
热门标签
热门文章
- 1《计算机网络课程设计》基本操作(基于Cisco Packet Tracer)_查看计算机网络课程设计配置的命令
- 2考研数学130+的强化复习规划(附暑假经验分享)
- 3Cannot resolve plugin org.codehaus.mojo:exec-maven-plugin:<unknown>
- 4【MySQL】Mysql数据库导入导出sql文件、备份数据库、迁移数据库_mysql导入sql文件
- 5【机器学习】使用决策树分类器预测汽车安全性的研究与分析
- 6Python爬虫基础之scrapy框架安装,工作三年程序员在线讲解~_scrapy爬虫框架安装
- 7Tailwind CSS 响应式设计实战指南_tailwindcss 响应式
- 8c语言冒泡排序法代码(c语言冒泡排序法代码讲解)
- 92024最新一线互联网大厂常见高并发面试题解析_java高并发面试题
- 10Python整理医学数据_python 临床数据管理
当前位置: article > 正文
hadoop—haddop部署、yarn管理器使用、hdfs的高可用、yarn的高可用、Hbase分布式部署_哈道普分布式部署安装是什么原理
作者:IT小白 | 2024-07-15 06:04:05
赞
踩
哈道普分布式部署安装是什么原理
1、hadoop简介




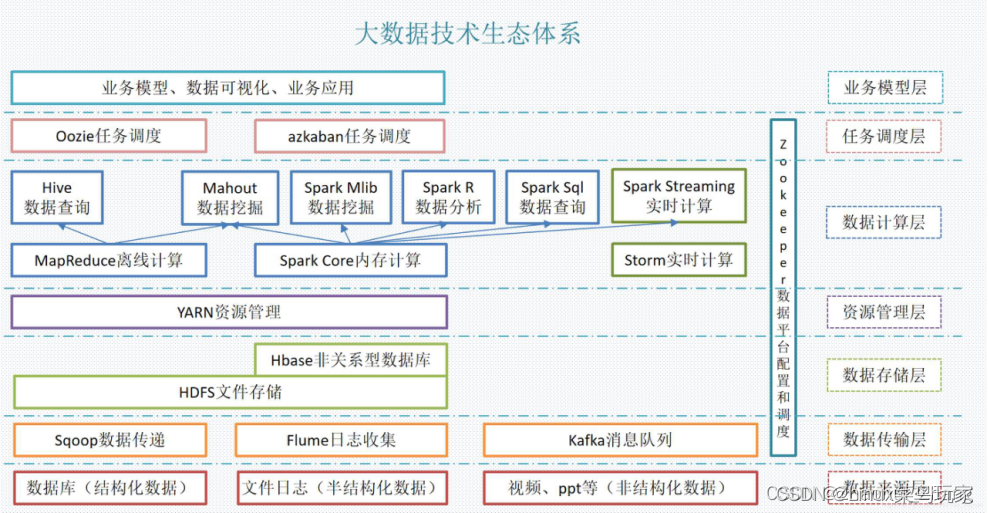
2、hadoop部署
三种支持的模式Hadoop 集群:
本地(独立)模式
伪分布式模式
全分布式模式
2.1 本地(独立)模式
[root@server1 ~]# useradd hadoop 创建hadoop用户 [root@server1 ~]# su - hadoop 用普通用户部署,不用超户 [hadoop@server1 ~]$ lftp 172.25.254.50 lftp 172.25.254.50:/> cd pub/ lftp 172.25.254.50:/pub> ls -rwxr-xr-x 1 0 0 359196911 May 31 10:35 hadoop-3.2.1.tar.gz -rwxr-xr-x 1 0 0 185646832 May 31 10:34 jdk-8u181-linux-x64.tar lftp 172.25.254.50:/pub> get hadoop-3.2.1.tar.gz 下载hadoop安装包 359196911 bytes transferred lftp 172.25.254.50:/pub> get jdk-8u181-linux-x64.tar.gz 下载hadoop需要安装jdk 185646832 bytes transferred [hadoop@server1 ~]$ tar zxf jdk-8u181-linux-x64.tar.gz 下载后 解压 [hadoop@server1 ~]$ ln -s jdk1.8.0_181/ java 为了方便,做一个软连接 [hadoop@server1 ~]$ tar zxf hadoop-3.2.1.tar.gz 解压 [hadoop@server1 ~]$ ln -s hadoop-3.2.1 hadoop 做软连接 [hadoop@server1 ~]$ cd /home/hadoop/hadoop/etc/hadoop [hadoop@server1 hadoop]$ vim hadoop-env.sh 设置环境变量

