
热门标签
热门文章
- 1nltk报错Error loading stopwords: <urlopen error [Errno 11004]_error loading stopwords:
- 2UE5项目打包安卓端-思路解析_ue5 安卓打包
- 32. 编写function call文档解析-SpringAI实战教程_spring ai function call
- 4SpringMVC拦截器的作用及使用方法_webmvcconfigurer addinterceptors拦截器的作用
- 5SpringBoot配置拦截器对静态资源部分接口不实行拦截_addinterceptor 根目录不拦截
- 6AI大模型赋能开发者|海云安创始人谢朝海受邀在ISC.AI 2024大会就“大模型在软件开发&安全领域的应用”主题发表演讲
- 7[ 数据结构进阶 - C++ ] 二叉搜索树_k模型和kv模型
- 8Camtasia2024国产永久免费版电脑录屏软件下载_camtasia2024crack下载
- 9云计算、大数据、人工智能、物联网、虚拟现实技术、区块链技术(新一代信息技术)学习这一篇够了!_畅想未来物联网与大数据_大数据、云计算、人工智能
- 10防火墙综合实验之NAT和智能选路_交换机+智能选路
当前位置: article > 正文
python爬虫入门笔记:用scrapy爬豆瓣
作者:在线问答5 | 2024-08-04 13:45:01
赞
踩
python爬虫入门笔记:用scrapy爬豆瓣
本文希望达到以下目标:
- 简要介绍Scarpy
- 使用Scarpy抓取豆瓣电影
我们正式讲scrapy框架爬虫,并用豆瓣来试试手,url:http://movie.douban.com/top250
首先先要回答一个问题。问:把网站装进爬虫里,总共分几步?
答案很简单,四步:
- 新建项目 (Project):新建一个新的爬虫项目
- 明确目标(Items):明确你想要抓取的目标
- 制作爬虫(Spider):制作爬虫开始爬取网页
- 存储内容(Pipeline):设计管道存储爬取内容
好的,基本流程既然确定了,那接下来就一步一步的完成就可以了。
1.新建项目(Project)
在空目录下按住Shift键右击,选择“在此处打开命令窗口”,输入一下命令:
<span style="font-size:14px;">scrapy startproject douban</span>
可以看到将会创建一个douban文件夹,目录结构如下:
douban/
scrapy.cfg
douban/
__init__.py
items.py
pipelines.py
settings.py
spiders/
__init__.py
...</span>我们用pycharm打开该项目,具体看一下:
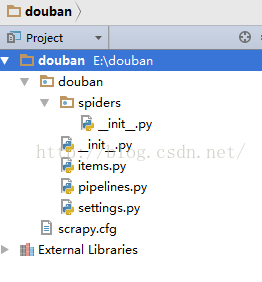
下面来简单介绍一下各个文件的作用:
- scrapy.cfg:项目的配置文件
- douban/:项目的Python模块,将会从这里引用代码
- douban/items.py:项目的items文件
- douban/pipelines.py:项目的pipelines文件
- douban/settings.py:项目的设置文件
- douban/spiders/:存储爬虫的目录
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/在线问答5/article/detail/928067
推荐阅读
相关标签

