
- 1Windows下安装Hadoop
- 2Python学习笔记之NumPy模块——超详细(安装、数组创建、正态分布、索引和切片、数组的复制、维度修改、拼接、分割...)_numpy怎么安装
- 3linux |离线安装软件 | rpm命令_rpm离线安装包
- 42023年阿里云服务器搭建网站流程新手全攻略(详细图文教程)_购买了阿里云服务器 想做网站
- 5Mac 如何打开 root 权限,如何删除系统软件
- 6代码随想录算法训练营Day24
- 7qt使用NIDAQmx实现电压采集,结合QChart实现波形显示_daqmx 高低电频
- 8Spark数据倾斜解决方法_spark数据倾斜的解决方法 distinct
- 9ip地址是电脑的还是网络的_网站记录的ip是电脑ip还是网络ip
- 10LeetCode 329. 矩阵中的最长递增路径(dp)_给定一个m n整数矩阵matrix
Transformer 从attention到grouped query attention (GQA)_flash attention如何实现gqa计算
赞
踩
Attention原理和理解
attention原理参考:
Attention Is All You Need
The Illustrated Transformer – Jay Alammar – Visualizing machine learning one concept at a time.
Attention首先对输入x张量乘以WQ, WK, WV得到query, key, value张量。
然后进行attention计算:
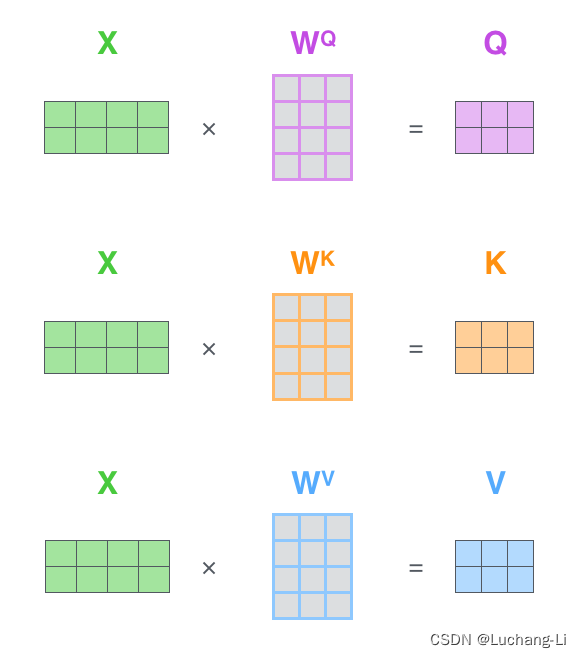
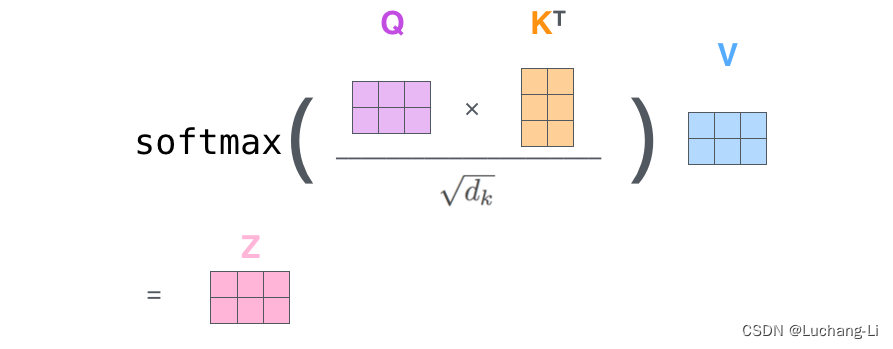
这里怎么理解query和key, value张量的含义,可以参考:
Transformer中K 、Q、V的设置以及为什么不能使用同一个值
https://prasad-jayanti.medium.com/what-is-query-key-value-qkv-attention-3b8f9eb15124
transformer中QKV的通俗理解(渣男与备胎的故事)-CSDN博客
Q,K,V是由输入的词向量x经过线性变换得到的,其中各个矩阵W可以经过学习得到, 这种变换可以提升模型的拟合能力, 得到的Q,K,V 可以理解为
Q: 要查询的信息
K: 被查询的向量
V: 查询得到的值
通俗的讲(个人理解),query可以认为是N个输入元素的期望值,key是M个"数据库"元素的实际值,value是M个数据库元素的属性。attention第一部分,首先用N输入元素的期望值跟M个数据库元素的实际值进行内积操作,得到[N, M]的相似度矩阵,这里面包含了每一个输入元素与数据库元素的相似度评价指标。然后第二部分,用[N, M]的相似度矩阵与[M, hidden]的属性张量做内积,这里实际上是用相似度作为权重,对M个数据库元素的属性做了一次加权求和,结果为加权平均的属性值。
这里我用"数据库"只是一种说明方式,并不是指真的数据库。比如LLM decoding阶段,N=1为当前输入的token,而数据库元素则为之前已经生成的所有token。
位置编码只添加到了query和key张量,而没有添加到value张量。可以认为位置编码主要是用来根据位置信息辅助获取输入元素和数据库元素的相似度计算。
Multi-head attention

