
热门标签
热门文章
- 1ue4场景没阴影_[官方直播预告] 第13期 | UE4体积雾深入实战
- 2Layui下拉框和ECharts图表动态结合_js echarts 有哪个属性可以配置生成一个下拉框
- 3Wifi 认证,关联,四次握手(WPA-WPA2-WPA3-SAE)_wifi四次握手
- 4linux防火墙查看状态firewall、iptable_linux查看防火墙状态命令
- 5智慧金融新视野:银行数据中心可视化大屏的崛起
- 6Jieba进行词频统计与关键词提取_java jieba提取关键词
- 7flutter 图解_Flutter自绘组件:微信悬浮窗(一)
- 8完全图解GPT-2:看完这篇就够了(一)_gpt自回归损失
- 9jdbc中mysql的url格式_mysql的jdbcurl
- 10芯片全流程培训
当前位置: article > 正文
真正帮你实现—MapReduce统计WordCount词频,并将统计结果按出现次数降序排列_mapreduce降序输出
作者:小桥流水78 | 2024-06-22 23:17:17
赞
踩
mapreduce降序输出
项目整体介绍
对类似WordCount案例的词频统计,并将统计结果按出现次数降序排列。
网上有很多帖子,均用的相似方案,重写某某方法然后。。。运行起来可能会报这样那样的错误,这里实现了一种解决方案,分享出来供大家参考:编写两个MapReduce程序,第一个程序进行词频统计,第二个程序进行降序处理,由于是降序,还需要自定义对象,在对象内部实现降序排序。
一、项目背景及数据集说明
现有某电商网站用户对商品的收藏数据,记录了用户收藏的商品id以及收藏日期,名为buyer_favorite1。buyer_favorite1包含:买家id,商品id,收藏日期这三个字段,数据以“\t”分割,样例展现如下: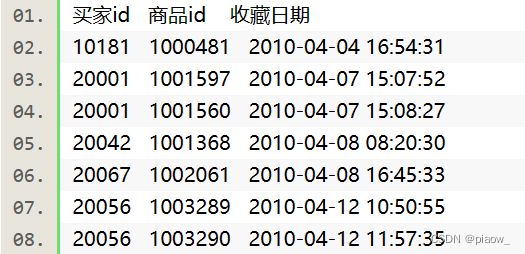
二、编写MapReduce程序,统计每个买家收藏商品数量。(即统计买家id出现的次数)
前置说明
1.配置好Hadoop集群环境,并开启相应服务、
2.在hdfs对应路径上先上传好文件,可以自己根据文件路径定义,这里是"hdfs://localhost:9000/mymapreduce1/in/buyer_favorite1"。同时再定义好输出路径
3.这里是整个程序(词频降序)的入口,若只是想统计词频,请注释掉WordCountSortDESC.mainJob2();
package mapreduce; import java.io.IOException; import java.util.StringTokenizer; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.*; import org.apache.hadoop.mapreduce.*; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; public class WordCount { public static void main(String[] args) { Configuration conf = new Configuration(); conf.set("yarn,resourcemanager", "bym@d2e674ec1e78"); try { Job job = Job.getInstance(conf, "111"); job.setJobName("WordCount"); job.setJarByClass(WordCount.class); job.setMapperClass(doMapper.class); // 这里就是设置下job使用继承doMapper类,与定义的内容保持一致 job.setReducerClass(doReducer.class); // 同上,设置Reduce类型 job.setMapOutputKeyClass(Text.class); // 如果map的输出和reduce的输出不一样,这里要分别定义好格式 job.setMapOutputValueClass(IntWritable.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(Text.class); Path in = new Path( "hdfs://localhost:9000/mymapreduce1/in/buyer_favorite1"); Path out = new Path("hdfs://localhost:9000/mymapreduce1/out"); FileInputFormat.addInputPath(job, in); FileOutputFormat.setOutputPath(job, out); if (job.waitForCompletion(true)) { System.out.println("WordCount completition"); WordCountSortDESC.mainJob2(); System.out.println("diaoyong"); } } catch (Exception e) { e.printStackTrace(); } // System.exit(job.waitForCompletion(true) ? 0 : 1); } // 第一个Object表示输入key的类型、是该行的首字母相对于文本文件的首地址的偏移量; // 第二个Text表示输入value的类型、存储的是文本文件中的一行(以回车符为行结束标记); // 第三个Text表示输出键的类型;第四个IntWritable表示输出值的类型 public static class doMapper extends Mapper<LongWritable, Text, Text, IntWritable> { public static final IntWritable one = new IntWritable(1); public static Text word = new Text(); @Override // 前面两个Object key,Text value就是输入的key和value,第三个参数Context // context是可以记录输入的key和value。 protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { // StringTokenizer是Java工具包中的一个类,用于将字符串进行拆分 StringTokenizer tokenizer = new StringTokenizer(value.toString(), "\t"); // 返回当前位置到下一个分隔符之间的字符串, 并把字符串设置成Text格式 word.set(tokenizer.nextToken()); context.write(word, one); } } // 参数依次表示是输入键类型,输入值类型,输出键类型,输出值类型 public static class doReducer extends Reducer<Text, IntWritable, Text, Text> { @Override // 输入的是键值类型,其中值类型为归并后的结果,输出结果为Context类型 protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException { int sum = 0; for (IntWritable value : values) { sum += value.get(); } context.write(key, new Text(Integer.toString(sum))); } } }