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17

[hadoop@server1 ~]$ cd hadoop
[hadoop@server1 hadoop]$ bin/hadoop 运行
[hadoop@server1 hadoop]$ cp etc/hadoop/*.xml input
[hadoop@server1 hadoop]$ bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.2.1.jar grep input output 调用jar包,jar包里面有很多方法
'dfs[a-z.]+' 过滤input文件中以dfs开头的,输出到output目录
[hadoop@server1 hadoop]$ cd output/
[hadoop@server1 output]$ ls
part-r-00000 _SUCCESS 结果输出到output目录
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
2.2 伪分布模式
[root@server1 ~]# passwd hadoop 给hadoop用户设置密码 Changing password for user hadoop. New password: BAD PASSWORD: The password is shorter than 8 characters Retype new password: [hadoop@server1 ~]$ ssh-keygen 配置免密 [hadoop@server1 ~]$ ssh-copy-id server1 [hadoop@server1 ~]$ cd hadoop [hadoop@server1 hadoop]$ cd etc/hadoop/ [hadoop@server1 hadoop]$ vim core-site.xml 在文件最后添加如下参数 <configuration> <property> <name>fs.defaultFS</name> <value>hdfs://localhost:9000</value> hdfs master地址 </property> </configuration> [hadoop@server1 hadoop]$ ssh localhost 免密 [hadoop@server1 hadoop]$ vim hdfs-site.xml 在文件最后添加参数 <configuration> <property> <name>dfs.replication</name> <value>1</value> 副本数改为1,默认为3 </property> </configuration> [hadoop@server1 ~]$ cd /home/hadoop/hadoop [hadoop@server1 hadoop]$ bin/hdfs namenode -format 格式化 [hadoop@server1 hadoop]$ ls /tmp/ 默认数据目录 hadoop hadoop-hadoop hadoop-hadoop-namenode.pid hsperfdata_hadoop [hadoop@server1 hadoop]$ sbin/start-dfs.sh 启动hdfs相关进程 [hadoop@server1 ~]$ vim .bash_profile 添加java 命令路经
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30

[hadoop@server1 ~]$ source .bash_profile 生效
[hadoop@server1 ~]$ jps 查看java进程
4196 Jps
3957 SecondaryNameNode 注节点出现故障,SecondaryNameNode可以接管
3659 NameNode master进程
3772 DataNode
- 1
- 2
- 3
- 4
- 5
- 6
访问:172.25.50.1:9870

