
- 1洛谷 栈 结构体排序 暴力打表_#2819. [ysf][小数运算]粮食仓库
- 2Mac安装Stable Diffusion详细教程(二):安装与使用Draw Things_draw things无法导入lora
- 3大家都说工作越干越有经验,为啥会有35岁程序员失业危机?_计算机35岁危机是什么意思
- 4【人工智能笔记】第一节:基于Keras的seq2seq聊天机器人实现_python用keras会话机器人
- 5鸿蒙App页面相关_java onactive
- 6Pytorch 了解强化学习(RL)_在pytorch中构建相应的强化学习rl模型
- 7Spring Boot pom文件详解_springboot pom
- 8Flutter 创建项目初体验
- 9如何搭建一个nlp模型_nlp365 nlp论文的第120天总结了一个重要的简单理论模型
- 10Springboot使用RestTemplate请求post的MULTIPART_FORM_DATA接口_resttemplate multipart/form-data
图形注意力网络_iclr什么级别
赞
踩
基本信息
作者
Petar Veličković、 Guillem Cucurull、 Arantxa Casanova、 Adriana Romero、 Pietro Liò
论文等级
ICLR
国际表征学习大会(简称:ICLR),是深度学习领域的顶级会议。
摘要
论文提出了图形注意网络(GAT),一种在图形结构数据上运行的新型神经网络架构,利用掩蔽的自我注意层来解决基于图形卷积或其近似的先前方法的缺点。通过堆叠节点能够参与其邻域特征的层,我们能够(隐式)为邻域中的不同节点指定不同的权重,而不需要任何类型的昂贵的矩阵运算(例如倒置)或取决于图形结构前期。通过这种方式,我们同时解决了基于光谱的图形神经网络的几个关键挑战,并使我们的模型易于适用于归纳和偏置问题。
解决问题:the shortcomings of prior methods based on graph convolutions or their approximations.
图形网络的发展及其问题
基础
卷积神经网络(CNN)已成功用于图像分类,语义分割,机器翻译等方面【基础】
问题
许多有趣的任务涉及无法在网格状结构中表示的数据,而是不规则的,例如3D网格,社交网络,电信网络,生物网络或脑连接等。这些数据通常可以以图形的形式表示。
解决办法
(1)光谱方法:受图形结构影响较大,在特定结构上训练的模型不能直接应用于具有不同结构的图。
(2)非光谱方法(论文所用):引入了基于注意力的体系结构,以执行图形结构化数据的节点分类,使用邻里注意操作来计算环境中不同物体之间的注意力系数。其他相关方法包括局部线性嵌入(LLE)和内存网络(Weston等,2014)。 LLE选择每个数据点周围的固定数量的相邻节点,并了解每个相邻节点的权重系数,以重建每个点作为其相邻节点的加权总和。第二个优化步骤是提取了点的功能嵌入。内存网络还可以与我们的工作共享一些连接,特别是如果我们将节点的邻域解释为内存,用于通过参与其值来计算节点特征,然后通过将新功能存储在该值中来更新相同的位置。
- 【注意力体系】:注意机制的好处之一是,它们允许处理可变大小的输入,重点关注输入中最相关的部分以做出决策。当使用注意机制计算单个序列的表示时,通常被称为自我注意事项或注意力内。自我注意力与复发性神经网络(RNN)或卷积一起,被证明对诸如机器阅读(Cheng等,2016)和学习句子表示(Lin等,2017)的任务有用。注意体系结构具有几个有趣的属性:(1)操作是有效的,因为它在Nodeneighbor对之间是可行的; (2)可以通过向邻居指定任意权重来应用于具有不同程度的图形节点; (3)该模型直接适用于归纳学习问题,包括该模型必须概括到完全看不见的图形的任务。
