
热门标签
热门文章
- 1OpenHarmony的前世今生_open harmony 的前世今生
- 2Linux基本操作命令_xshell登录成功后,绿色光标前面有哪些内容,分别代表什么意思?
- 3论题:基于深度学习的图像识别系统_基于深度学习的图像智能识别系统的研发立项目的
- 4C++文件操作
- 5PyTorch 预训练模型,保存,读取和更新模型参数以及多 GPU 训练模型(转载 极市平台)_model(imgpath, conf=0.7, save=false, stream=false)
- 6基于Thinkphp+uniapp开发的课程预约小程序系统_thinkphp6+uniapp项目
- 7【nRF Connect】七、参数请求和属性读取_n rf connect prepare write 如何使用
- 8PyTorch学习笔记(五):模型定义、修改、保存_module的权重
- 9ajax实现异步刷新分页,Ajax异步刷新分页功能-MySQL
- 10adb命令整理大全_adb命令大全
当前位置: article > 正文
HiFi-GAN: Generative Adversarial Networks for Efficient and High Fidelity Speech Synthesis
作者:我家自动化 | 2024-03-18 09:51:56
赞
踩
hifi-gan: generative adversarial networks for efficient and high fidelity sp
会议:2020 NIPS
单位:韩国KAKAO
作者:Jungil Kong, Jaehyeon Kim
文章主页
开源代码
- 使用心得:
- hifigan的收敛速度和效果都比PWG要好一点;