[hadoop@server1 hadoop]$ bin/hdfs dfsadmin -report 查看分布式文件系统概况
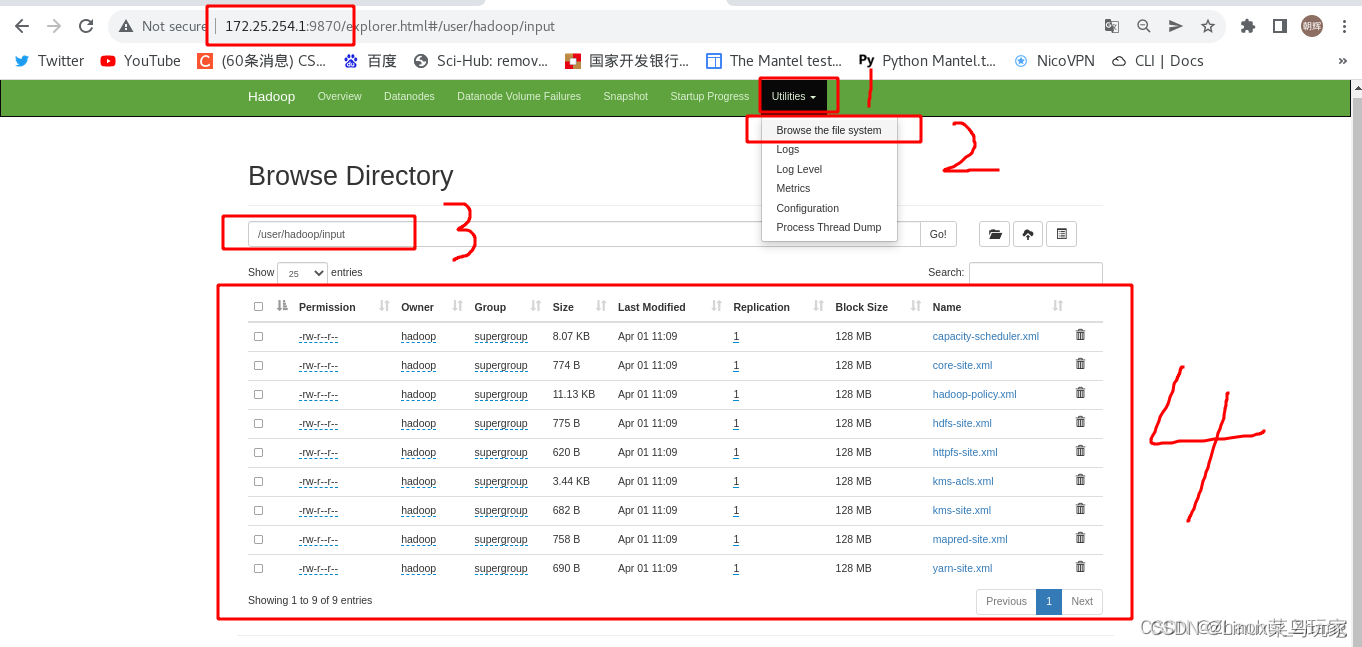
[hadoop@server1 hadoop]$ bin/hdfs dfs -mkdir /user/ 创建user用户目录
[hadoop@server1 hadoop]$ bin/hdfs dfs -mkdir /user/hadoop 创建hadoop用户
[hadoop@server1 hadoop]$ bin/hdfs dfs -put input 上传input目录
- 1
- 2
- 3
- 4
input目录里的内容都已经上传了
[hadoop@server1 hadoop]$ rm -fr input/ 删除本地input
[hadoop@server1 hadoop]$ rm -fr output/ 删除本地output
[hadoop@server1 hadoop]$ bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.2.1.jar wordcount input output 统计一下单词词频,此时本地没有input,要在分布式文件系统取
- 1
- 2
- 3
生成了output文件,如下图

[hadoop@server1 hadoop]$ bin/hdfs dfs -ls 查看,有两个文件 Found 2 items drwxr-xr-x - hadoop supergroup 0 2022-05-31 23:29 input drwxr-xr-x - hadoop supergroup 0 2022-06-01 01:18 output [hadoop@server1 hadoop]$ bin/hdfs dfs cat output/* 可以查看output里面所有内容 "*" 21 "AS 9 "License"); 9 "alice,bob 21 "clumping" 1 (ASF) 1 (root 1 (the 9 --> 18 -1 1 -1, 1 0.0 1 [hadoop@server1 hadoop]$ bin/hdfs dfs -get output 也可以将output下载到本地 [hadoop@server1 hadoop]$ cd output/ [hadoop@server1 output]$ cat * 查看 "*" 21 "AS 9 "License"); 9 "alice,bob 21 "clumping" 1 (ASF) 1 (root 1 (the 9 --> 18 -1 1
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
2.3 全分布式模式
需要三台虚拟机,其中server1为master节点,server2、3为worker节点
[hadoop@server1 hadoop]$ sbin/stop-dfs.sh 停掉hdfs进程 需要三台虚拟机配置一致,需要同步,可以通过nfs共享,在所有节点安装nfs套件 [root@server1 ~]# yum install -y nfs-utils -y [root@server2 ~]# yum install -y nfs-utils -y [root@server3 ~]# yum install -y nfs-utils -y [root@server1 ~]# id hadoop 查看hadoop id uid=1001(hadoop) gid=1001(hadoop) groups=1001(hadoop) [root@server1 ~]# vim /etc/exports /home/hadoop *(rw,anonuid=1001,anongid=1001) /home/hadoop 将这个目录共享出去,都是以id为1001的身份去写 [root@server1 ~]# systemctl start nfs 启动nfs [root@server1 ~]# showmount -e Export list for server1: /home/hadoop * 目录已经共享 [root@server2 ~]# useradd hadoop server2上创建hdaoop用户,注意id必须保持一致要是1001都是10001 [root@server3 ~]# useradd hadoop server3上创建hdaoop用户,注意id必须保持一致要是1001都是10001 [root@server2 ~]# mount 172.25.50.1:/home/hadoop/ /home/hadoop/ 挂载 [root@server3 ~]# mount 172.25.50.1:/home/hadoop/ /home/hadoop/ 挂载 此时server1、server2、server3上的数据就完全一致了 [hadoop@server1 ~]$ ssh server2 免密 [hadoop@server1 ~]$ ssh server3 免密 [hadoop@server1 ~]$ ssh 172.25.50.1 免密 [hadoop@server1 ~]$ rm -fr /tmp/* 将之前默认数据目录里的内容删除 [hadoop@server1 ~]$ cd hadoop/etc/hadoop/ [hadoop@server1 hadoop]$ vim core-site.xml
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25

[hadoop@server1 hadoop]$ vim workers 添加server2、server3为worker
server2 写主机名要有解析
server3
[hadoop@server1 hadoop]$ vim hdfs-site.xml
- 1
- 2
- 3
- 4

[hadoop@server1 ~]$ cd hadoop [hadoop@server1 hadoop]$ bin/hdfs namenode -format 格式化 [hadoop@server1 hadoop]$ sbin/start-dfs.sh 启动 [hadoop@server1 hadoop]$ jps 启动NameNode进程 5657 Jps 5308 NameNode 5533 SecondaryNameNode [hadoop@server2 ~]$ jps 启动DataNode进程 4336 DataNode 4543 Jps [hadoop@server3 ~]$ jps 启动DataNode进程 4370 Jps 4307 DataNode [hadoop@server1 hadoop]$ bin/hdfs dfs -mkdir /user 创建用户目录 [hadoop@server1 hadoop]$ bin/hdfs dfs -mkdir /user/hadoop 创建hadoop用户 [hadoop@server1 hadoop]$ bin/hdfs dfs -mkdir input 在用户主目录里创建input目录 [hadoop@server1 hadoop]$ bin/hdfs dfs -ls 查看用户主目录 Found 1 items drwxr-xr-x - hadoop supergroup 0 2022-06-01 06:42 input 创建成功 [hadoop@server1 hadoop]$ bin/hdfs dfs -put etc/hadoop/*.xml input 上传 [hadoop@server1 hadoop]$ bin/hdfs dfs -ls input 查看input目录,上传xml文件成功 Found 9 items -rw-r--r-- 2 hadoop supergroup 8260 2022-06-01 06:45 input/capacity-scheduler.xml -rw-r--r-- 2 hadoop supergroup 886 2022-06-01 06:45 input/core-site.xml -rw-r--r-- 2 hadoop supergroup 11392 2022-06-01 06:45 input/hadoop-policy.xml -rw-r--r-- 2 hadoop supergroup 867 2022-06-01 06:45 input/hdfs-site.xml -rw-r--r-- 2 hadoop supergroup 620 2022-06-01 06:45 input/httpfs-site.xml -rw-r--r-- 2 hadoop supergroup 3518 2022-06-01 06:45 input/kms-acls.xml [hadoop@server1 hadoop]$ bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.2.1.jar wordcount input output 输出词频
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29

3、节点扩容
再开一台虚拟机server4
[root@server4 ~]# useradd hadoop
[root@server4 ~]# yum install -y nfs-utils
[root@server4 ~]# mount 172.25.50.1:/home/hadoop/ /home/hadoop/ 挂载,使所有数据保持一致
[hadoop@server4 ~]$ cd hadoop/etc/hadoop/
[hadoop@server4 hadoop]$ vim workers
server2
server3
server4
[hadoop@server4 hadoop]$ bin/hdfs --daemon start datanode 启动datanode节点
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9

4、屏蔽节点
[hadoop@server1 ~]$ cd hadoop/etc/hadoop/
[hadoop@server1 hadoop]$ vim hdfs-site.xml
- 1
- 2

