
大数据技术原理与应用实验指南——MapReduce词频统计_利用mapreduce模型对一个包含3行文字的文本文件进行词频统计。文本内容 如下: . d
赞
踩
大数据技术原理与应用实验指南——MapReduce词频统计
1. 实验目的
(1) 理解Hadoop中MapReduce模块的处理逻辑。
(2) 熟悉MapReduce编程。
2. 实验内容
(1) 在电脑上新建文件夹input,并在其中创建三个指定文件名的文本文件,并将特定内容存入三个文本。
(2) 启动Hadoop伪分布式,将input文件夹上传到HDFS上。
(3) 编写MapReduce程序,实现单词出现次数统计。统计结果保存到hdfs的output文件夹。获取统计结果(给出截图或相关结果数据)。
3. 实验平台(软件版本)
4. 实验步骤
实验步骤的思维导图如下图所示
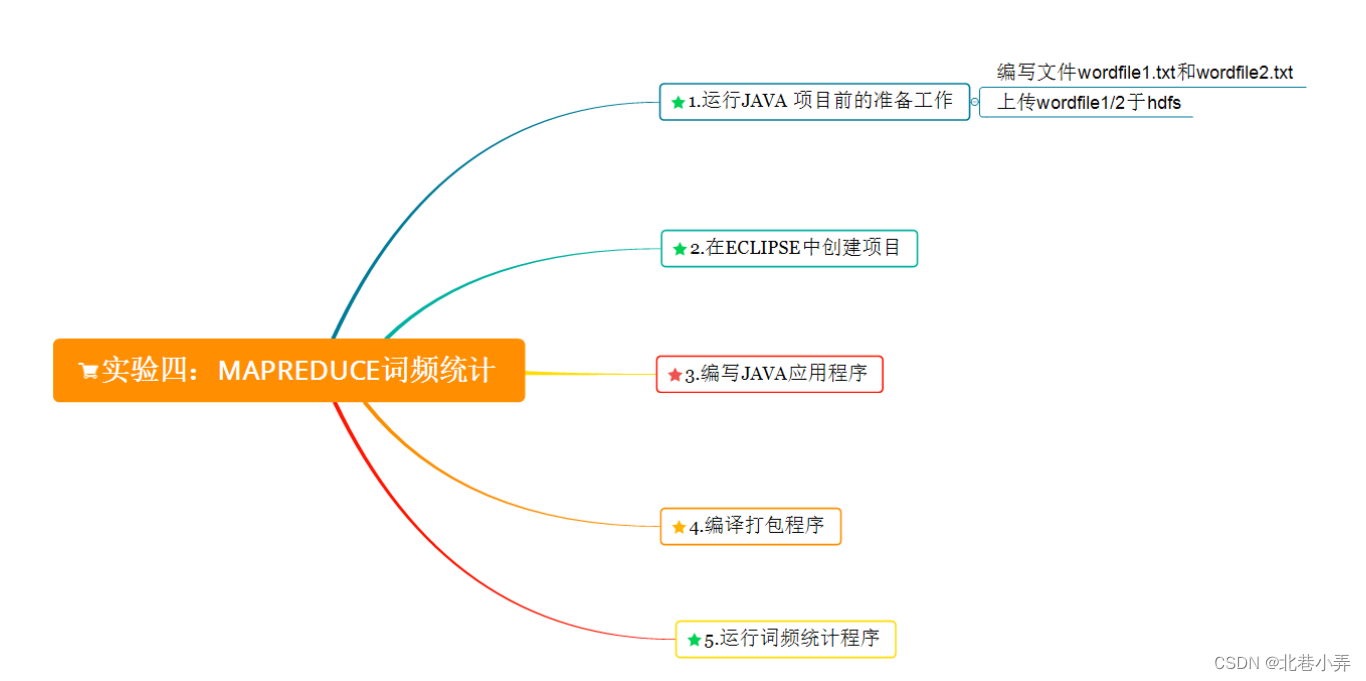
(1) 运行java 项目前的准备工作
① 在Linux系统本地创建两个文件,即文件wordfile1.txt和wordfile2.txt。
文件内容如图所示:
文件wordfile1.txt的内容如下:
I love Spark
I love Hadoop
- 1
- 2
文件wordfile2.txt的内容如下:
Hadoop is good
Spark is fast
- 1
- 2
② 编写两个文件的程序代码如下:
$ cd ~
$ sudo vim wordfile1.txt
$ sudo vim wordfile2.txt
- 1
- 2
- 3
③ 将这两个文件上传到HDFS 的/user/hadoop/input文件夹下,如果没有input文件请先创建,代码如下:
$ cd ~
$ hdfs dfs -mkdir input
$ hdfs dfs -put wordfile1.txt input
$ hdfs dfs -put wordfile2.txt input