- hifigan预测真实值表现良好,但是和声学模型接在一起之后有电音(杂音),主要是两个系统的mismatch(真实mel-spec和预测的mel-spec之间的差异)
- 2的解决方法:声学模型预测的更精准一些;vocoder用一些predict-mel训练,增强泛化性。
abstract
motivation:在推理时间 & 生成高保真音质方面均作出改进
- 观点:modeling periodic patterns of an audio is crucial
- 结果:22.05k的单人音频生成质量和录制语音接近;优点全CNN网络,前向推理速度非常快
HiFi-GAN
包括一个生成器和两个判别器(multi-scale & multi-period),
生成器结构
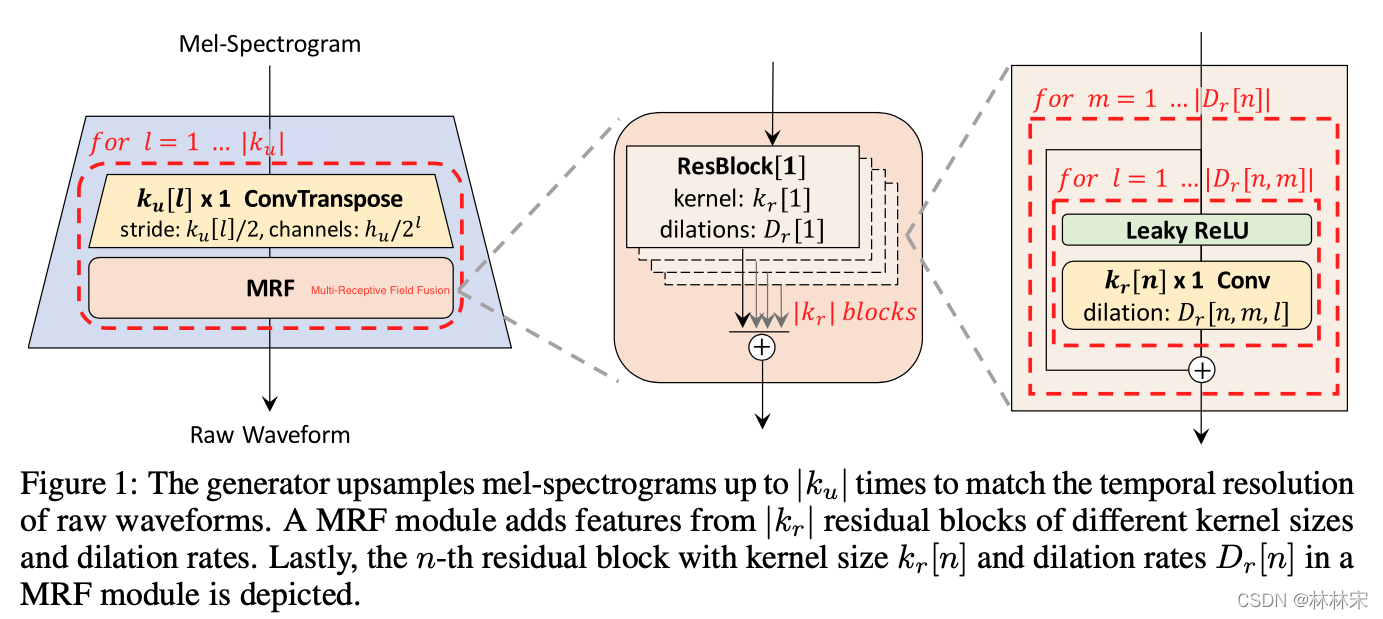
- ConvTranspose:输入mel-spec,通过卷积上采样到和wav采样点同等长度;
- multi-receptive field fusion (MRF) module:res-block conv,作者设置了四种不同长度的生成器,可通过调节参数实现合成效率 & 生成质量的平衡。
MSD: multi-scale discriminator
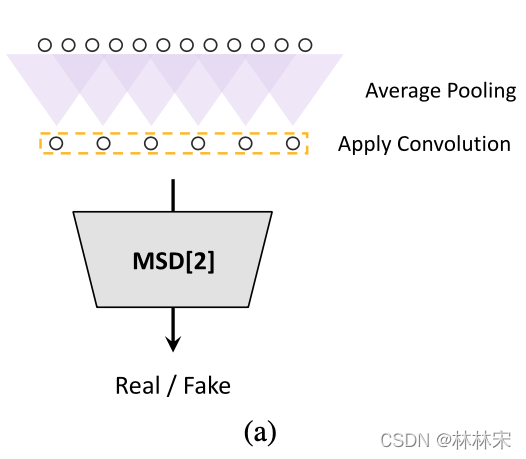
- 因为MPD是对信号重采样为不同的周期(离散点进行判断),因此加入MSD对连续点语音进行判别;
- MSD包含三个子判别器:对连续的语音采样点进行建模,分别建模原始语音,✖️2 average-pooled audio,✖️4 average-pooled audio。是对平滑后波形的判断。
MPD:multi-period discriminator
