
- 1【雕爷学编程】Arduino智慧校园之学生刷卡考勤记录查询_arduino的lcd idcard
- 2关于Stable diffusion的各种模型,看这篇就可以了!_stable diffusion模型
- 3mac电脑进入host的方法_mac进入host
- 4大数据-Hadoop-户管理界面:HUE(Hadoop User Experience)【将Hadoop中各种相关的软件(HDFS、Hive...)的操作界面融合在一起,形成一个统一的操作界面】
- 5Web前端最全vue+element-ui实现动态的权限管理和菜单渲染_权限设置ui(1),一文全懂_vue权限列表渲染
- 6Datawhale出品:《GLM-4 大模型部署微调教程》发布!_llama-factory 微调glm4
- 7SQL表连接方式_sql 表连接
- 8YOLO--置信度(超详细解读)_yolo 置信度只有两位吗
- 9Upload-labs通关攻略(适合新手)_upload-labs第十四关_upload-labs十四
- 10MySQL下载和自定义安装教程(8.0.34)_mysql8.0.34安装教程
【数仓】Hadoop软件安装及使用(集群配置)_hadoop集群使用
赞
踩
一、环境准备
1、准备3台虚拟机
- Hadoop131:192.168.56.131
- Hadoop132:192.168.56.132
- Hadoop133:192.168.56.133
本例系统版本 CentOS-7.8,已安装jdk1.8
2、hosts配置,关闭防火墙
vi /etc/hosts添加如下内容,然后保存
192.168.56.131 hadoop131
192.168.56.132 hadoop132
192.168.56.133 hadoop133
- 1
- 2
- 3
关闭防火墙
systemctl stop firewalld
- 1
3、配置证书登录(免秘钥)
三台服务器都要操作一遍
ssh-keygen -t rsa -N '' -f /root/.ssh/id_rsa -q
ssh-copy-id -i /root/.ssh/id_rsa.pub root@hadoop131
ssh-copy-id -i /root/.ssh/id_rsa.pub root@hadoop132
ssh-copy-id -i /root/.ssh/id_rsa.pub root@hadoop133
- 1
- 2
- 3
- 4
- 5
4、创建 Xsync 分发指令
rsync是Linux系统下的一个非常实用的数据备份和同步工具,它可以在本地或远程系统之间进行文件或目录的同步和备份。这个指令的基本原理是通过对比源文件和目标文件的差异,只复制差异部分,从而提高数据传输的效率。
由于 xsync 是对 rsync 的再封装,因此需要先安装 rsync
yum install -y rsync
- 1
三台服务器都要安装
rsync
本节内容参考:xsync 集群同步工具
在 /usr/bin 下新建 xsync.sh
vi /usr/bin/xsync.sh
- 1
将以下内容粘贴到 xsync.sh 脚本中
#!/bin/bash #1. 判断参数个数 if [ $# -lt 1 ] then echo Not Enough Arguement! exit; fi #2. 遍历集群所有机器 for host in hadoop131 hadoop132 hadoop133 do echo ==================== $host ==================== #3. 遍历所有目录,挨个发送 for file in $@ do #4. 判断文件是否存在 if [ -e $file ] then #5. 获取父目录 pdir=$(cd -P $(dirname $file); pwd) #6. 获取当前文件的名称 fname=$(basename $file) ssh $host "mkdir -p $pdir" rsync -av $pdir/$fname $host:$pdir else echo $file does not exists! fi done done

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
修改文件权限
chmod 777 /usr/bin/xsync.sh
- 1
5、创建批量执行脚本 xcall.sh
创建文件xcall.sh
vi /usr/bin/xcall.sh
# 修改文件权限
chmod 777 /usr/bin/xcall.sh
- 1
- 2
- 3
复制如下内容
#!/bin/bash
#1. 判断参数个数
if [ $# -lt 1 ]
then
echo Not Enough Arguement!
