
- 1python环境搭建及Python安装_python3环境搭建和安装
- 2大模型架构创新已死?
- 3远程桌面连接无法全屏显示_todesk连接linux无法全屏
- 4【动手学深度学习】深入浅出深度学习之利用神经网络识别螺旋状数据集
- 5python bp神经网络进行预测_python实现BP神经网络回归预测模型
- 6Scrapy中selenium的应用-----并通过京东图书书籍信息爬取项目进行实操!_使用selenuim爬取京东书籍信息
- 7实时直播流量统计分析及可视化系统————老子明天不加班系列
- 8hadoop高可用【HA】配置详解_配置hadoopha时,定义服务名的配置属性是
- 9SpringBoot集成ElasticSearch 7.9.2 教程和简单增删改查案例(基于ElasticsearchRestTemplate)_org.elasticsearch.index.versiontype
- 10【日常Exception】第二十六回:RedisSystemException...RejectedExecutionException: event executor terminated_org.springframework.data.redis.redissystemexceptio
ICLR 2023 | 如何融合进化算法与强化学习打破性能瓶颈?
赞
踩

©PaperWeekly 原创 · 作者 | 李鹏翼
单位 | 天津大学
研究方向 | 演化强化学习

论文题目:
ERL-Re: Efficient Evolutionary Reinforcement Learning with Shared State Representation and Individual Policy Representation
论文链接:
https://arxiv.org/abs/2210.17375
代码链接:
https://github.com/yeshenpy/ERL-Re2
本次介绍的是由天津大学强化学习实验室(http://icdai.org/)提出新的进化强化学习范式 ERL-Re。该范式充分融合了进化算法与强化学习用于策略优化,并实现了显著的性能增益与效果。
进化算法与与强化学习是两类不同的优化方式,擅长解决不同的优化问题,并且都拥有很大,很活跃的社区,本次介绍的 ICLR 2023 的工作就是为了将两个社区连接起来,充分利用两种不同优化算法各自的优势来实现策略搜索与性能提升 。目前代码已经开源。

Background
强化学习 Reinforcement Learning(RL)可以通过环境试错和梯度更新来高效地学习。然而,众所周知,RL 鲁棒性差,探索性差,并且在梯度信号有噪声和信息量较少(sparse)的情况下,难以高效训练。进化算法 Evolutionary Algorithms(EA)是一类黑箱优化方法,主要是维护一个个体的种群,而不是像 RL 只维护一个个体,通过随机扰动的方式来提升个体获得可行解。
与 RL 不同的是,传统 EA 是无梯度优化方法,并具有几个优点:1)强大的探索能力;2)鲁棒性和稳定的收敛;3)采用累计奖励评价个体,不关心单步奖励,因此对奖励信号不敏感。
尽管有这些优点,EA 的一个主要瓶颈是群体的迭代评估而导致的低样本效率。具体来说,EA 需要种群中的每个个体与环境真实交互来获得适应度(性能表现),最终根据种群中不同个体的适应度来进行种群提升。
很多工作都在研究如何将 EA 和 RL 的融合起来,取长补短,优势互补。其中最具有代表性的当属 2018 年提出的演化强化学习框架(ERL),将 Genetic Algorithm(GA)与 DDPG 进行了融合。除了维护强化学习的 actor 和 critic,ERL 额外维护一个的 actor 的种群。为了融合双方的优点,EA 与环境交互产生的多样性的样本会提供给 RL 用于 off policy 优化,这一方面解决了 EA 样本利用率低的问题,另一方面缓解了 RL 探索弱无法寻找到多样数据的问题。
除此之外,优化后的 RL 策略会定期注入到种群中参与种群进化,如果 RL 策略优于种群策略,那么 RL 策略则会促进种群的进化,否则则会被淘汰掉,不影响种群进化。最终 EA 与 RL 优势互补,在 MuJoCo 上实现了对 DDPG 算法的显著提升。(这里的 EA 演化都是直接在策略的参数上进行扰动优化,例如 k 点交叉是交换两个网络中某些层的参数,变异则直接将高斯扰动添加到网络参数上)

Motivation
ERL 工作后,许多基于 ERL 基本框架的相关工作随之产生,例如 CERL,PDERL,CEM-RL 等。由于都遵循基本的 ERL 框架,导致这些算法都面临着两个基本问题:
所有的策略都单独学习自己的状态表征,维护各自的网络,忽略了有效知识的共享。
对于演化算子,参数层面的策略优化不能保证个体的行为语义,容易造成策略灾难性崩溃。

The Concept of Two-Scale State Representation and Policy Representation
为了解决上述问题,我们提出了基于双尺度表征的策略构建(Two-scale representation-based policy construction)。在此基础上,我们维护和优化 EA 群体和 RL 的策略。具体来说。EA 和 RL Agent 的策略都是由一个共享的非线性状态表征 和一个独立的线性策略表征 组成。Agent 通过结合共享状态表征和策略表征做出决策:
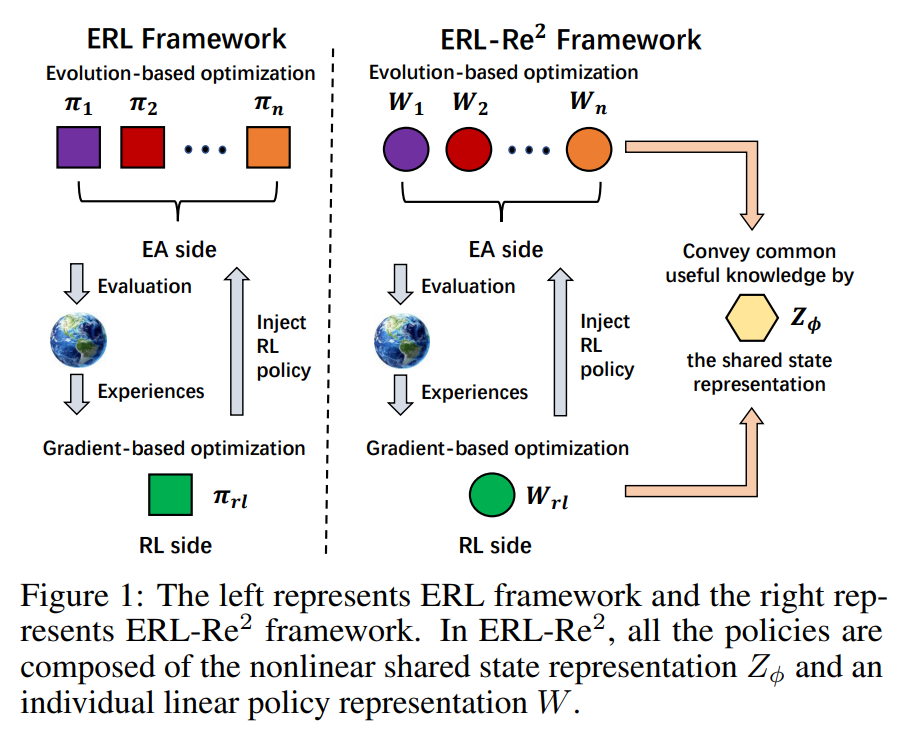
直观地,我们希望共享状态表征 对学习过程中遇到的所有可能的策略都有用。它应该包含环境中与决策有关的一般特征,例如,共同的知识,而不是针对某一个策略。由于共享状态表示 ,Agent 不需要独立地表征状态。因此,更高的效率和更具表现力的状态表征可以通过 EA 群体和 RL Agent 共同得到。由于 的高表达性,每个独立的策略表征可以由一个简单的线性形式构成,这更易于优化与探索。
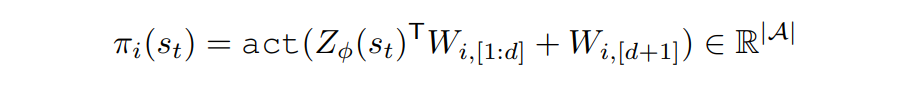
上图是 ERL(及后续工作)与我们提出的双尺度表征框架 ERL-Re² 的对比图。其中左图中的策略主要由传统的非线性神经网络构成。右图中的圆形表示线性策略表征,六边形则表示非线性共享状态表征,用于知识共享。
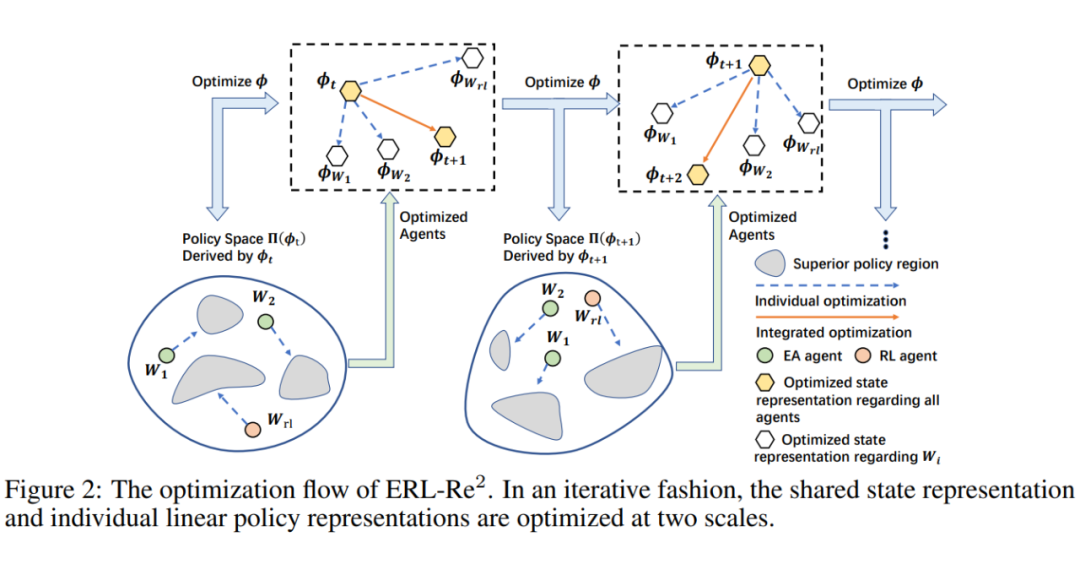
算法优化流程:整体优化流程如上图所示,具体来说,算法每次在由共享状态表征 构建的线性策略空间 中进行策略搜索,对线性策略进行优化。优化后我们对共享状态表征进行优化,优化的方向为对于所有个体(包括 EA 和 RL)都有益的方向,从而达到有效的知识共享,构建对于所有个体都有利的策略空间。如此循环迭代实现知识的高效传递与策略的快速优化。下面我们介绍如何进行共享表征的优化,以及如何在线性空间如何更加高效地演化。