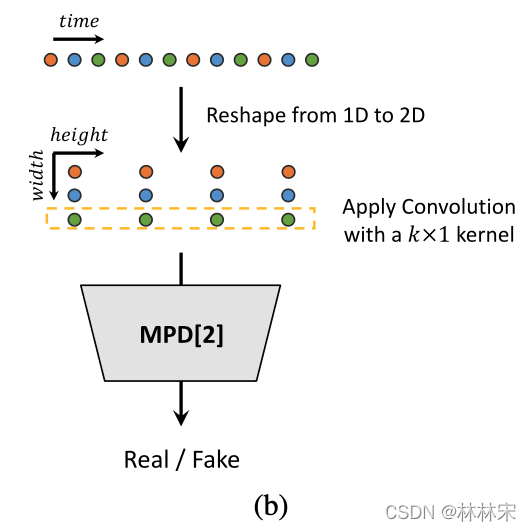

-
- motivation:语音由不同的周期信号组成,重建语音数据需要对不同的周期模式进行建模。
- 对不连续的采样点进行建模,设置素数【2,3,5,7,11】为不同的period,按照period将音频采样点reshape为二维信号,然后用卷积单独处理周期重采样后的信号。
- 如上图所示:可以看成大周期sin signal+小周期sin signal,不同的采样间隔建模到不同周期的信号。
目标函数

- Feature Matching Loss:衡量判别器对于真实样本和生成样本预测的结果偏差
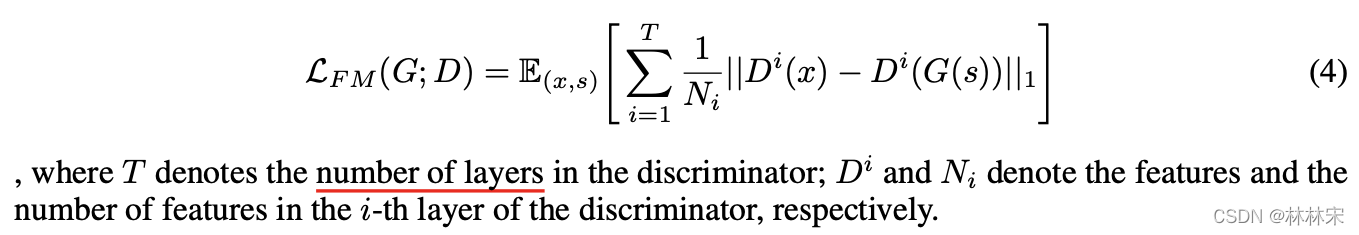
experiments
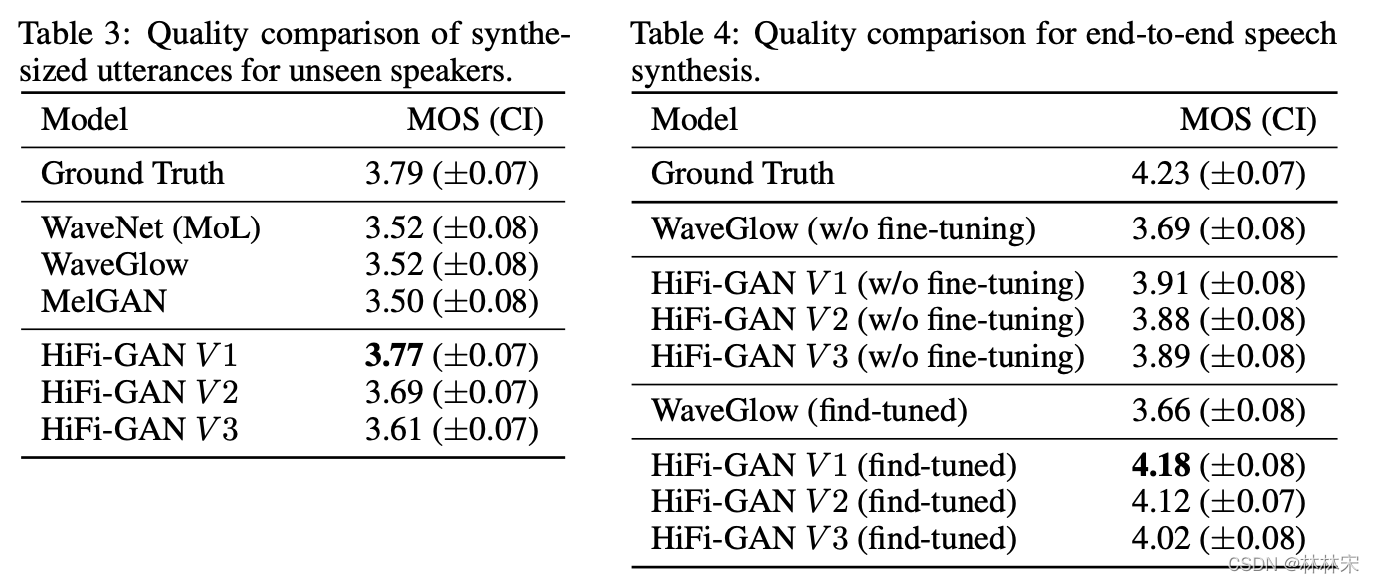
- 对比1:LJSpeech的效果,baseline选择官方开源的WaveNet,WaveGlow,MelGAN
- 对于unseen speaker的泛化效果:VCTK数据集,9个人作为unseen speaker,剩下的用于训练WaveNet,WaveGlow,MelGAN, hifigan
- 为了对比合成质量和合成速度,分别设置三组参数V1,V2,V3,参数量依次越来越小;

ablation study
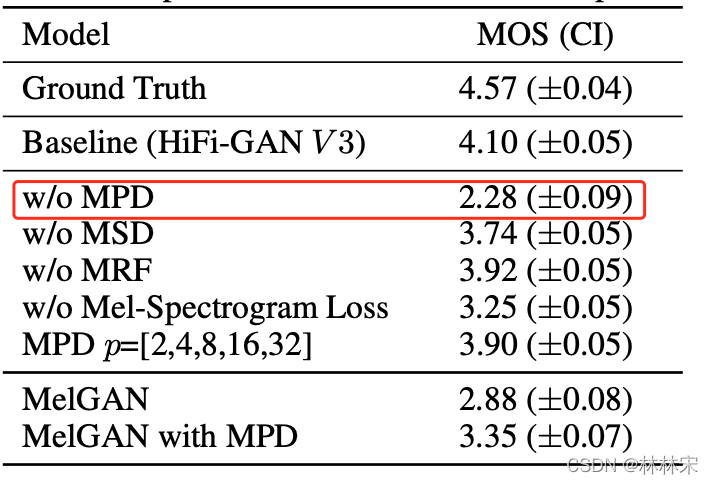
- MPD模块对结果的改善最显著
unseen speaker的泛化
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/我家自动化/article/detail/262175
推荐阅读
相关标签