exit;
fi
#2. 遍历集群所有机器
for host in hadoop131 hadoop132 hadoop133
do
echo ------ $host ------
ssh $host "$*"
done
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
二、安装配置Hadoop
1、下载Hadoop并安装
# 下载Hadoop软件包
wget --no-check-certificate https://dlcdn.apache.org/hadoop/common/hadoop-3.3.6/hadoop-3.3.6.tar.gz
# 解压安装
tar -xzvf hadoop-3.3.6.tar.gz
#创建Hdoop程序&数据目录;
mkdir -p /data/
#将Hadoop程序部署至/data/hadoop目录下;
mv hadoop-3.3.6/ /data/hadoop/
#查看Hadoop是否部署成功;
ls -l /data/hadoop/
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
2、配置Hadoop环境变量
配置环境变量,/etc/profile.d/hadoop_env.sh
export HADOOP_HOME=/data/hadoop
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin
- 1
- 2
- 3
使用source让新增环境生效
source /etc/profile
- 1
配置完成后分发到其他服务器
xsync.sh /etc/profile.d/hadoop_env.sh
- 1
3、Hadoop集群配置
1)配置 core-site.xml
vi /data/hadoop/etc/hadoop/core-site.xml
<?xml version="1.0" encoding="UTF-8"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <configuration> <!-- 指定NameNode的地址 --> <property> <name>fs.defaultFS</name> <value>hdfs://hadoop131:9000</value> </property> <!-- 指定Hadoop数据的存储目录 --> <property> <name>hadoop.tmp.dir</name> <!-- /tmp/hadoop-${user.name} --> <value>/data/hadoop/data</value> <description>A base for other temporary directories.</description> </property> <!-- 配置HDFS网页登录使用的静态用户为hadoopuser --> <property> <name>hadoop.http.staticuser.user</name> <value>hadoopuser</value> </property> <!-- 配置该hadoopuser(superuser)允许通过代理访问的主机节点 --> <property> <name>hadoop.proxyuser.hadoopuser.hosts</name> <value>*</value> </property> <!--配置该hadoopuser(superuser)允许通过代理用户所属组--> <property> <name>hadoop.proxyuser.hadoopuser.groups</name> <value>*</value> </property> <!--配置该hadoopuser(superuser)允许通过代理的用户 --> <property> <name>hadoop.proxyuser.hadoopuser.users</name> <value>*</value> </property> </configuration>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