[hadoop@server1 hadoop]$ vim hosts.exclude
server2 添加server2 ,屏蔽掉server2
[hadoop@server1 hadoop]$ bin/hdfs dfsadmin -refreshNodes 刷新节点,读取刚才配置
Refresh nodes successful
[hadoop@server1 hadoop]$ bin/hdfs dfsadmin -report
- 1
- 2
- 3
- 4
- 5
- 6

[hadoop@server1 hadoop]$ bin/hdfs --daemon stop datanode 也可以用此方法进行节点下线
- 1
5 、hdfs分布式工作原理


三个副本所处不同位置,如果客户端在集群节点,第1个副本一定处于本机

6、分布式计算框架—yarn管理器的使用
添加mapred配置
[hadoop@server1 hadoop]$ cd etc/hadoop/ 在文件最后添加如下参数
[hadoop@server1 hadoop]$ vim mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.application.classpath</name>
<value>$HADOOP_MAPRED_HOME/share/hadoop/mapreduce/*:$HADOOP_MAPRED_HOME/share/hadoop/mapreduce/lib/*</value>
</property>
</configuration>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
添加yarn配置
[hadoop@server1 hadoop]$ vim yarn-site.xml 在文件最后添加如下参数
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.env-whitelist</name>
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_HOME,PATH,LANG,TZ ,HADOOP_MAPRED_HOME</value>
</property>
</configuration>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11

[hadoop@server1 ~]$ cd hadoop
[hadoop@server1 hadoop]$ sbin/start-yarn.sh 启动
Starting resourcemanager 资源管理器
Starting nodemanagers 节点管理器
- 1
- 2
- 3
- 4
启动yarn管理器后,会在master节点上开启一个“8088”的端口,浏览器访问界面如下。