注意力函数以某种方式量化了句子中任意两个标记之间的依赖关系/关系。由于这两个标记可以具有多种类型的关系——芒果和苹果不仅可以食用,而且它们都长在树上!这种逻辑激发了多头注意力的出现,而多头注意力是许多大型语言模型所基于的 Transformer 架构的核心。
multi-head就是在上面普通attention的基础上采用多组独立的attention计算,即原来是普通的矩阵乘,现在扩展到了batch矩阵乘。每一个batch是一个head。希望每一个head能够进行一种不同特征属性的attention计算。
Grouped query attention (GQA)
Ref:
GQA: Training Generalized Multi-Query Transformer Models from Multi-Head Checkpoints
这篇文章介绍了GQA的概念和好处:
Multi-query attention (MQA), which only uses a single key-value head, drastically speeds up decoder inference. However, MQA can lead to quality degradation
grouped-query attention (GQA), a generalization of multi-query attention which uses an intermediate (more than one, less than number of query heads) number of key-value heads. We show that uptrained GQA achieves quality close to multi-head attention with comparable speed to MQA.
multi-head attention (MHA) can be uptrained (Komatsuzaki et al., 2022) to use MQA with a small fraction of original training compute. This presents a cost-effective method to obtain fast multi-query as well as high-quality MHA checkpoints.
GQA achieves quality close to multihead attention (MHA) while being almost as fast as multiquery attention(MQA).
也就是GQA精度与MHA相近,但是推理速度更好与MQA相近。

在理解了上面的multi-head attention后理解GQA是非常容易的:multi-head attention基础上,query的head数量没有变化,还是num_attention_heads,但是把key和value相邻的几个(例如4个)head合并成了一个,数量变为num_key_value_heads,这样相当于几个query的head共享一个key和value的head。
下图是llama3 8b的GQA Q K V矩阵乘的计算,可以看到query的hidden是key和value的4倍,最终reshape和transpose后的head分别是32和8,每个head的hidden size是128.