2)配置 hdfs-site.xml
vi /data/hadoop/etc/hadoop/hdfs-site.xml
<?xml version="1.0" encoding="UTF-8"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <configuration> <!-- nn web端访问地址--> <property> <name>dfs.namenode.http-address</name> <value>hadoop131:9870</value> </property> <!-- 2nn web端访问地址--> <property> <name>dfs.namenode.secondary.http-address</name> <value>hadoop133:9868</value> </property> <!--测试环境指定HDFS副本的数量1 --> <property> <name>dfs.replication</name> <value>1</value> </property> </configuration>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
3)配置 mapred-site.xml
vi /data/hadoop/etc/hadoop/mapred-site.xml
使用yarn,如下配置
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
4)配置 yarn-site.xml
vi /data/hadoop/etc/hadoop/yarn-site.xml
<?xml version="1.0" encoding="UTF-8"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <configuration> <!-- 设置ResourceManager的主机名 --> <property> <name>yarn.resourcemanager.hostname</name> <value>hadoop131</value> </property> <!-- 设置NodeManager的辅助服务,通常为mapreduce_shuffle以支持MapReduce作业 --> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <!-- 设置每个NodeManager可用的内存量(以MB为单位) --> <property> <name>yarn.nodemanager.resource.memory-mb</name> <value>8192</value> </property> <!--分别设置容器请求的最小和最大内存限制--> <property> <name>yarn.scheduler.minimum-allocation-mb</name> <value>1024</value> </property> <property> <name>yarn.scheduler.maximum-allocation-mb</name> <value>8192</value> </property> <!--分别设置容器请求的最小和最大虚拟CPU核心数--> <property> <name>yarn.scheduler.minimum-allocation-vcores</name> <value>1</value> </property> <property> <name>yarn.scheduler.maximum-allocation-vcores</name> <value>4</value> </property> </configuration>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
