
- 1uniapp 使用安卓模拟器运行调试_uniapp 安卓模拟器调试
- 2全球搜索引擎Top10 可惜很多人只用过第四个_fj111飞机馆全球最大
- 3解决 Android studio 第一次创建项目卡在下载东西、加载过慢的问题_新建了android项目左下角加载很慢
- 4揭秘AI芯片巨头:CPU、GPU、FPGA、ASIC特性与优劣对比_asic芯片和全定制芯片
- 5华为数通企业面试笔试实验题_dns租期为8小时
- 6乡村振兴战略下农产品跨境电商发展路径研究_据权威统计数据显示,2019年全球农产品跨境电商市场的总规模已达到惊人的3500亿美
- 7记最近一次Nodejs全栈开发经历_nodejs 开发思维
- 8Autodesk AutoCAD 2025 for mac(cad设计绘图软件) v2025中文版_autocadformac
- 9Flink快速入门--安装与示例运行_flink 运行示例程序
- 10SQLServer -- 自定义无参数存储过程_sqlserver 存储过程无参数
深度学习二 —— 手撕激活函数(阶跃函数、sigmoid、tanh、ReLu、Leaky ReLu)_深度学习经典公式sigmod与tanh
赞
踩
手撕激活函数
1. 阶跃函数
公式
s t e p ( x ) = { 1 i f x > 0 0 i f x ≤ 0 step(x) = {1ifx>00ifx≤0 step(x)={1ifx>00ifx≤0

代码
import numpy as np
def step_function(x):
return np.array(x > 0, dtype=np.int)
- 1
- 2
- 3
2. sigmoid
公式
s i g m o i d ( x ) = 1 1 + e − x sigmoid(x) = \frac{1}{1 + e^{-x}} sigmoid(x)=1+e−x1
y的取值范围 ( 0 , 1 ) (0, 1) (0,1)

代码
import numpy as np
def sigmoid(x):
return 1. / (1 + np.exp(-x))
- 1
- 2
- 3
3. 阶跃函数 与 sigmoid函数比较

相同点
- 输入小的时候,输出接近0,或者为0;随着输入增大,输出会向1靠近,或者为1
- 不管输入信号的大小,输出均在 [ 0 , 1 ] [0, 1] [0,1]
不同点
- 平滑性不同,sigmoid可以返回 [ 0 , 1 ] [0, 1] [0,1]之间的所有实数,阶跃函数只能返回0或1的信号值。
- 由上可知,感知机中神经元之间流动的是0或1的信号值,而神经网络之间流动的是连续的实数值信号。
4. tanh 函数
公式
t a n h ( x ) = e x − e − x e x + e − x tanh(x)=\frac{e^x-e^{-x}}{e^x+e^{-x}} tanh(x)=ex+e−xex−e−x
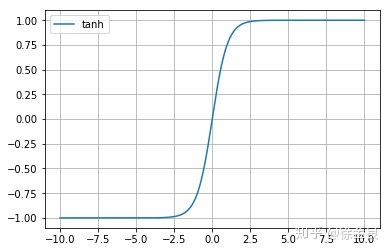
代码
import numpy as np
def tanh(x):
return (np.exp(x) - np.exp(-x)) / (np.exp(x) + np.exp(-x))
- 1
- 2
- 3
5. sigmoid 和 tanh的缺陷
sigmoid和tanh具有共同的缺陷,即:在x很大或者很小时,梯度几乎为0,因此使用梯度下降的优化算法更新网络会很慢。
也正因为这个缺陷,ReLu成为目前大多数神经网络的默认选择。
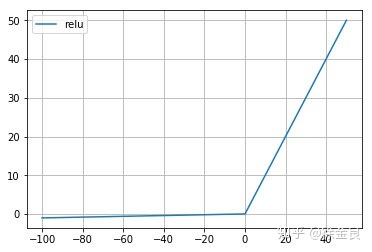
6. ReLu 函数
公式
R e L u ( x ) = { x i f x > 0 0 i f x ≤ 0 ReLu(x) = {xifx>00ifx≤0 ReLu(x)={xifx>00ifx≤0

代码
import numpy as np
def relu(x):
return np.maximum(0, x)
- 1
- 2
- 3
ReLu的缺点
ReLu的缺点:当 x < 0 x<0 x<0时,斜率即导数为0,因此引申出leaky relu函数,但是实际上leaky relu使用的并不多。
7. leaky ReLu 函数
公式
L R e L u ( x ) = { 0.01 x i f x < 0 x i f x ≤ 0 LReLu(x)={0.01xifx<0xifx≤0 LReLu(x)={0.01xifx<0xifx≤0
代码
import numpy as np
def LReLu(x):
return maximum(0.01 * x, x)
- 1
- 2
- 3

