
- 1【Python】pip 使用方法详解_pythonpip怎么用
- 2Ubuntu22.04 lgh Ethercat master安装笔记_ubuntu igh
- 3MATLAB1:运行基础与入门练习
- 4深入了解SSM框架(案例(SSM+Jsp) + 详细分析 + 思维导图)
- 5基于Java+Vue+uniapp微信小程序火锅店点餐系统设计和实现_排队点餐系统设计
- 6指代消解or共指消解任务主要论文_bert-ner 指代消解
- 7FPGA应用实验设计(一)_四舍五入判别电路 fpga
- 8gitlab 吃内存。调整gitlab配置_gitlab 内存
- 9使用 YOLO 进行对象检测:保姆级动手教程_yolo怎么进行检测
- 10UI自动化控制微信发送文件【解决了一个无人回答的难题,Pywin32设置文件到剪切板】_flaui微信自动化demo_python flaui
【大数据 Hadoop zookeeper】基于azure云服务器的hadoop HA高可用性集群搭建_微软云数据库 ha怎么做
赞
踩
**## 前言:
windows Azure提供了学生认证,通过学生认证后,每年可以免费使用100刀以内的相关云服务。笔者建议大家都可以去申请一个学生优惠认证,感兴趣可以搜索一下。
下面的教程是笔者学生认证后搭建hadoop集群的全过程。
服务器搭建:
首先进入https://portal.azure.com/官网,选择创建资源
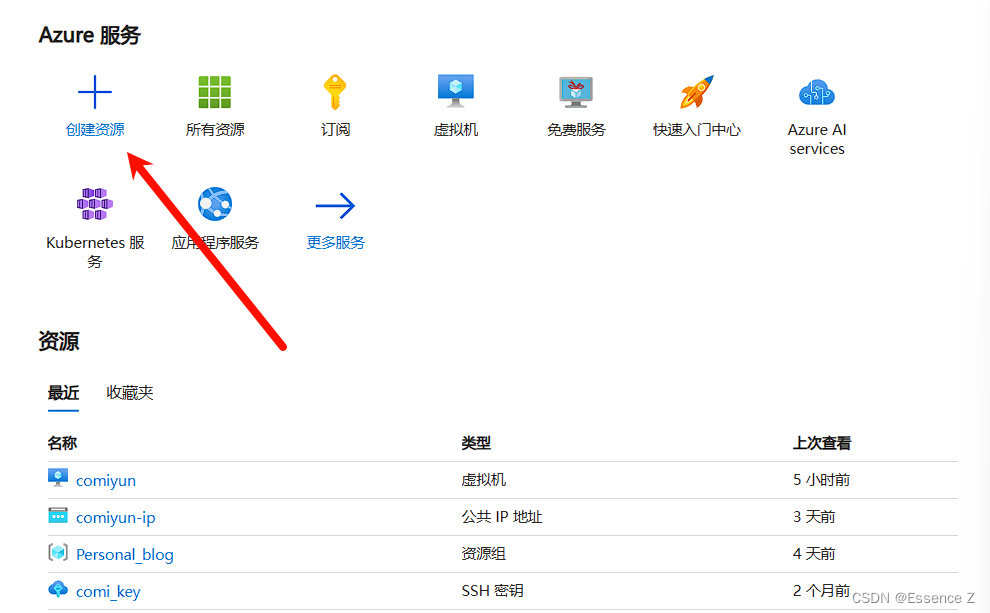
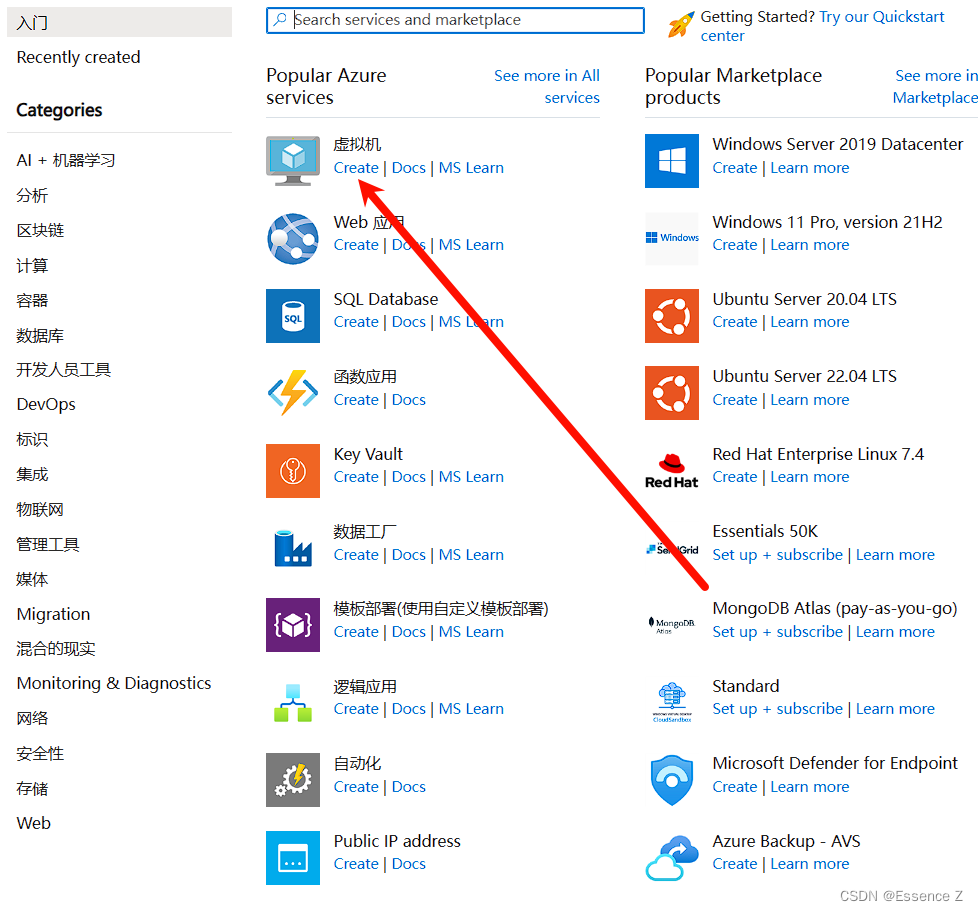
选择虚拟机,点击create:
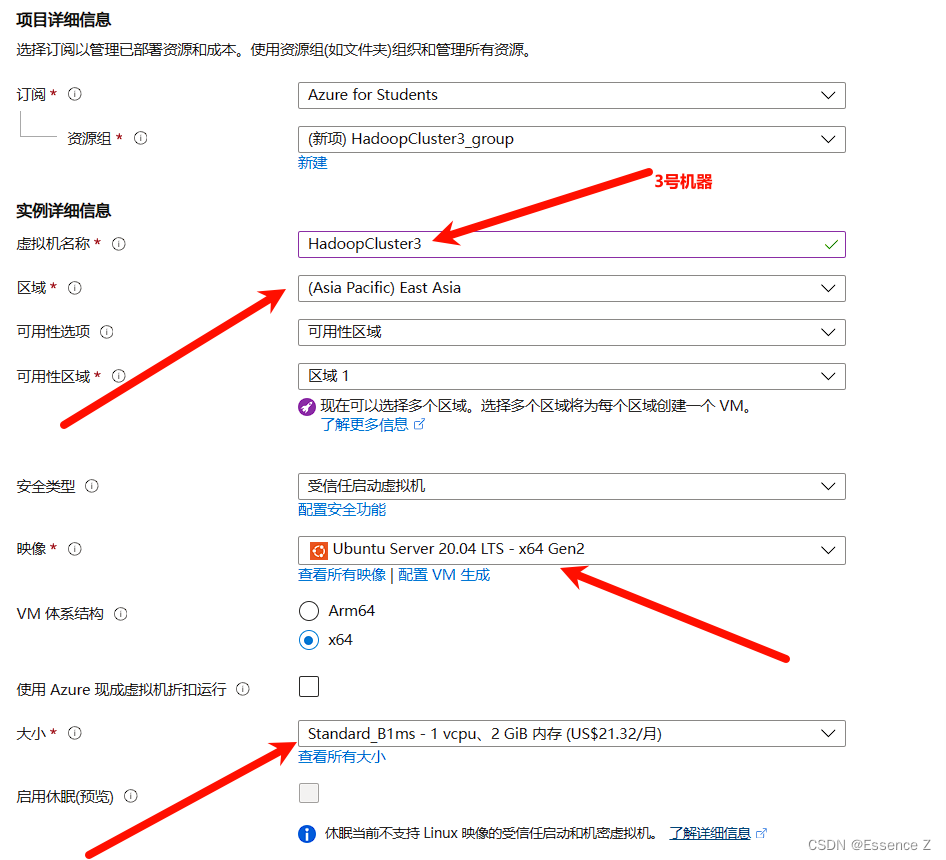
按照笔者配置修改以下内容,新建资源组,区域选择east asia,选择ubuntu系统,大小规格选择1vcpu 2gb(ps:由于每台服务器每个月收费20刀,我们的免费额度只够一个月多点,所以请大家按需停止或终止。)
