
- 1python+appium+夜神模拟器刷快手极速版金币套现,帮你赚够早餐钱_用模拟器刷快手金币
- 2golang zipkin http_Zipkin 快速上手 —— 五步搞定基础分布式追踪 (概念+代码)【翻译自外文博客】...
- 3Flink之客户端操作_flink和客户端结合
- 4人工智能|机器学习——DBSCAN聚类算法(密度聚类)_神经网络 密度聚类
- 5Python实现32位彩色图像阈值处理——threshold函数案例_python threshold
- 6Java语言程序设计——计算体重指数BMI_定义好变量,输入身高和体重,计算bmi指数
- 7Hadoop学习心得_hadoop实训个人总结与收获
- 8计算机网络课设实验目的,计算机网络课程设计实验报告(北京科技大学arp、ftp、ip包)...
- 9点云:python版本的点云数据处理库_wrappers/python/examples/pygket_pointcloud_viewer.
- 10还有一个星期就要考试了_要测试了
激活函数 sigmoid、tanh、ReLu、Leaky ReLu、ELU、Maxout_excel sigmoid
赞
踩
1. sigmoid
sigmoid 是逻辑函数,常见的 sigmoid 函数定义为:
S
(
x
)
=
1
1
+
e
−
x
S(x)=\frac{1}{1+e^{-x}}
S(x)=1+e−x1
d S ( x ) d x = e − x ( 1 + e − x ) 2 = ( 1 + e − x − 1 1 + e − x ) ( 1 1 + e − x ) = ( 1 − S ( x ) ) S ( x ) \frac{d S(x)}{d x}=\frac{e^{-x}}{\left(1+e^{-x}\right)^{2}}=\left(\frac{1+e^{-x}-1}{1+e^{-x}}\right)\left(\frac{1}{1+e^{-x}}\right)=(1-S(x)) S(x) dxdS(x)=(1+e−x)2e−x=(1+e−x1+e−x−1)(1+e−x1)=(1−S(x))S(x)
广义逻辑函数:
f
(
x
)
=
(
1
+
e
−
x
)
−
α
,
α
>
0
f(x)=\left(1+e^{-x}\right)^{-\alpha}, \quad \alpha>0
f(x)=(1+e−x)−α,α>0
问题:
1、两端的值饱和,梯度为接近0;
2、sigmoid的输出不是以 0 为中心的;梯度总是正或负的,也就是梯度只有一个更新方向。
3、exp()计算量大。
2. 双曲正切函数 tanh
tanh x = sinh x cosh x = e x − e − x e x + e − x \tanh x=\frac{\sinh x}{\cosh x}=\frac{e^{x}-e^{-x}}{e^{x}+e^{-x}} tanhx=coshxsinhx=ex+e−xex−e−x
特点:
1、压缩值在[-1,1];
2、以0为中心;
3、但存在值饱和,梯度为0情况。
3. 修正线性单元ReLu
r
e
l
u
(
x
)
=
m
a
x
(
x
,
0
)
relu(x) = max(x, 0)
relu(x)=max(x,0)
特点:
1、在正区域不存在饱和现象;
2、计算效率高;
3、比sigmoid,tanh收敛更快;
4、生物学中比sigmoid解释性更好;
5、但是结果不是以0为中心的;而且会导致Dead ReLU Problem(神经元坏死现象):
ReLU在负数区域被kill的现象叫做dead relu。ReLU在训练的时很“脆弱”。在x<0时,梯度为0。这个神经元及之后的神经元梯度永远为0,不再对任何数据有所响应,导致相应参数永远不会被更新。
产生这种现象的两个原因:参数初始化问题;learning rate太高导致在训练过程中参数更新太大。
4. Leaky ReLu
L R e l u ( x ) = m a x ( 0.01 x , x ) LRelu(x) = max(0.01x, x) LRelu(x)=max(0.01x,x)
5. PReLu
参数化的修正器Parametric Rectifier(PReLu).