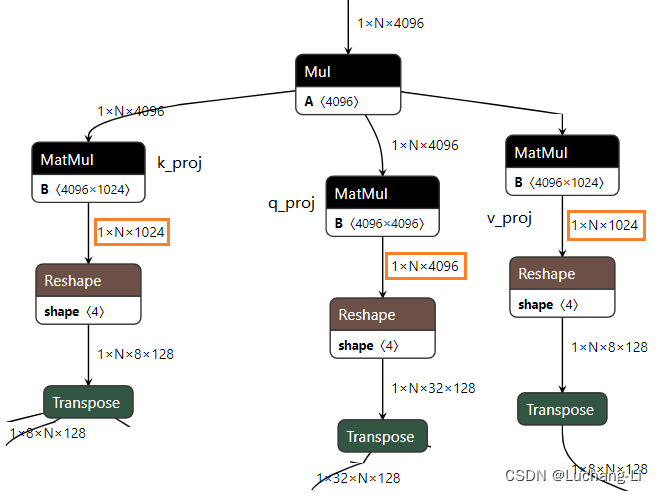
attention部分的onnx计算图(flash attention相当于把如下子图attention计算相关的算子融合为了一个算子):
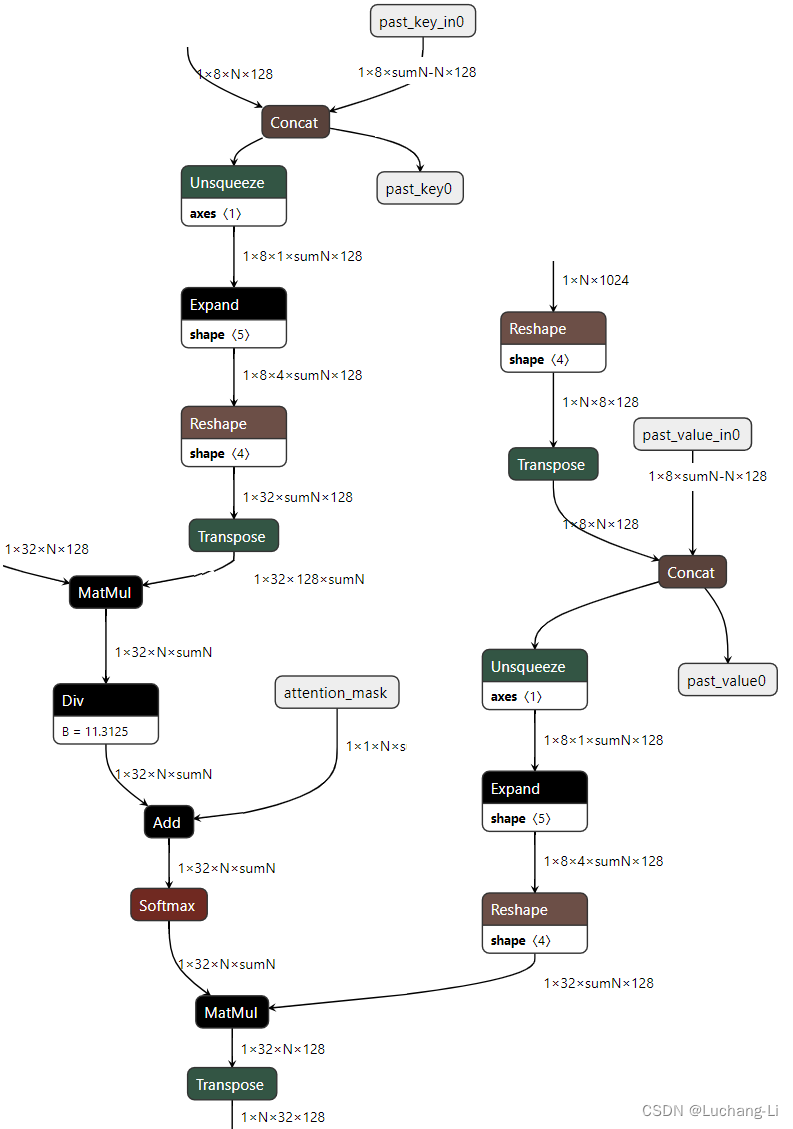
导出的onnx对key, value进行了expand,使得它们的head数与query一致,从而无法利用GQA的优势。当然实际上expand是没有必要的,因为matmul算子的batch本来是支持elemwise的broadcast规则的,也就是[1,32,N,128]reshape为[1,8,4,sumN,128]再与[1,8,1,sumN,128]直接矩阵乘即可,无需expand后者。
Flash attention的实现直接支持了GQA的场景,无需expand,从而利用到GQA的优势,llama3具有相关的实现。
从上面的计算图可以看到,GQA使得attention计算的key, value张量head数变为了原来的几分之一,从而有助于降低attention计算的访存量,但计算量并没有变。并且KV cache的大小也降低为了原来的几分之一,模型推理的内存使用因此也显著降低了。

