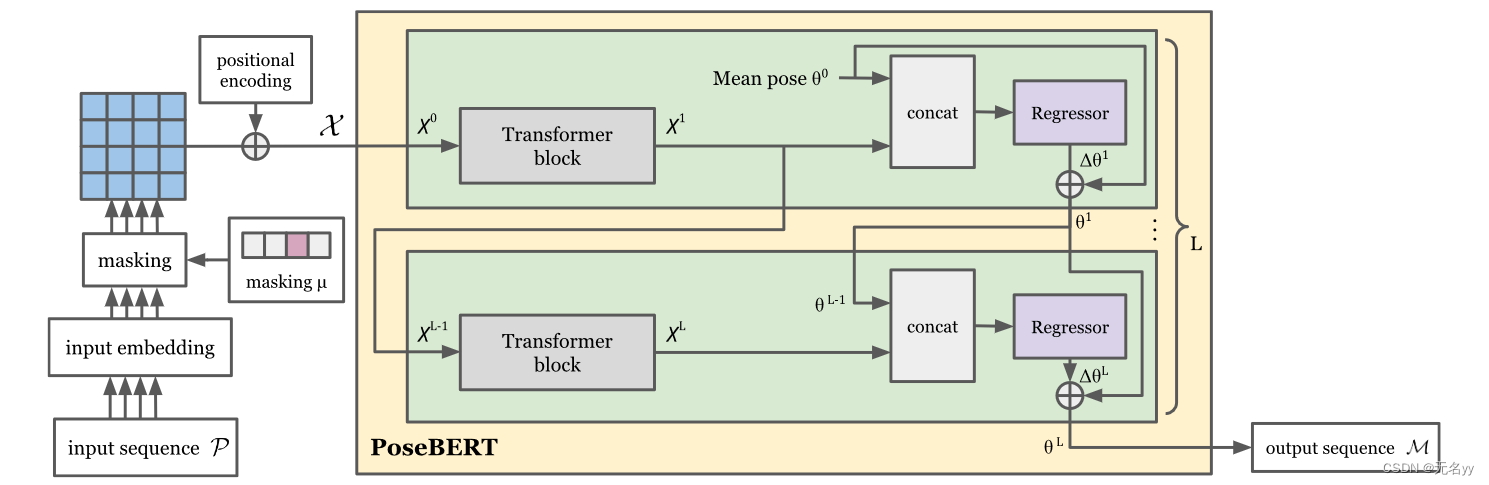
1)masking μ:是一个二进制向量,指示该时间步的姿态是可用还是丢失。
2)Iterative pose regression:3D 位姿参数 θ 的估计是针对每个时间步独立完成的,并以迭代方式进行。具体来说,令 θt = θLt 表示时间步长 t 的最终姿态估计,即在 PoseBERT 的最后一层 L。在每一层 l = 1, .., L 并给出前一层 θl−1t 的估计,回归器模块使用以下映射更新姿态估计: