
- 1pycorrector 纠错工具安装_from pycorrector import corrector
- 2Spring Boot项目怎么优化接口性能?_springboot项目http接口qps如何优化
- 3Ubuntu20.04系统环境配置_ubuntu20.04配置
- 4Python爬取B站视频
- 5【leetcode C++】最小栈
- 6Android_Studio_布局_LinearLayout(线性布局)_android studio 的linearlayout
- 7STM32学习和实践笔记(4):分析和理解GPIO_InitTypeDef GPIO_InitStructure (c)
- 8doris数据库介绍
- 9Redis实战 - 08 Redis 的 BitMaps 位图命令
- 10Matlab|配电网三相不平衡潮流计算【隐式Zbus高斯法】【可设定变压器数量、位置、绕组方式】
MobileNet网络_relu激活函数会对低维特征信息造成大量损失,对高维造成损失比较小
赞
踩
1. MobileNet v1网络
1.1 MobileNet网络简介
传统卷积神经网络,内存需求大、运算量大导致无法在移动设备以及嵌入式设备上运行

MobileNet网络专注于移动端或者嵌入式设备中的轻量级CNN网络。相比于传统卷积神经网络,在准确率小幅降低的前提下大大减少模型参数与运算量(相比于VGG16准确率减少0.9%,但模型参数只有VGG的1/32)
1.2 网络亮点
- DW卷积Depthwise Convolution (大大减少运算量和参数数量)
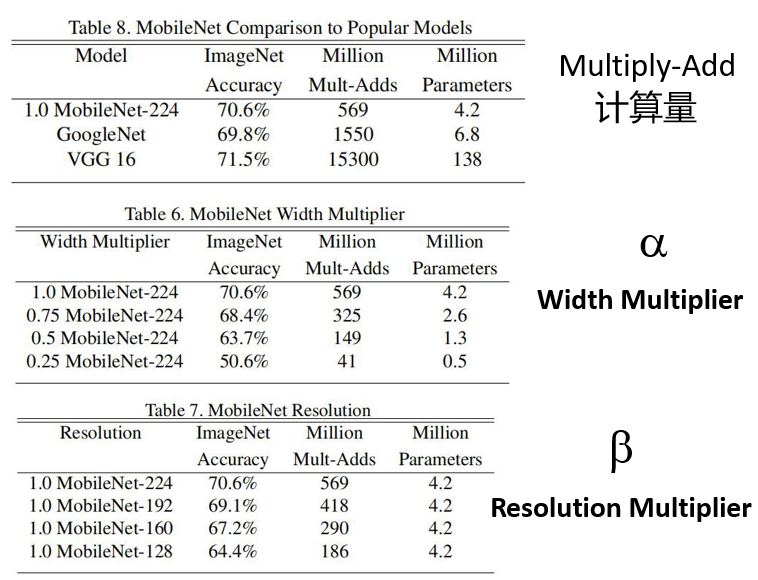
- 增加超参数
α
\alpha
α、
β
\beta
β
α \alpha α控制卷积层卷积核个数
β \beta β控制输入图像大小
α \alpha α和 β \beta β是人为设定的,而不是学习到的
下图为DW卷积

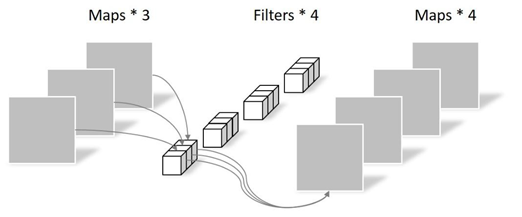
1.3 普通卷积、PW、DW的比较
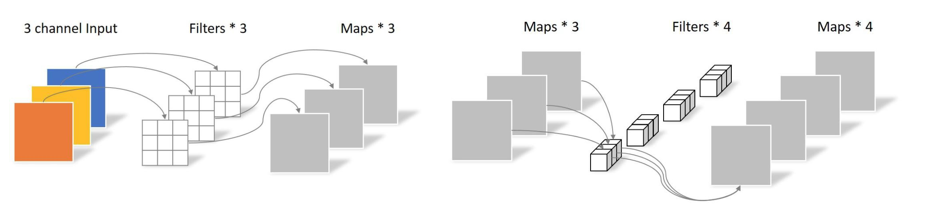
1.3.1 传统卷积
卷积核channel=输入特征矩阵channel
输出特征矩阵channel=卷积核个数

1.3.2 DW卷积
卷积核channel=1
输入特征矩阵channel=卷积核个数=输出特征矩阵channel

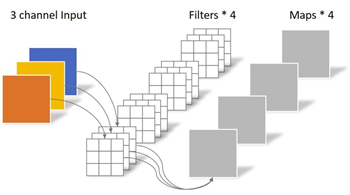
1.3.3 PW卷积(实质是:卷积核大小为1的普通卷积)
卷积核channel=输入特征矩阵channel
卷积核大小为1
1.3.4 计算量的比较
DF:输入特征矩阵的高和宽
DK:卷积核大小
M:输入特征矩阵的深度
N:输出特征矩阵的深度(卷积核的个数)
普通卷积计算量:
D
K
∗
D
K
∗
M
∗
N
∗
D
F
∗
D
F
D_K*D_K*M*N*D_F*D_F
DK∗DK∗M∗N∗DF∗DF
DW+PW卷积计算量:
D
K
∗
D
K
∗
M
∗
D
F
∗
D
F
+
M
∗
N
∗
D
F
∗
D
F
=
1
N
+
1
D
K
2
=
1
N
+
1
9
D_K*D_K*M*D_F*D_F+M*N*D_F*D_F=\frac{1}{N}+\frac{1}{D_K^{2}}=\frac{1}{N}+\frac{1}{9}
DK∗DK∗M∗DF∗DF+M∗N∗DF∗DF=N1+DK21=N1+91
理论上普通卷积计算量是DW+PW的8到9倍
1.4 MobileNet v1网络的模型结构

2. MobileNet v2网络
MobileNet v2网络由Google团队在2018年提出,相比MobileNet v1网络准确率更高,模型更小
2.1 网络亮点
- Inverted Residuals(倒残差结构)
- Linear Bottlenecks
2.2 Relu6激活函数
残差结构:采用ReLu激活函数
倒残差结构:采用Relu6激活函数
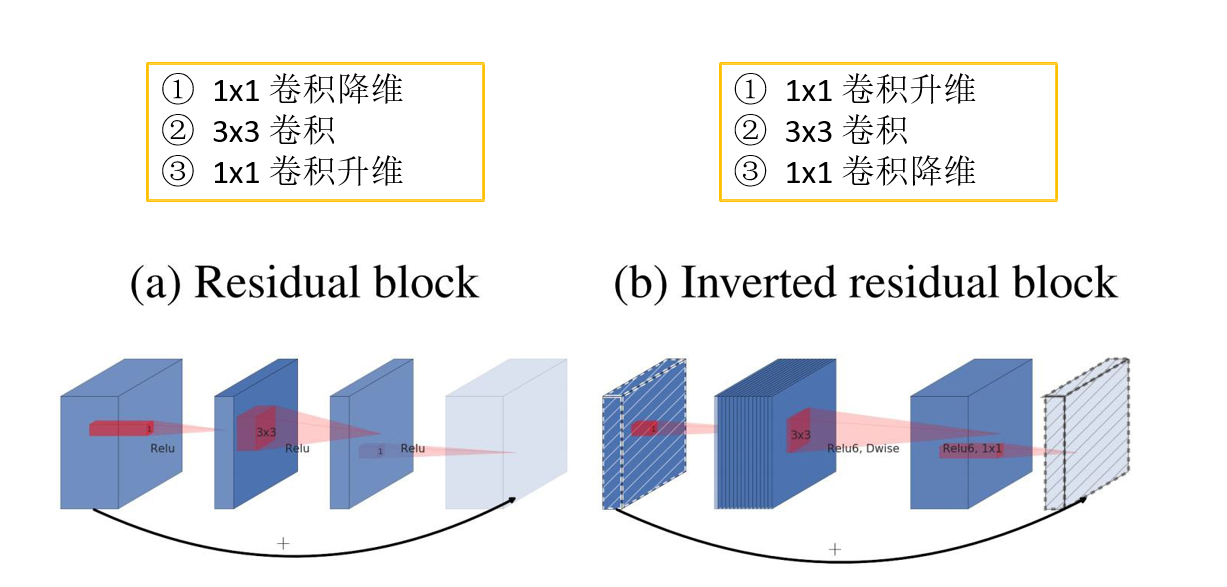
Relu6激活函数:
y = ReLU6(x) = min(max(x, 0), 6)
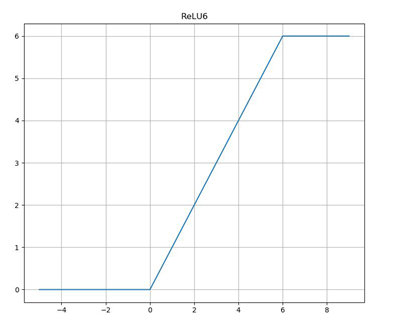
ReLU激活函数对低维特征信息造成大量损失,而对高维特征信息造成的损失较小
原文中针对倒残差结构的最后一个卷积层使用线性激活函数,而不是ReLU激活函数
原文实验:输入是二维矩阵,channel=1。采用不同维度的矩阵matrix T对输入矩阵进行变换,变换到更高的维度上。再使用ReLU激活函数得到输出值。再使用T矩阵的逆矩阵
T
−
1
T^{-1}
T−1将输出矩阵还原成二维的输入矩阵input。当T的矩阵为2或3时,还原成input时丢失了很多信息。
因此得出结论:ReLU激活函数对低维特征信息造成大量损失,而对高维特征信息造成的损失较小。由于倒残差结构是两边大中间小,即两边是低维的,因此针对倒残差结构的最后一个卷积层使用线性激活函数来减少损失,而不是ReLU激活函数
2.3 MobileNe v2倒残差结构图
MobileNe v2中并不是每一个倒残差结构都有shortcut捷径分支
当stride=1且输入特征矩阵与输出特征矩阵shape相同时才有shortcut连接(如下图左1)

t:扩展因子

2.4 MobileNe v2网络结构参数
t:扩展因子
c:输出特征矩阵的深度channel
n:Bottleneck重复的次数
s:步距。每一个block所对应的第一层Bottleneck的步距(一个block由一系列Bottleneck),其它层为1
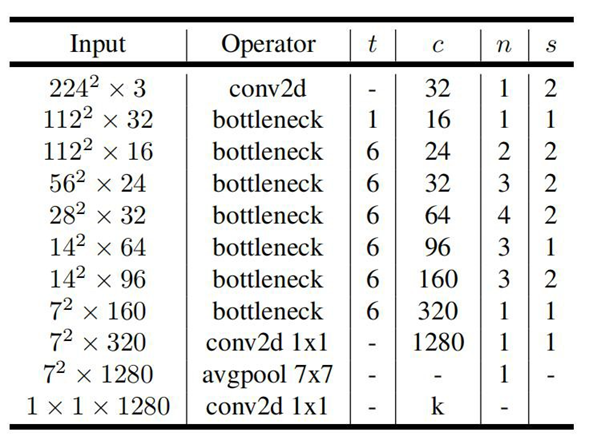
2.5 MobileNe v2网络在分类和目标检测方面的性能对比