Optimizing the Shared State Representation for A Superior Policy Space
为了构建所有个体都有益的状态表征从而实现高效地知识共享,我们提出基于所有 EA 和 RL 策略的价值函数最大化来学习共享状态表征。对于 EA 策略,我们根据 EA 群体 ℙ 中的线性策略表示 ,学习策略拓展值函数(PeVFA,通过将策略表征作为输入,实现一个价值函数估计多个不同策略 value 的目的)。对于 RL 策略,我们使用原始 RL 算法的值函数提供更新方向。两个值函数都是通过 TD error 进行优化的,损失如下:
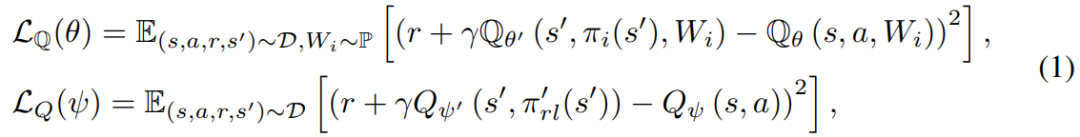
EA 中的个体和 RL 个体都能分别从 PeVFA 和 RL critic 获得各自的优化方向. 而我们想构建的共享状态表征应该有助于所有个体的探索与优化,因此共享表征的更新方向应该考虑到 EA 和 RL,因此我们定义了如下损失:
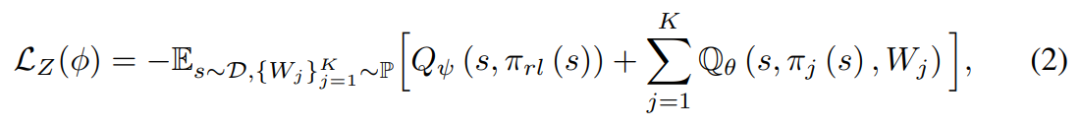
通过优化上述损失,共享状态表征能够向着一个统一的优化方向进行优化,从而构建一个有助于所有个体的线性策略空间,使得 EA 和 RL 能够更加高效地探索与提升。

Optimizing the Policy Representation by Evolution and Reinforcement
对于种群的进化,我们首先需要得到适配度(fitness),所产生的样本开销是 EA 的一个主要瓶颈,特别是当种群很大时。为此,我们提出了一个基于 PeVFA 的新的适应度函数。对于每个 Agent ,我们让 Agent与环境交互
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