$ hdfs dfs -ls .#展示所创的文件
- 1
- 2
- 3
- 4
- 5
以上步骤的代码及其执行过程如下图所示:
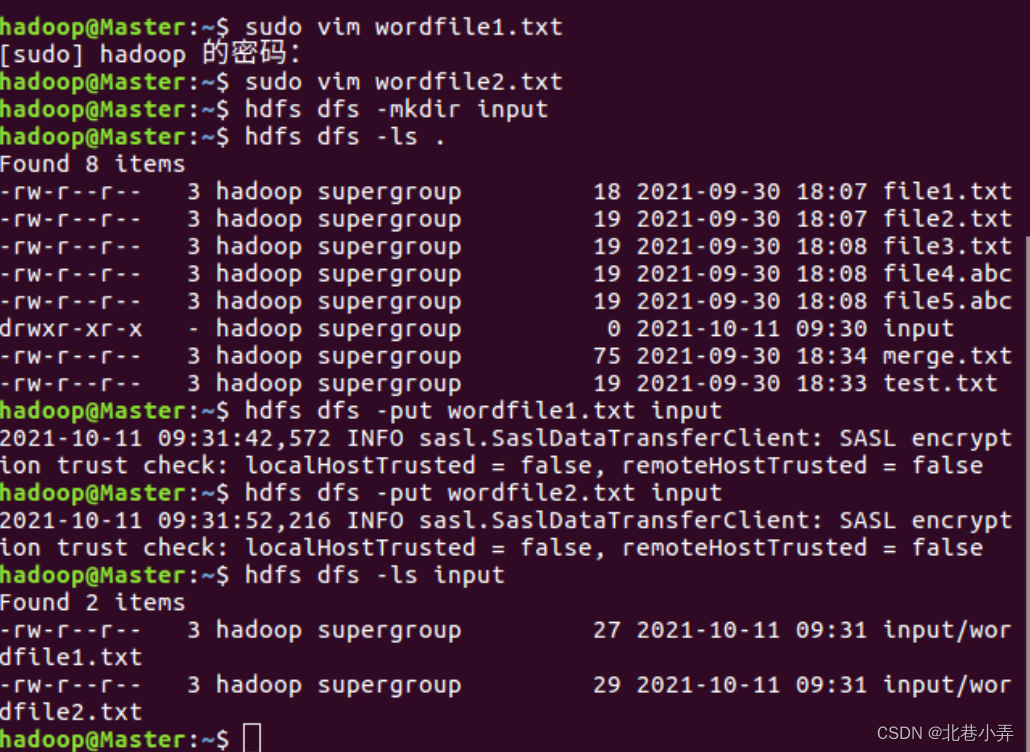
(2) 在Eclipse中创建项目
① 首先,启动Eclipse
$ cd /usr/local/eclipse
$ ./eclipse
- 1
- 2
这样就可以看到启动界面,如下图所示:提示设置工作空间(workspace)
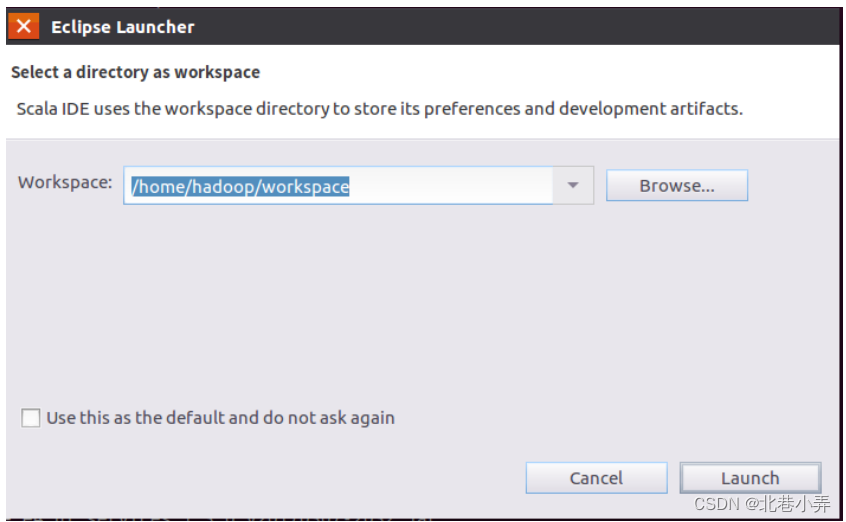
可以直接采用默认的设置“/home/hadoop/workspace”,点击“OK”按钮。可以看出,由于当前是采用hadoop用户登录了Linux系统,因此,默认的工作空间目录位于hadoop用户目录“/home/hadoop”下。
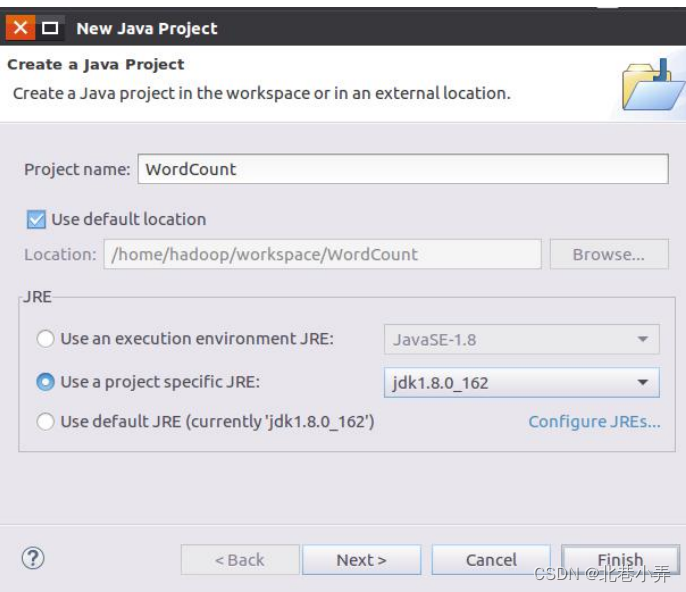
② Eclipse启动以后,选择“File–>New–>Java Project”菜单,开始创建一个Java工程,会弹出如下图所示界面。
③ 点击界面底部的“Next>”按钮,为项目添加需要用到的JAR包,包含mapreduce和mapreduce/lib与common(目录下的hadoop-common-3.1.3.jar和haoop-nfs-3.1.3.jar)或者common/lib,还有client下所有的JAR包这些JAR包都位于Linux系统的Hadoop安装目录下,对于本教程而言,就是在“/usr/local/hadoop/share/hadoop”目录下。点击界面中的“Libraries”选项卡,然后,点击界面右侧的“Add External JARs…”按钮,会弹出如下图所示界面。
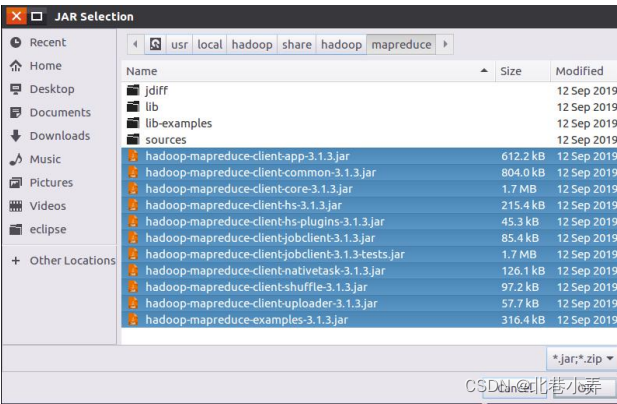