创建管理员账号“:

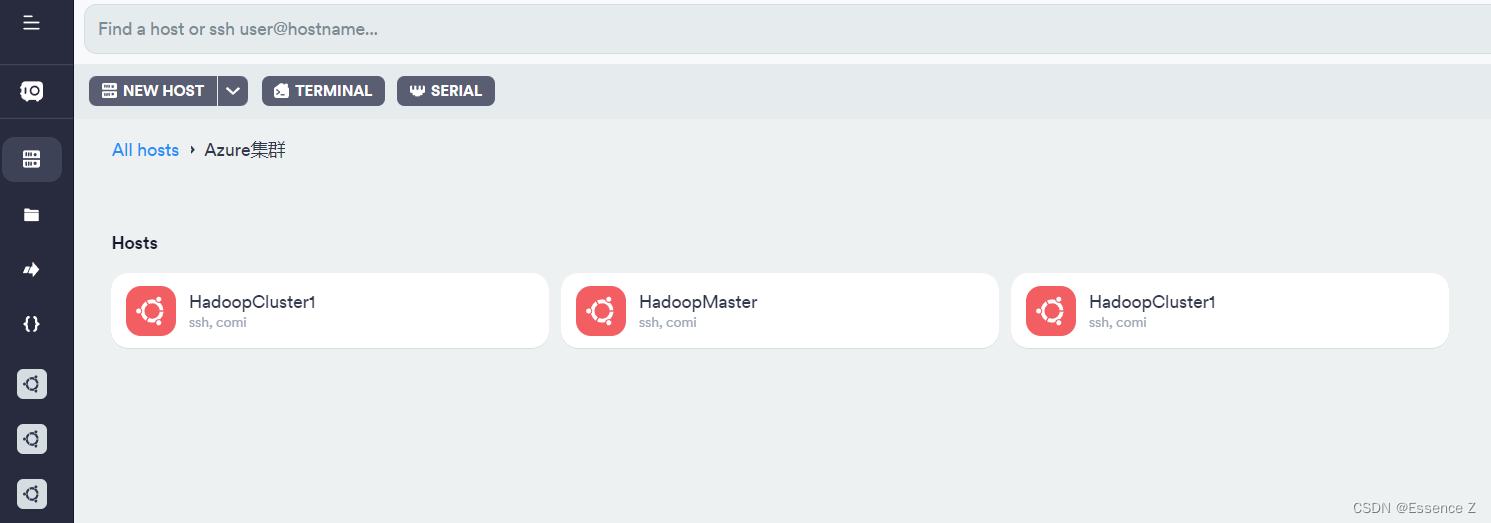
按以上教程创建3台虚拟机,主机:HadoopMaster,从机:HadoopCluster1,HadoopCluster2,记录每一台的ip地址(这里也可以新建一个虚拟网络,将创建的VM实例加入到该网络中,方便管理)

服务器申请好后如下:

hadoop环境搭建:
集群规划:
| 命名 | 功能 |
|---|---|
| hadoop1 | Namenode |
| hadoop2 | Datanode |
| hadoop3 | SecondaryNamenode |
使用ssh工具分别连接上三台服务器:
使用sudo vim /etc/hosts编辑ip地址
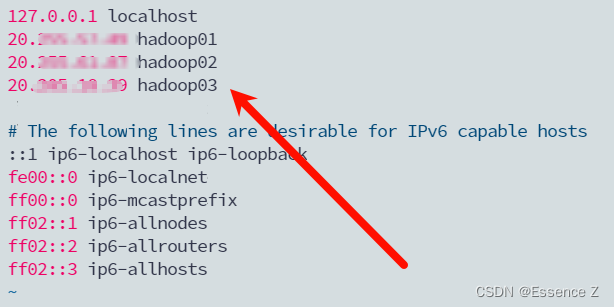
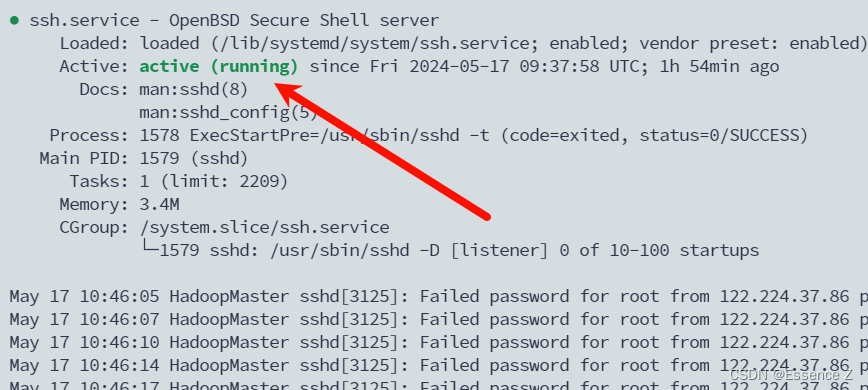
安装open-ssh,实现ssh免秘登录
sudo apt-get update
sudo apt-get install openssh-server
sudo apt-get install systemd
sudo systemctl enable ssh
sudo systemctl status ssh
- 1
- 2
- 3
- 4
- 5
生成ssh秘钥:ssh-keygen -t rsa,一直空格就好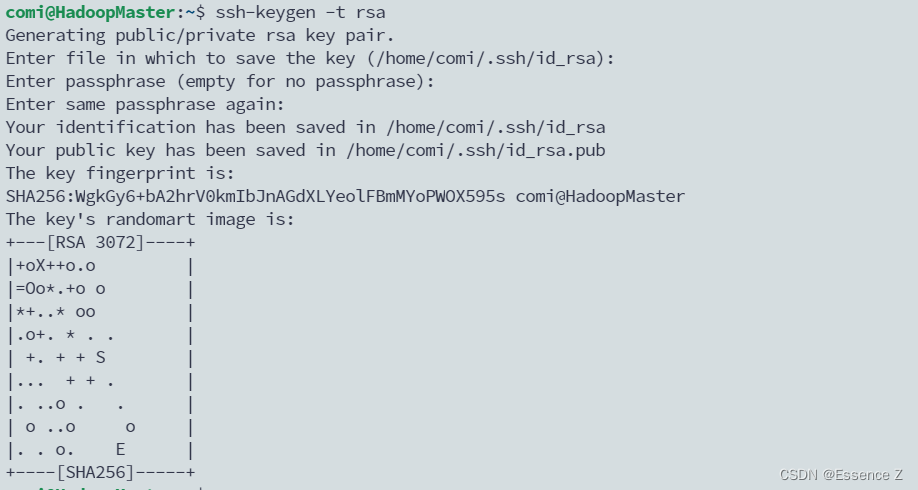
将密钥分发到其他机器上
ssh-copy-id hadoop1
ssh-copy-id hadoop2
ssh-copy-id hadoop3
- 1
- 2
- 3

测试ssh功能:ssh hadoop2
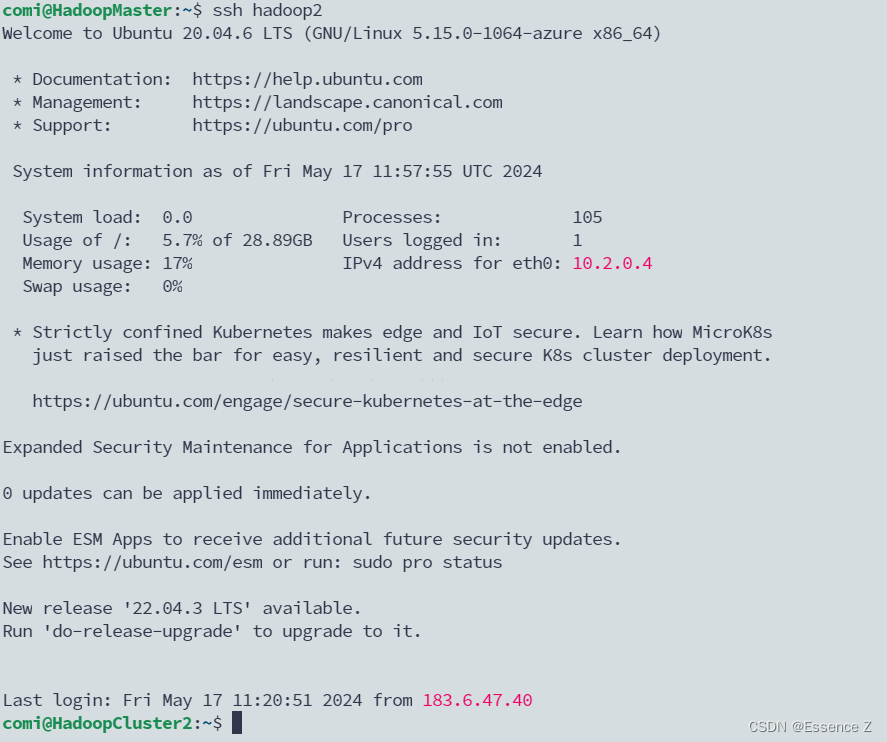