模型介绍
为了获得足够的表达能力以将输入功能转换为高级特征,至少需要一种可学习的线性转换。为此,作为一个初始步骤,将重量矩阵参数化的共享线性转换应用于每个节点。然后,对节点进行自我注意力 - 共享注意机制A:RF’×RF’→R(计算注意力系数)

图1:左:模型采用的注意机制A(W〜hi,w〜hj),由权重矢量〜a∈R2F’参数化,应用了泄漏的yr ellu激活。右:在其附近的节点1对多头注意(k = 3个头)的插图。不同的箭头样式和颜色表示独立的注意计算。每个头部的聚合特征是连接或平均以获得〜h’1的。右图展示了了多头图注意层的聚合过程。
实验
数据集
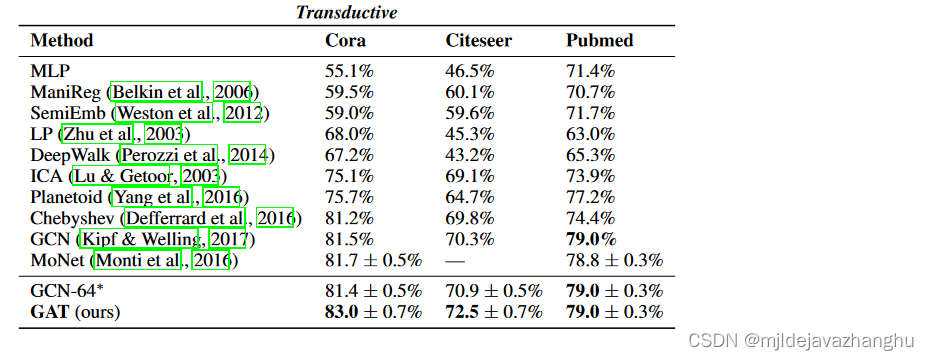
(1)转导学习,利用三个标准的引文网络基准数据集-Cora,Citeseer和PubMed
CORA数据集包含每个节点的2708个节点,5429个边缘,7个类和1433个功能。
Citeseer数据集包含每个节点的3327个节点,4732个边缘,6个类和3703个功能。
PubMed数据集包含19717个节点,44338个边缘,3个类和500个节点的功能。
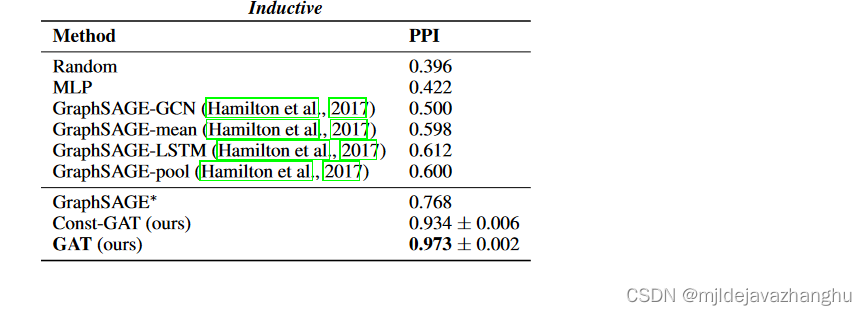
(2)归纳学习我们利用蛋白质蛋白相互作用数据集【protein-protein interaction (PPI) dataset】
该数据集包含20个用于培训的图表,验证2个图表和2个用于测试的图。
验证方法
转导验证:与KIPF&Welling(2017)中指定的相同强大的基线和最先进的方法进行比较。这包括标签传播(LP)(Zhu等,2003),半监督嵌入(Semiemb)(Semiemb)(Weston等,2012),歧管正则化(Manireg)(Belkin等,2006),基于Skip-gram图嵌入(DeepWalk)(Perozzi等,2014),迭代分类算法(ICA)(Lu&Getoor,2003)和Planetoid(Yang等,2016)。我们还直接将模型与GCN(KIPF&Welling,2017)以及利用高阶Chebyshev滤波器(Defferrard等,2016)以及Monti等人介绍的Monet模型进行了比较。
归纳验证:对于归纳学习任务,将汉密尔顿等人介绍的四种不同监督图归纳方法进行比较。 (2017)。这些提供了各种方法来在采样邻域中汇总特征:GraphSage-GCN(将图形卷积风格的操作扩展到电感设置),图形均值(采用特征向量的元素为均值值),graphSage-lstm(通过将邻域特征馈送到LSTM中的聚合)和图形池(将特征向量的最大化操作转换为由共享的非线性多层多层perceptron转换的特征向量的操作)。在电感设置中,其他偏置方法要么是完全不合适的,要么假设节点逐渐添加到单个图中,这使得它们无法在训练过程中完全看不见的设置(例如PPI数据集)。此外,对于这两个任务,都提供了每节点共享的多层感知器(MLP)分类器的性能(根本不整合图结构)。
结论
1.转导
2.归纳
总结(个人)
通过在图形神经网络中添加注意力机制的方法,我们可以以共享的方式将计算点放在图的所有边缘上,以此我们将不再需要要对全图和所有节点进行访问,对于相似度计算我们也以从属性转化到特征上面。但是神经网络的分布式计算将会存在大量的冗余计算,对于cpu的要求也会加大。
论文:Graph Attention Networks
链接: link