全部添加完毕以后,就可以点击界面右下角的“Finish”按钮,完成Java工程WordCount的创建。
(3) 编写Java应用程序
① 选择“New–>Class”菜单创建类以后会出现如下图所示界面。
② 完成创建类后,编写代码WordCount.java如下:
代码实现的思维导图:如下
import java.io.IOException; import java.util.Iterator; import java.util.StringTokenizer; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.Mapper; import org.apache.hadoop.mapreduce.Reducer; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; import org.apache.hadoop.util.GenericOptionsParser; public class WordCount { public WordCount() { } public static void main(String[] args) throws Exception { Configuration conf = new Configuration();//设置程序运行时参数 String[] otherArgs = (new GenericOptionsParser(conf, args)).getRemainingArgs(); if(otherArgs.length < 2) { System.err.println("Usage: wordcount <in> [<in>...] <out>"); System.exit(2); } Job job = Job.getInstance(conf, "word count");//设置环境参数 job.setJarByClass(WordCount.class);//设置整个程序的类名 job.setMapperClass(WordCount.TokenizerMapper.class);//添加用户定义好的map处理逻辑:TokenizerMapper类 job.setCombinerClass(WordCount.IntSumReducer.class);//添加用户定义好的shuffle中conbine(合并)处理逻辑:IntSumReducer类 job.setReducerClass(WordCount.IntSumReducer.class);//添加用户定义好的reduce处理逻辑:IntSumReducer类 job.setOutputKeyClass(Text.class);//设置键输出类型 job.setOutputValueClass(IntWritable.class); //设置值输出类型 for(int i = 0; i < otherArgs.length - 1; ++i) { FileInputFormat.addInputPath(job, new Path(otherArgs[i]));//设置输入文件 } FileOutputFormat.setOutputPath(job, new Path(otherArgs[otherArgs.length - 1]));//设置输出文件 System.exit(job.waitForCompletion(true)?0:1);//提交作业 } /*自定义一个继承Mapper的类TokenizerMapper用于实现Map的处理逻辑 即对于输入文本处理后输出 <key,value>形式*/ /*问题1:重写map()时,其里面的参数如何解释? *问题2:对于以下类中的所有新的变量的声明作何详细解释??它们的用法?比如:word.set() ? */ public static class TokenizerMapper extends Mapper<Object, Text, Text, IntWritable> { private static final IntWritable one = new IntWritable(1);//声明一个IntWritable类型的变量 private Text word = new Text();//解析出来的每一个单词使用Text类型进行存储 public TokenizerMapper() { }//构造函数 //接下来,重写map函数实现自己需求 public void map(Object key, Text value, Mapper<Object, Text, Text, IntWritable>.Context context) throws IOException, InterruptedException { StringTokenizer itr = new StringTokenizer(value.toString()); //StringTokenizer为分词器:帮助把一行文本切分成多个单词,它的输入需要为字符串类型 while(itr.hasMoreTokens()) {//从分词器中取出来每一个单词并输出map函数需要的形式:<key,value>的形式 this.word.set(itr.nextToken()); context.write(this.word, one);//输出键值对:<word,1> } } } /*问题1:iterable容器是啥? 问题2:Reducer类的参数? */ public static class IntSumReducer extends Reducer<Text, IntWritable, Text, IntWritable> { private IntWritable result = new IntWritable();//用于定义一个可以存储单词词频汇总的变量 public IntSumReducer() { }//构造函数 public void reduce(Text key, Iterable<IntWritable> values, Reducer<Text, IntWritable, Text, IntWritable>.Context context) throws IOException, InterruptedException { int sum = 0; IntWritable val; for(Iterator i$ = values.iterator(); i$.hasNext(); sum += val.get()) { val = (IntWritable)i$.next(); } this.result.set(sum); context.write(key, this.result); } } }

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
(4) 编译打包程序
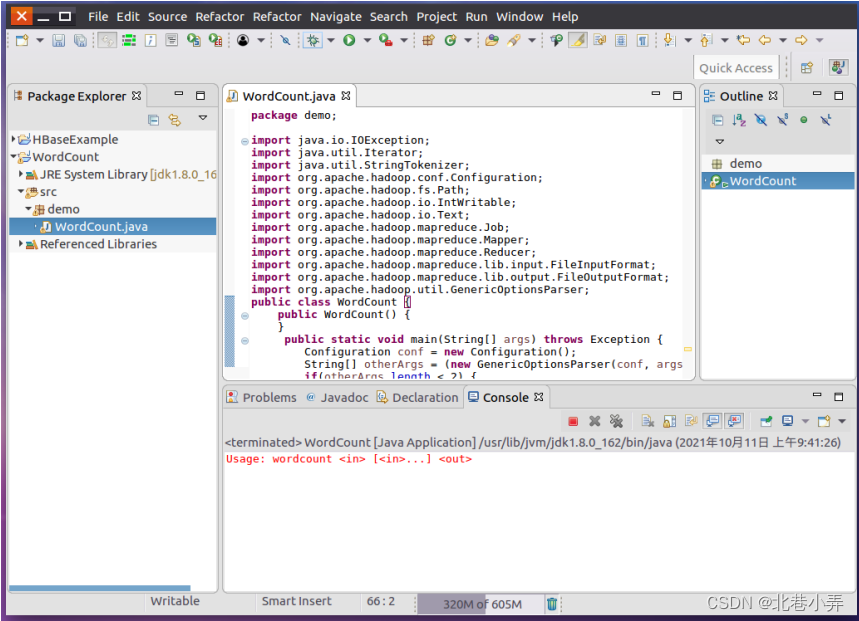
① 现在就可以编译上面编写的代码。可以直接点击Eclipse工作界面上部的运行程序的快捷按钮,当把鼠标移动到该按钮上时,在弹出的菜单中选择“Run as”,继续在弹出来的菜单中选择“Java Application”
运行结果如下图所示
② 下面就可以把Java应用程序打包生成JAR包,部署到Hadoop平台上运行。现在可以把词频统计程序放在“/usr/local/hadoop/myapp”目录下。如果该目录不存在,可以使用如下命令创建:
$ cd /usr/local/hadoop
$ mkdir myapp
- 1
- 2
③ 首先,请在Eclipse工作界面左侧的“Package Explorer”面板中,在工程名称“WordCount”上点击鼠标右键,在弹出的菜单中选择“Export”,如下图所示。