测试好无问题后,将hadoop3.1.3和jdk8u171上传到ubuntu下
hadoop3.1.3下载链接:https://www.apache.org/dyn/closer.cgi/hadoop/common/hadoop-3.1.3/hadoop-3.1.3.tar.gz
jdk8u171下载链接:https://www.oracle.com/java/technologies/javase/8u171-relnotes.html
所有的软件目录都存放在/home/comi下,请自行修改为自己文件所在位置
安装jdk
tar -xvf jdk-8u171-linux-x64.tar.gz
mv jdk1.8.0_171/ jdk
sudo vim /etc/profile
- 1
- 2
- 3
修改export为以下部分,注意路径按自己设定的路径来
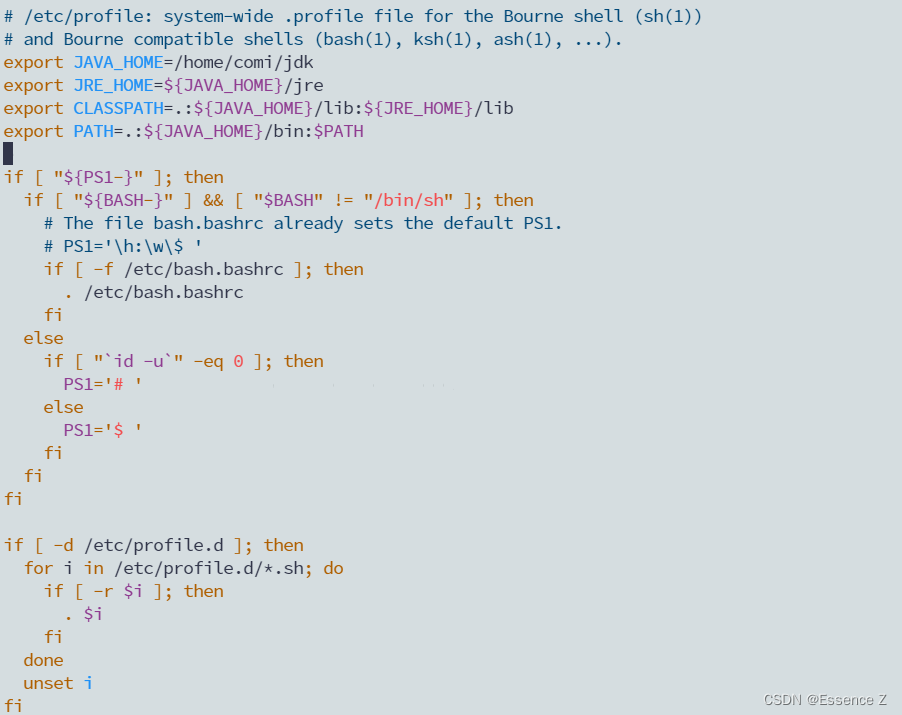
修改完后执行以下指令:
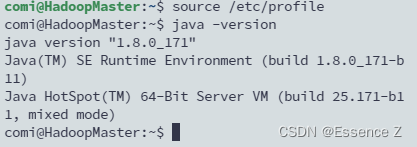
source /etc/profile
java -version
- 1
- 2
输出对应java版本即成功运行
安装hadoop:
解压hadoop文件:
tar -zvxf hadoop-3.1.3.tar.gz
mv hadoop-3.1.3 hadoop
- 1
- 2

配置环境变量:
vim ~/.bashrc
export PATH=$PATH:/home/comi/hadoop/bin:/home/comi/hadoop/sbin
# :wq! 保存退出后执行如下命令,使配置生效
source ~/.bashrc
- 1
- 2
- 3
- 4
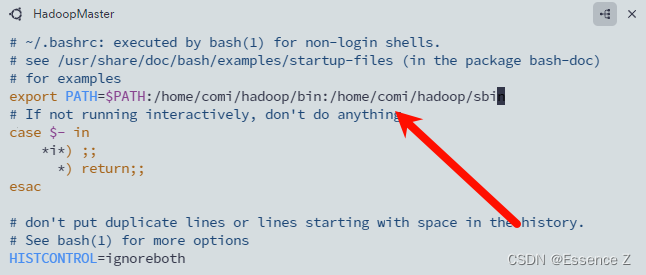
修改配置文件:
cd /home/comi/hadoop/etc/hadoop
vim hadoop-env.sh
#在hadoop-env.sh中添加