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
三、核心问题:再次编写MapReduce程序,将上一步统计的结果降序排列
前置说明
1.这里将上一步统计的结果作为输入,进行第二次mapreduce程序的运行。因此要注意输入路径与上一步的输出路径保持一致。
2.由于是降序排列,只能自定义FlowBean对象,内部实现排序方式。否则,升序可以利用shuffle机制默认的排序策略不用自定义对象排序,这里不再叙述。
package mapreduce; import java.io.DataInput; import java.io.DataOutput; import java.io.IOException; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.*; import org.apache.hadoop.mapreduce.*; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.input.FileSplit; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; public class WordCountSortDESC { public static void mainJob2() { Configuration conf = new Configuration(); conf.set("yarn,resourcemanager", "bym@d2e674ec1e78"); try { Job job = Job.getInstance(conf, "1111"); job.setJobName("WordCountSortDESC"); job.setJarByClass(WordCountSortDESC.class); job.setMapperClass(TwoMapper.class); // 这里就是设置下job使用继承doMapper类,与定义的内容保持一致 job.setReducerClass(TwoReducer.class); // 同上,设置Reduce类型 job.setMapOutputKeyClass(FlowBean.class); job.setMapOutputValueClass(Text.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(FlowBean.class); Path in = new Path("hdfs://localhost:9000/mymapreduce1/out"); Path out = new Path("hdfs://localhost:9000/mymapreduce1/out555"); FileInputFormat.addInputPath(job, in); FileOutputFormat.setOutputPath(job, out); if (job.waitForCompletion(true)) { System.out.println("DESC Really Done"); } } catch (Exception e) { System.out.println("errormainJob2-----------"); } } public static class TwoMapper extends Mapper<Object, Text, FlowBean, Text> { private FlowBean outK = new FlowBean(); private Text outV = new Text(); @Override protected void map(Object key, Text value, Context context) throws IOException, InterruptedException { // 由于真实的数据存储在文件块上,这里是因为数据量较小,可以保证只在一个文件块 FileSplit fs = (FileSplit) context.getInputSplit(); if (fs.getPath().getName().contains("part-r-00000")) { // 1 获取一行数据 String line = value.toString(); // 2 按照"\t",切割数据 String[] split = line.split("\t"); // 3 封装outK outV outK.setNumber(Long.parseLong(split[1])); outV.set(split[0]); // 4 写出outK outV context.write(outK, outV); } else { System.out.println("error-part-r-------------------"); } } } public static class TwoReducer extends Reducer<FlowBean, Text, Text, FlowBean> { @Override protected void reduce(FlowBean key, Iterable<Text> values, Context context) throws IOException, InterruptedException { // 遍历values集合,循环写出,避免总流量相同的情况 for (Text value : values) { // 调换KV位置,反向写出 context.write(value, key); } } } public static class FlowBean implements WritableComparable<FlowBean> { private long number; // 提供无参构造 public FlowBean() { } public long getNumber() { return number; } public void setNumber(long number) { this.number = number; } // 实现序列化和反序列化方法,注意顺序一定要一致 @Override public void write(DataOutput out) throws IOException { out.writeLong(this.number); } @Override public void readFields(DataInput in) throws IOException { this.number = in.readLong(); } @Override public String toString() { return number + "\t"; } @Override public int compareTo(FlowBean o) { // 按照总流量比较,倒序排列 if (this.number > o.number) { return -1; } else if (this.number < o.number) { return 1; } else { return 0; } } } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
四、结果展示:
执行查看文件命令
hadoop fs -cat /mymapreduce1/out555/part-r-00000
- 1

可以发现已经进行了降序排列,其他数据集结果应类似。
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/小桥流水78/article/detail/747942
推荐阅读
相关标签