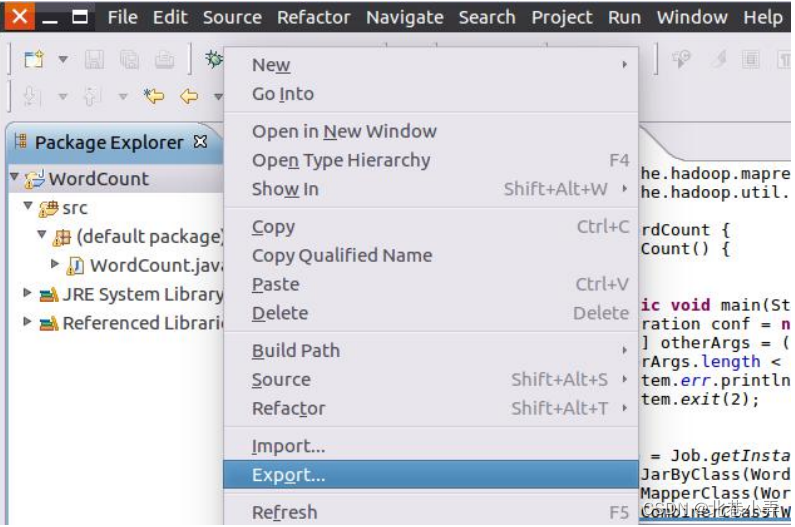
④ 然后,会弹出如下图所示界面
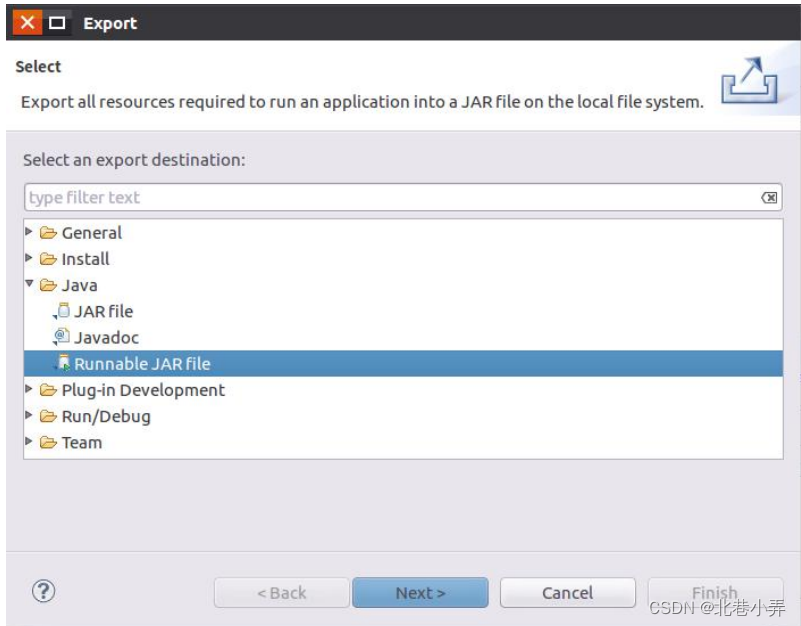
⑤ 在该界面中,选择“Runnable JAR file”,然后,点击“Next>”按钮,弹出如下图所示界面。
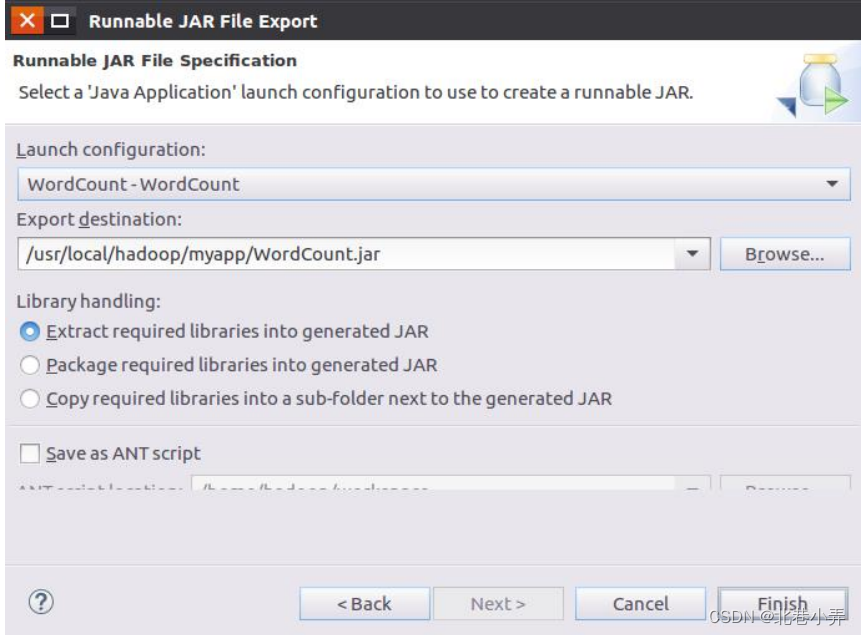
⑥ 在该界面中,“Launch configuration”用于设置生成的JAR包被部署启动时运行的主类,需要在下拉列表中选择刚才配置的类“WordCount-WordCount”。在“Export destination”中需要设置JAR包要输出保存到哪个目录,比如,这里设置为“/usr/local/hadoop/myapp/WordCount.jar”。在“Library handling”下面选择“Extract required libraries into generated JAR”。然后,点击“Finish”按钮,会出现如下图所示界面。
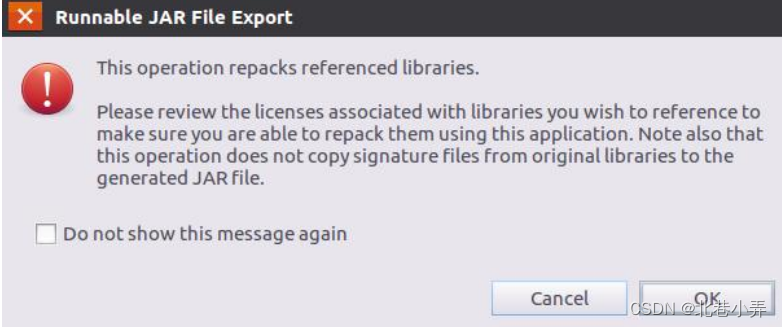
⑦ 可以忽略该界面的信息,直接点击界面右下角的“OK”按钮,启动打包过程。打包过程结束后,会出现一个警告信息界面,如下图所示。
可以忽略该界面的信息,直接点击界面右下角的“OK”按钮。至此,已经顺利把WordCount工程打包生成了WordCount.jar。
⑧ 可以到Linux系统中查看一下生成的WordCount.jar文件,可以在Linux的终端中执行如下命令:
$ cd /usr/local/hadoop/myapp
$ ls
- 1
- 2
成功打包结果如下图所示:
(5) 运行程序
① 在运行程序之前,需要启动Hadoop集群,命令如下:
$ start-dfs.sh
$ start-yarn.sh
$ mr-jobhistory-daemon.sh start historyserver