7、hadoop高可用平台部署——hdfs的高可用
7.1 安装并配置zookeeper集群
停掉相关进程 [hadoop@server1 hadoop]$ sbin/stop-yarn.sh [hadoop@server1 hadoop]$ sbin/stop-dfs.sh [hadoop@server1 hadoop]$ rm -fr /tmp/* 清除tmp里面的信息 在开一台虚拟机server5,由于内存有限,server3、4、5都设置为1G server1、5做高可用、server2、3、4为zk集群 [root@server5 ~]# useradd hadoop 创建hadoop用户 [root@server5 ~]# yum install nfs-utils -y 安装nfs套件 [root@server5 ~]# mount 172.25.50.1:/home/hadoop/ /home/hadoop/ 挂载 [hadoop@server1 ~]$ lftp 172.25.254.50 lftp 172.25.254.50:/pub> get zookeeper-3.4.9.tar.gz 下载zookeeper安装包 [hadoop@server1 ~]$ tar zxf zookeeper-3.4.9.tar.gz 解压 [hadoop@server2 ~]$ cd zookeeper-3.4.9/ [hadoop@server2 zookeeper-3.4.9]$ cd conf/ [hadoop@server2 conf]$ cp zoo_sample.cfg zoo.cfg 拷贝模板生成主配置文件 [hadoop@server2 conf]$ vim zoo.cfg 编辑主配置文件,在文件最后添加zookeeper集群节点 server.1=172.25.50.2:2888:3888 server.1中的1为主机编号,不是主机名,2888为数据同步,通信端口,3888为选举端口 server.2=172.25.50.3:2888:3888 server.3=172.25.50.4:2888:3888 [hadoop@server2 conf]$ mkdir /tmp/zookeeper 创建zookeeper数据目录 [hadoop@server2 conf]$ echo 1 > /tmp/zookeeper/myid 在数据目录里创建myid,其中myid号必须和配置文件配置的id号保持一致 [hadoop@server3 ~]$ mkdir /tmp/zookeeper [hadoop@server3 ~]$ echo 2 > /tmp/zookeeper/myid [hadoop@server4 ~]$ mkdir /tmp/zookeeper [hadoop@server4 ~]$ echo 3 > /tmp/zookeeper/myid [hadoop@server2~]$ cd zookeeper-3.4.9/ [hadoop@server2 zookeeper-3.4.9]$ bin/zkServer.sh satrt 启动 [hadoop@server3 ~]$ cd zookeeper-3.4.9/ [hadoop@server3 zookeeper-3.4.9]$ bin/zkServer.sh satrt 启动 [hadoop@server4 ~]$ cd zookeeper-3.4.9/ [hadoop@server4 zookeeper-3.4.9]$ bin/zkServer.sh satrt 启动
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
7.2 更改hadoop配置
[hadoop@server1 ~]$ cd hadoop [hadoop@server1 hadoop]$ cd etc/hadoop/ [hadoop@server1 hadoop]$ vim core-site.xml <configuration> <property> <name>fs.defaultFS</name> <value>hdfs://master</value> 此处需要修改,改成master,而不是具体某个master地址 </property> <property> <name>ha.zookeeper.quorum</name> <value>172.25.50.2:2181,172.25.50.3:2181,172.25.50.4:2181</value> 添加zk集群连接地址 </property> </configuration> [hadoop@server1 hadoop]$ cd etc/hadoop/ [hadoop@server1 hadoop]$ vim hdfs-site.xml 编辑hdfs配置文件 <configuration> <property> <name>dfs.replication</name> <value>3</value> 将副本数改为3,现在有3个dn </property> <property> <name>dfs.nameservices</name> <value>masters</value> 指定dfs的nameserver为master和core-site.xml文件中的设置保持一致 </property> <property> <name>dfs.ha.namenodes.masters</name> <value>h1,h2</value> 指定master的两个节点为h1、h2 </property> <property> <name>dfs.namenode.rpc-address.masters.h1</name> <value>172.25.50.1:9000</value> 指定master节点h1的通信地址 </property> <property> <name>dfs.namenode.http-address.masters.h1</name> <value>172.25.50.1:9870</value> 指定master节点h1图形化端口 </property> <property> <name>dfs.namenode.rpc-address.masters.h2</name> <value>172.25.50.5:9000</value> 指定master节点h2的通信地址 </property> <property> <name>dfs.namenode.http-address.masters.h2</name> <value>172.25.50.5:9870</value> 指定master节点h2图形化端口 </property> <property> <name>dfs.namenode.shared.edits.dir</name> <value>qjournal://172.25.50.2:8485;172.25.50.3:8485;172.25.254.4:8485/masters</value> </property> 指定namenode原数据在日志节点存放位置 <property> <name>dfs.journalnode.edits.dir</name> <value>/tmp/journaldata</value> 指定日志节点本地存储路经 </property> </configuration> <property> <name>dfs.ha.automatic-failover.enabled</name> 开启NN失败自动切换 <value>true</value> </property> <property> <name>dfs.client.failover.proxy.provider.masters</name> <value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value> 开启自动切换的实现方式 </property> <property> <name>dfs.ha.fencing.methods</name> 隔离机制 <value> sshfence 两种隔离方式,ssh方式、shell方式 shell(/bin/true) </value> </property> <property> <name>dfs.ha.fencing.ssh.private-key-files</name> <value>/home/hadoop/.ssh/id_rsa</value> 隔离ssh机制需要免密 </property>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85