export JAVA_HOME=/home/comi/jdk1.8.0_171
- 1
- 2
- 3
- 4

vim works
- 1
修改为以下内容

安装zookeeper(可选):
可在华为镜像站下下载对应版本:https://mirrors.huaweicloud.com/
在zookeeper下创建子目录.data用于存放数据,logs存放日志
mkdir -p /home/comi/zookeeper/data
mkdir -p /home/comi/zookeeper/logs
- 1
- 2
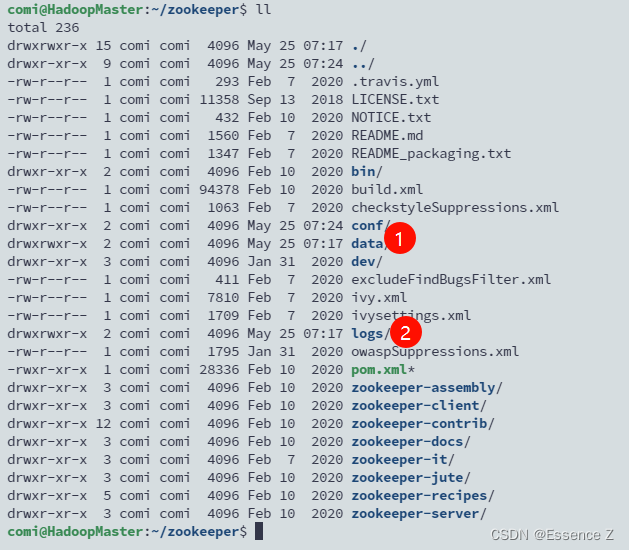
修改zookeeper配置,这里记得开放服务器的2181端口
mv /home/comi/zookeeper/zoo_sample.cfg /home/comi/zookeeper/zoo.cfg
vim zoo.cfg
- 1
- 2
举个例子:server.1=192.168.1.121:2888:3888
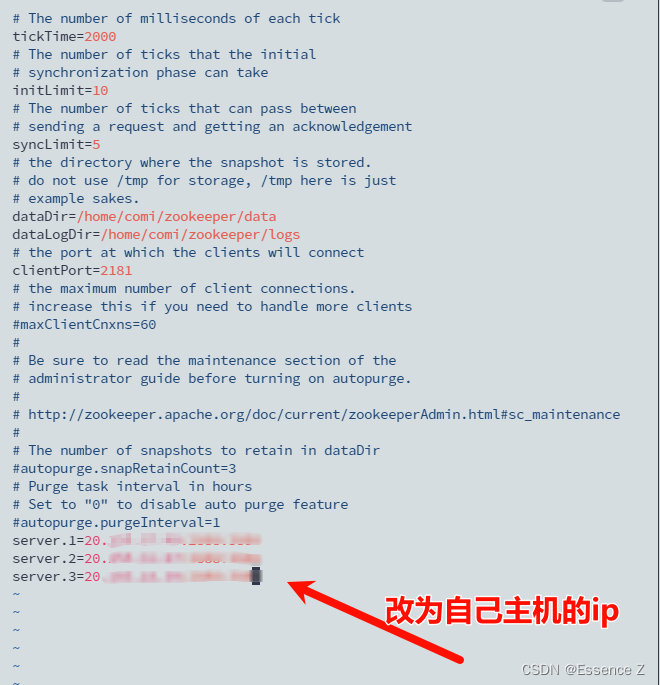
在data目录下新建一个myid的文件,1号机就输入1保存退出就行
vim /home/comi/zookeeper/data/myid
- 1
配置hadoop:
检查hadoop是否能正常运行:
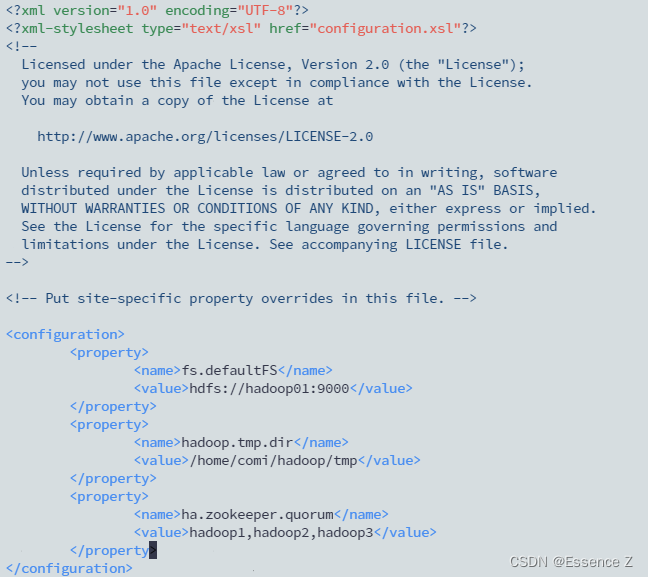
修改hadoop相关配置文件:
1.core-site.xml
2.hdfs-site.xml
<?xml version="1.0" encoding="UTF-8"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <!-- Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with the License. You may obtain a copy of the License at http://www.apache.org/licenses/LICENSE-2.0 Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the specific language governing permissions and limitations under the License. See accompanying LICENSE file. --> <!-- Put site-specific property overrides in this file. --> <configuration> <property> <name>dfs.nameservices</name> <value>ns1</value> </property> <property> <name>dfs.ha.namenodes.ns1</name> <value>nn1,nn2</value> </property> <property> <name>dfs.namenode.rpc-address.ns1.nn1</name> <value>hadoop1:9000</value> </property> <property> <name>dfs.namenode.http-address.ns1.nn1</name> <value>hadoop1:9870</value> </property> <property> <name>dfs.namenode.rpc-address.ns1.nn2</name> <value>hadoop2:9000</value> </property> <property> <name>dfs.namenode.http-address.ns1.nn2</name> <value>hadoop2:9870</value> </property> <property> <name>dfs.namenode.shared.edits.dir</name> <value>qjournal://hadoop1;hadoop2;hadoop3/ns1</value> </property> <property> <name>dfs.journalnode.edits.dir</name> <value>/home/comi/hdfs/journal</value> </property> <property> <name>dfs.namenode.name.dir</name> <value>/home/comi/hdfs/name</value> </property> <property> <name>dfs.datanode.data.dir</name> <value>/home/comi/hdfs/data</value> </property> <property> <name>dfs.ha.automatic-failover.enabled</name> <value>true</value> </property> <property> <name>dfs.client.failover.proxy.provider.ns1</name> <value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value> </property> <property> <name>dfs.ha.fencing.methods</name> <value> sshfence shell(/bin/true) </value> </property> <property> <name>dfs.ha.fencing.ssh.private-key-files</name> <value>/root/.ssh/id_rsa</value> </property> </configuration>

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
3.yarn-site.xml
<configuration> <property> <name>yarn.resourcemanager.ha.enabled</name> <value>true</value> </property> <property> <name>yarn.resourcemanager.cluster-id</name> <value>yrc</value> </property> <property> <name>yarn.resourcemanager.ha.rm-ids</name> <value>rm1,rm2</value> </property> <property> <name>yarn.resourcemanager.hostname.rm1</name> <value>hadoop2</value> </property> <property> <name>yarn.resourcemanager.hostname.rm2</name> <value>hadoop3</value> </property> <property> <name>yarn.resourcemanager.zk-address</name> <value>hadoop1,hadoop2,hadoop3</value> </property> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <property> <name>yarn.log-aggregation-enable</name> <value>true</value> </property> </configuration>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68