- 1
- 2
- 3
② 在启动Hadoop之后,需要首先删除HDFS中与当前Linux用户hadoop对应的output目录(即HDFS中的“/user/hadoop/output”目录),这样确保后面程序运行不会出现问题,具体命令如下:
$ hdfs dfs -rm -r /user/hadoop/output
- 1
③ 现在,就可以在Linux系统中,使用hadoop jar命令运行程序,命令如下:
$ cd /usr/local/hadoop
$ hadoop jar ./myapp/WordCount.jar input output
- 1
- 2
上面命令执行以后,当运行顺利结束时,屏幕上会显示类似如下(部分)的信息:

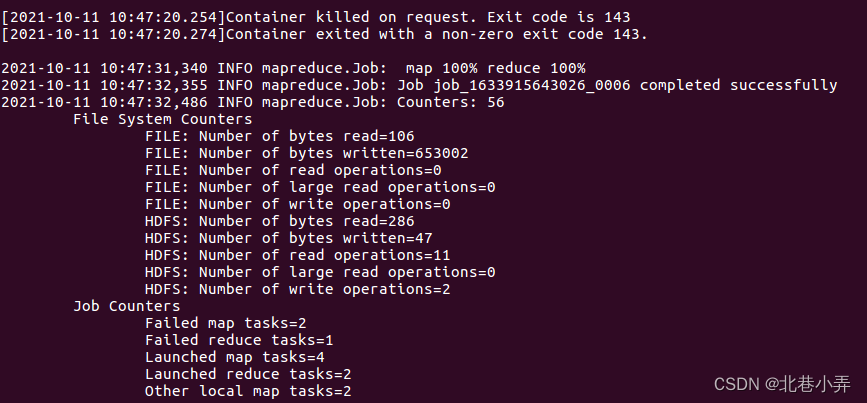
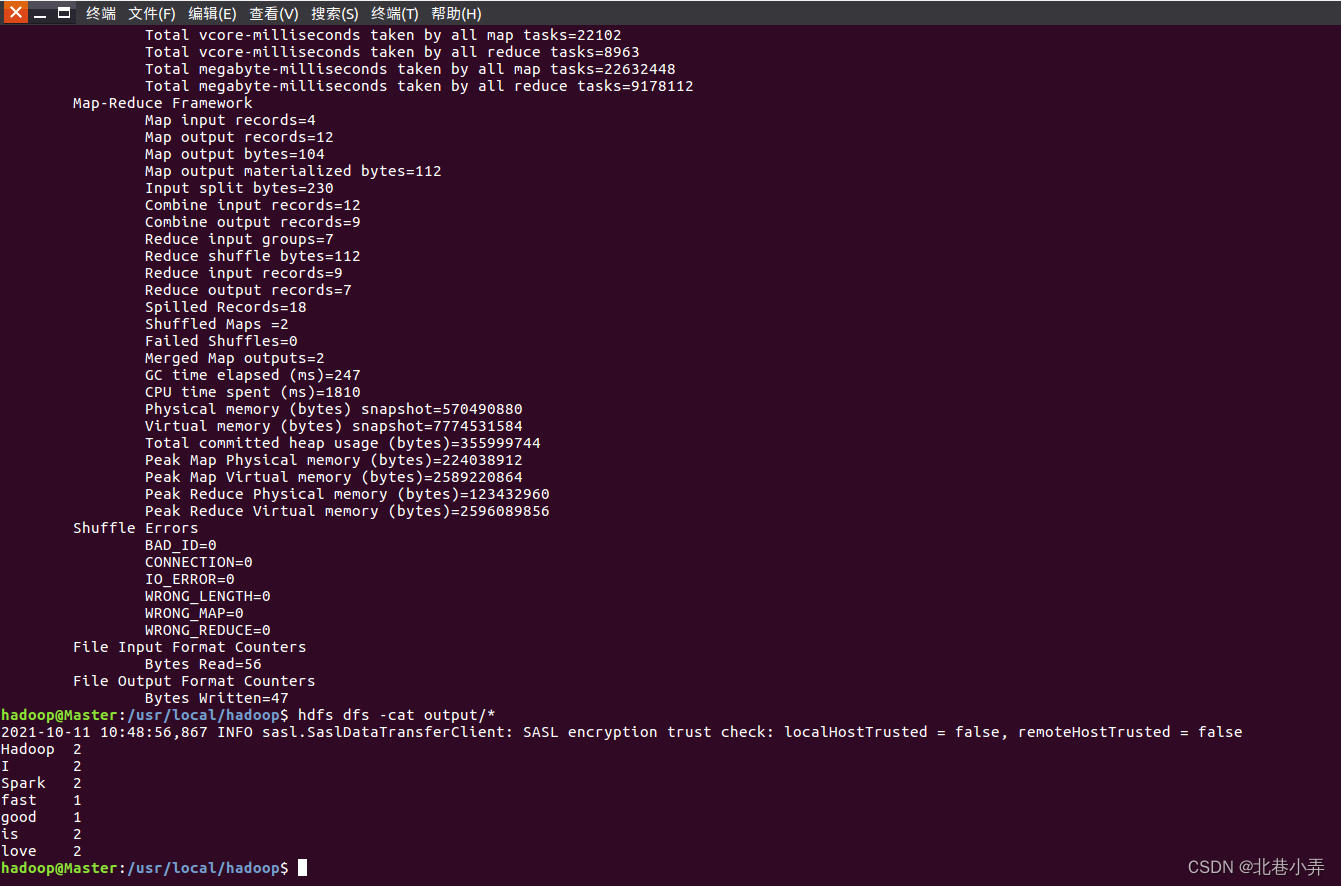
至此,词频统计程序顺利运行结束。需要注意的是,如果要再次运行WordCount.jar,需要首先删除HDFS中的output目录,否则会报错。
5. 完成情况与问题讨论
(1) 实际完成情况
完成全分布词频统计任务
(2) 问题与讨论
问题:如果要再次运行WordCount.jar,需要首先删除HDFS中的output目录,否则会报错。即运行如下代码:
$ hdfs dfs -rm -r /user/hadoop/output
- 1
u>至此,词频统计程序顺利运行结束。需要注意的是,如果要再次运行WordCount.jar,需要首先删除HDFS中的output目录,否则会报错。
5. 完成情况与问题讨论
(1) 实际完成情况
完成全分布词频统计任务
(2) 问题与讨论
问题:如果要再次运行WordCount.jar,需要首先删除HDFS中的output目录,否则会报错。即运行如下代码:
$ hdfs dfs -rm -r /user/hadoop/output
- 1