7.3 启动hdfs集群

在三个DN节点上依次启动 journalnode(第一次启动 hdfs 必须先启动 journalnode)
[hadoop@server2 ~]$ cd hadoop
[hadoop@server2 hadoop]$ bin/hdfs --daemon start journalnode
[hadoop@server3 ~]$ cd hadoop
[hadoop@server3 hadoop]$ bin/hdfs --daemon start journalnode
[hadoop@server4 ~]$ cd hadoop
[hadoop@server4 hadoop]$ bin/hdfs --daemon start journalnode
[hadoop@server1 hadoop]$ cd hadoop
- 1
- 2
- 3
- 4
- 5
- 6
- 7
格式化hdfs集群
[hadoop@server1 hadoop]$ bin/hdfs namenode -format
- 1
Namenode 数据默认存放在/tmp,需要把数据拷贝到h2(即从server1复制到server2)
[hadoop@server1 hadoop]$ scp -r /tmp/hadoop-hadoop 172.25.50.5:/tmp
- 1
格式化 zookeeper (只需在 h1 上执行即可)
[hadoop@server1 hadoop]$ bin/hdfs zkfc -formatZK
- 1
启动hdfs集群
[hadoop@server1 ~]$ cd hadoop
[hadoop@server1 hadoop]$ sbin/start-dfs.sh
- 1
- 2
测试:在浏览器访问master端
可以看到,server1为“active"是主机,server5为“standby”是备用机。