4)修改 workers
vi /data/hadoop/etc/hadoop/workers
hadoop131
hadoop132
hadoop133
- 1
- 2
- 3
5)修改Hadoop默认启动、关闭脚本,添加root执行权限
cd /data/hadoop/sbin/
for i in `ls start*.sh stop*.sh`;do sed -i "1a\HDFS_DATANODE_USER=root\nHDFS_DATANODE_SECURE_USER=root\nHDFS_NAMENODE_USER=root\nHDFS_SECONDARYNAMENODE_USER=root\nYARN_RESOURCEMANAGER_USER=root\n\YARN_NODEMANAGER_USER=root" $i ;done
- 1
- 2
6)将hadoop131部署完成的hadoop所有文件、目录同步至其他两个节点
xsync.sh /data/hadoop/
- 1
4、启动hadoop
在启动hadoop之前,我们需要做一步非常关键的步骤,需要在Namenode上执行初始化命令,初始化name目录和数据目录。
#初始化集群;
/data/hadoop/bin/hdfs namenode -format
#停止所有服务;
/data/hadoop/sbin/stop-all.sh
#kill方式停止服务;
ps -ef|grep hadoop|grep java |grep -v grep |awk '{print $2}'|xargs kill -9
sleep 2
#启动所有服务;
/data/hadoop/sbin/start-all.sh
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
5、Hadoop集群验证
使用上面的xcall.sh命令查看进程
xcall.sh jps
- 1
结果如下
------ hadoop131 jps ------
7640 ResourceManager
7864 NodeManager
7260 DataNode
8877 Jps
7086 NameNode
------ hadoop132 jps ------
4549 DataNode
5479 Jps
4654 NodeManager
------ hadoop133 jps ------
4896 NodeManager
5733 Jps
4715 DataNode
4813 SecondaryNameNode
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
也可以分别查看3个节点Hadoop服务进程和端口信息
#查看服务进程;
ps -ef|grep -aiE hadoop
#查看服务监听端口;
netstat -ntpl
#执行JPS命令查看JAVA进程;
jps
#查看Hadoop日志内容;
tail -fn 100 /data/hadoop/logs/*.log
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
6、Hadoop WEB测试
根据如上Hadoop配置,Hadoop大数据平台部署成功,访问hadoop131 9870端口 http://192.168.56.131:9870/,可以看见如下页面:
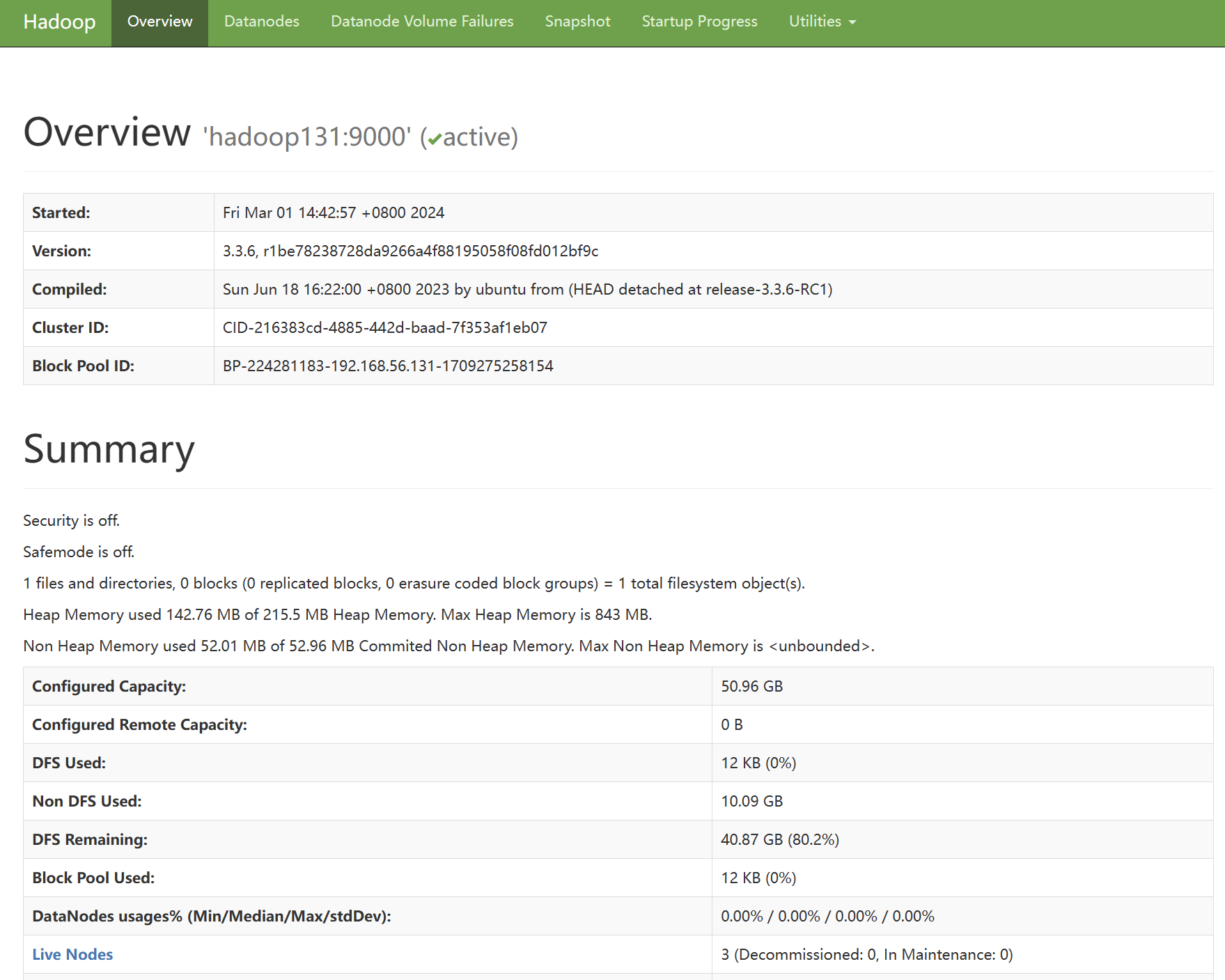
访问Hadoop集群WEB地址:http://192.168.56.131:8088/,可以看见如下页面:
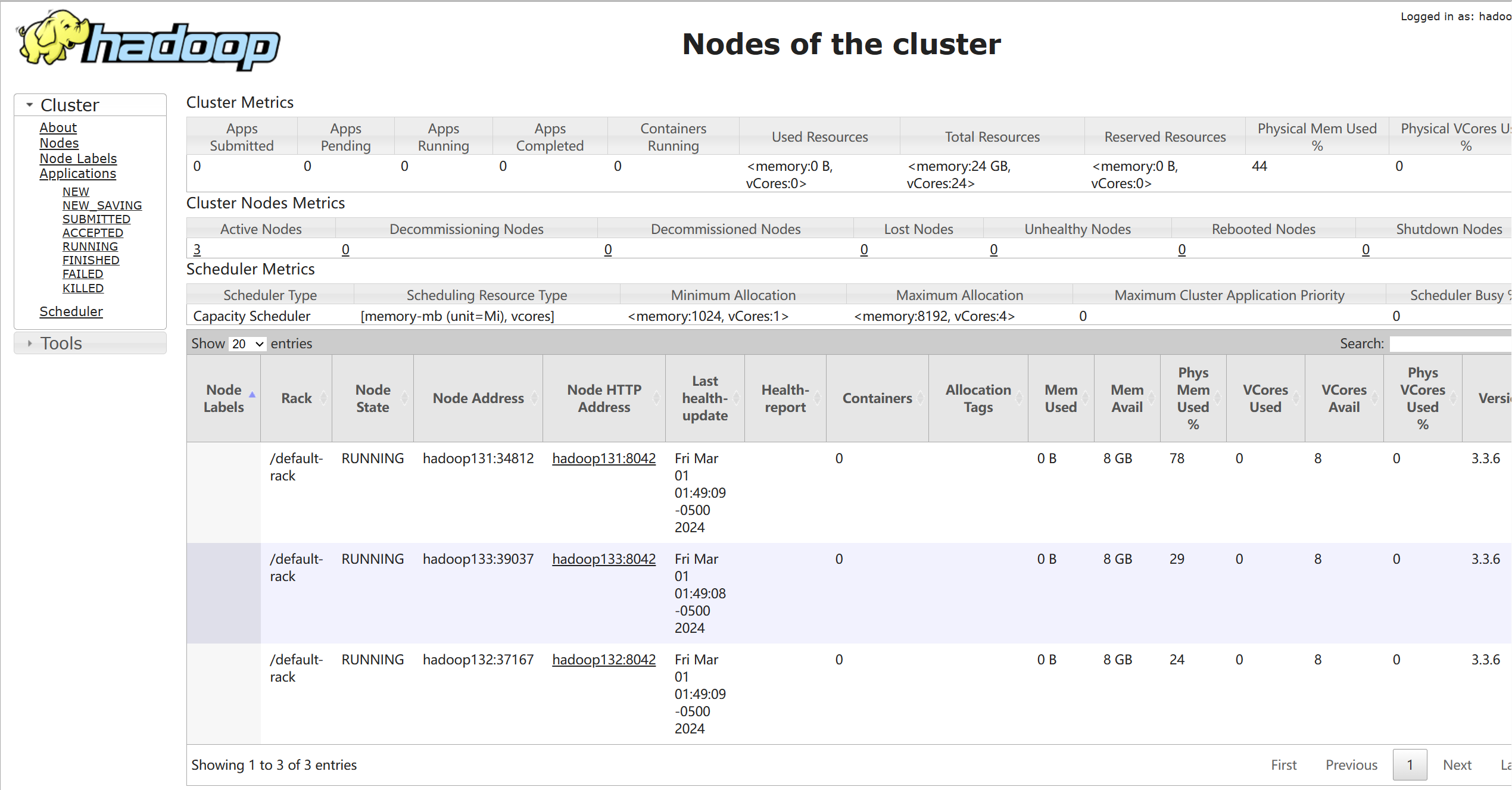
至此,Hadoop集群环境部署完成!
参考
- https://hadoop.apache.org/
- https://blog.csdn.net/xiaolong1155/article/details/131127712

