
- 12023年苹果MacBook清理软件哪个好用?CleanMyMac 怎么样?_官网下载的cleanmymac能用多久
- 2M了个J大神的MJRefresh_mjrefreshheader 菊花
- 3uni-app开发小程序实用技巧_uniapp onmounted
- 4C++ 构造,析构顺序(静态对象)_类的静态成员什么时候析构
- 5PG锁浅析_表级锁模式冲突
- 62023阿里最新发布Java后端面试八股文PDF合集,共计1700页_java面试八股文pdf 下载
- 7新手安卓开发详细教程_android软件开发教程
- 8Mac系统配置环境变量保姆级教程
- 9[Day2] IDE DevEco Studio 的环境配置及工程创建_deveco-studio openharmony与harmonyos
- 10鸿蒙应用权限管理和访问控制_鸿蒙系统怎么防止被控制
Chains of Reasoning over Entities, Relations, and Text using Recurrent Neural Networks
赞
踩
Recurrent Neural Networks)
来源
EACL 2017
Rajarshi Das, Arvind Neelakantan, David Belanger, Andrew McCallum
College of Information and Computer Sciences
University of Massachusetts, Amherst
{rajarshi, arvind, belanger, mccallum}@cs.umass.edu
背景
本文主要研究的对象从文本中填充具有不同语义的大规模知识图谱,从文本中填充知识图谱的一个方法是通用模式,学习关系类型的向量表示。填充知识图谱的目的不仅仅为了支撑查阅型的问答,也是通过推理实体以及关系,推断不直接存储在KB中的事实。过去一些基于矩阵补全、张量分解的方法只适合单个边上的操作,我们更期望的是多跳路径进行推理。
Motivation
之前有文章通过RNN对多跳路径进行编码,这种方法代表了使用神经网络对Horn子句链进行复杂推理的一个关键例子,但是对于多个推理来说,这种方法是不准确和不适用的。本文期望提高基于RNN的方法在大型知识图谱上推理的准确性和实用性。本文主要做出了一下几点贡献:
- 本文联合学习和推理关系类型、实体以及实体关系
- 使用注意力机制在多条路径上进行推理
- 只训练一个RNN模型可以预测所有的关系类型
基于RNN的方法
每一步的中间表示
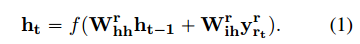
计算路径
π
\pi
π的向量表示
y
π
y_\pi
yπ 与预测关系
r
r
r的向量表示
y
r
y_r
yr的内积
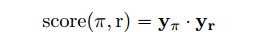
计算实体对
(
e
s
,
e
t
)
(e_s,e_t)
(es,et)参与查询关系
r
r
r的概率
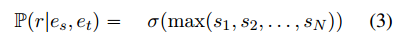
上述基于RNN模型的弊端:
- 对每个关系训练一个模型是不实用的,理想是训练一个模型可以预测所有的关系
- 上面使用取最大的方法是不合理的,浪费计算资源,利用率低
- 上面的模型忽略了路径上的实体信息
本文改进
共享参数
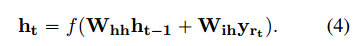
打分函数
{
s
1
,
s
2
,
.
.
.
,
s
N
}
\{s_1,s_2,...,s_N\}
{s1,s2,...,sN} 表示
N
N
N条路径的打分
- TopK
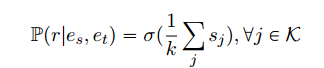
- 平均:
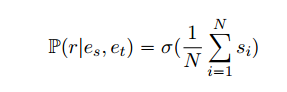
- LogSumExp:
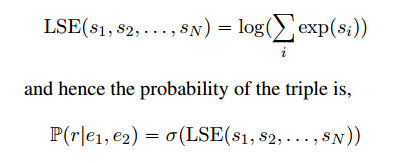
mark:
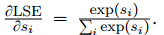
每条路径都将获得与其得分成比例的梯度份额,因此这是梯度步骤中的一种注意力
加入实体信息:
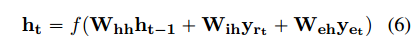
训练:
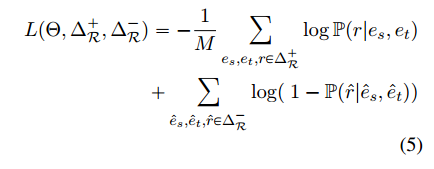
M
M
M是所有的训练样例的个数,
Δ
R
+
\Delta^+_R
ΔR+ 表示所有的正例,
Δ
R
−
\Delta^-_R
ΔR−是 负例
实验部分
1、pooling 的影响

2. 比较多跳模型以及加入实体信息的影响

3. 有限数据集上的表现

4 路径查询