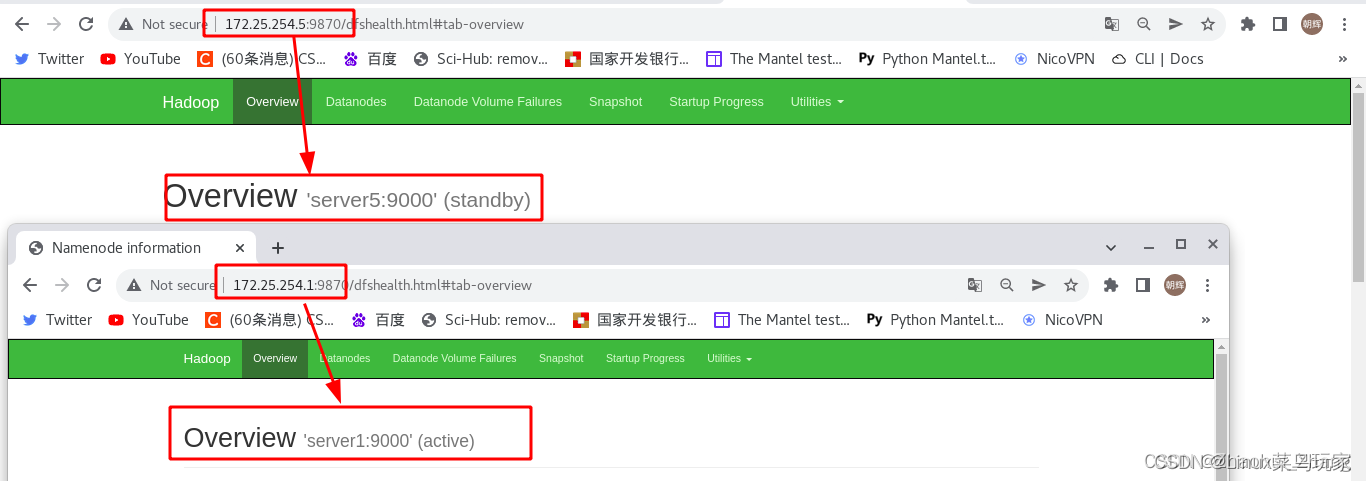
在主机master节点(server1)上传数据
[hadoop@server1 hadoop]$ bin/hdfs dfs -mkdir /user
[hadoop@server1 hadoop]$ bin/hdfs dfs -mkdir /user/hadoop
[hadoop@server1 hadoop]$ bin/hdfs dfs -mkdir input //创建目录
[hadoop@server1 hadoop]$ bin/hdfs dfs -put etc/hadoop/*.xml input //上传数据
- 1
- 2
- 3
- 4
模拟server1节点故障
结束server1中的“NameNode”进程
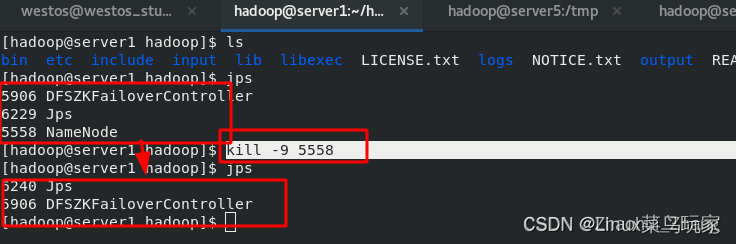
通过浏览器查看server5已经成为了“activate”端,数据已经从server1切换到了server5上。
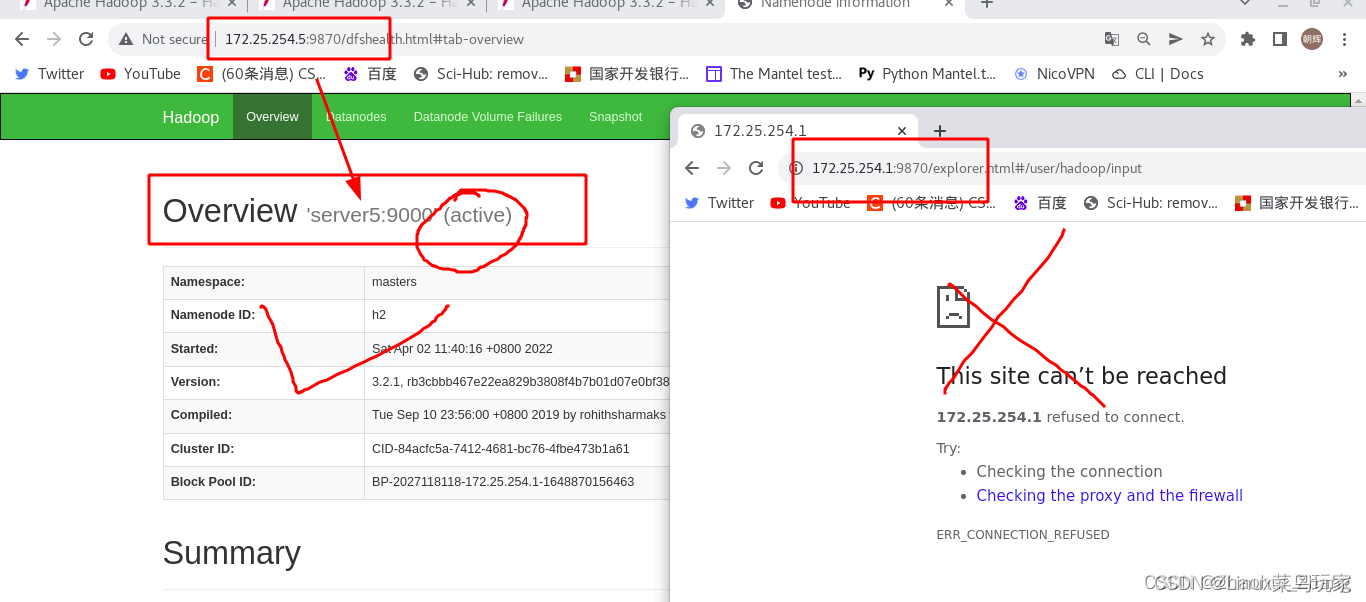
server1节点恢复正常
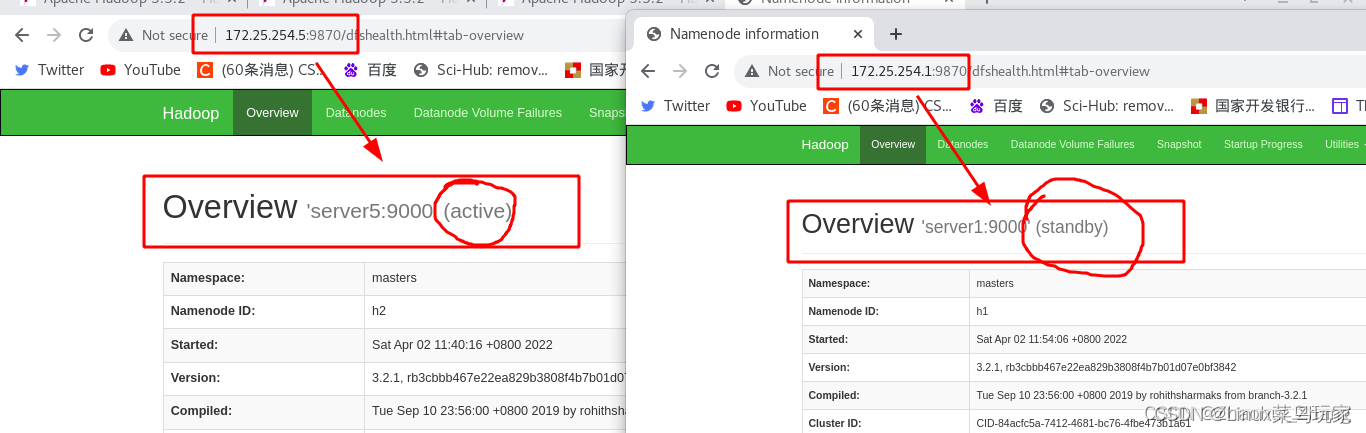
server1节点恢复正常后,仍然只是从节点standby状态,成为了备用机。可以理解为:谁先注册zk,谁就是主master,其他节点就是备用master。
8、hadoop高可用平台部署——yarn的高可用(待续)
9、hadoop高可用平台部署——Hbase分布式部署(待续)
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/IT小白/article/detail/827976
推荐阅读
相关标签