f
(
y
i
)
=
{
y
i
,
if
y
i
>
0
a
i
y
i
,
if
y
i
≤
0
f\left(y_{i}\right)=\left\{yi, if yi>0aiyi, if yi≤0
优化方法:
∂
E
∂
a
i
=
∑
y
i
∂
E
∂
f
(
y
i
)
∂
f
(
y
i
)
∂
a
i
\frac{\partial \mathcal{E}}{\partial a_{i}}=\sum_{y_{i}} \frac{\partial \mathcal{E}}{\partial f\left(y_{i}\right)} \frac{\partial f\left(y_{i}\right)}{\partial a_{i}}
∂ai∂E=yi∑∂f(yi)∂E∂ai∂f(yi)
∂
f
(
y
i
)
∂
a
i
=
{
0
,
if
y
i
>
0
y
i
,
if
y
i
≤
0
\frac{\partial f\left(y_{i}\right)}{\partial a_{i}}=\left\{0, if yi>0yi, if yi≤0
其中,
E
\mathcal E
E代表目标函数。
动量方法更新:
Δ
a
i
:
=
μ
Δ
a
i
+
ϵ
∂
E
∂
a
i
\Delta a_{i}:=\mu \Delta a_{i}+\epsilon \frac{\partial \mathcal{E}}{\partial a_{i}}
Δai:=μΔai+ϵ∂ai∂E
激活函数可以自适应地学习矫正线性单元的参数,并且能够在增加可忽略的额外计算成本下提高准确率。
6. Exponential Linear Units (ELU)
f
(
x
)
=
{
x
if
x
>
0
α
(
exp
(
x
)
−
1
)
if
x
≤
0
f(x)=\left\{x if x>0α(exp(x)−1) if x≤0
特点:
1、和Leaky ReLu相比,在负区有一点的鲁棒性。
7. Maxout
max ( w 1 T x + b 1 , w 2 T x + b 2 ) \max \left(w_{1}^{T} x+b_{1}, w_{2}^{T} x+b_{2}\right) max(w1Tx+b1,w2Tx+b2)
特点:
1、泛化的Relu 和Leaky ReLu;
2、但是引入了更多的参数。
总结:
- 使用 ReLu,注意学习率;
- 尝试 Leaky ReLU/Maxout/ELU;
- 尝试 tanh,但期望不要太高;
- 不要使用 sigmoid。
8. 比较sigmoid,tanh
import matplotlib.pyplot as plt import numpy as np exp = np.exp def sigmoid(x): return exp(x)/(1 + exp(x)) def tanh(x): return (exp(x) - exp(-x))/(exp(x) + exp(-x)) plt.subplot(2,1,1) x = np.linspace(-10, 10, 1000) sigmoid_x = sigmoid(x) plt.plot(x, sigmoid_x) plt.title("sigmoid") plt.grid() plt.subplot(2,1,2) tanh_x = tanh(x) plt.plot(x, tanh_x) plt.title("tanh") plt.grid() plt.show()

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
结果:
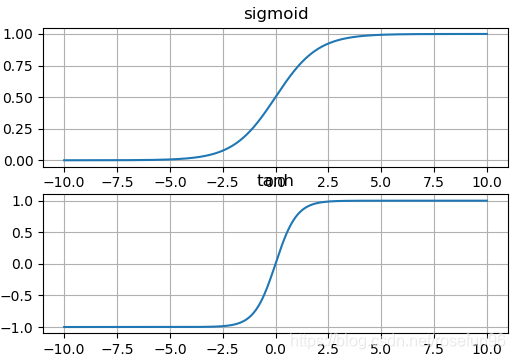
区别:
tanh 具有负值,对于一些不想出现负值的情况,多使用 sigmoid;tanh两端几乎没有梯度,比sigmoid的梯度还小。
参考:

