
- 1分布式爬虫scrapy-redis所踩过的坑_scrapy_redis的坑
- 2Flask项目实战01_flask项目实例
- 3K8s学习(8)---Pod详解(Pod生命周期)_k8s pod invalid
- 4云计算时代操作系统K8s 之pod 生命周期综述_k8s pod的生命周期
- 5Java8 时间字符串校验是否为对应的日期格式_java判断日期字符串格式
- 6【Docker Desktop】Windows11家庭版安装docker desktop和WSl2(Ubuntu22.04)并完成迁移,配置国内镜像_docker win11配置和使用
- 7Android P 屏保和休眠相关知识
- 8啥是Python之禅
- 9网络游戏防沉迷实名认证系统常见错误_sys req partner auth error
- 1032单片机实现呼吸灯_32呼吸灯
java语法糖
赞
踩
概述
几乎所有的语言都涉及到语法糖,语法糖时啥呢?语法糖其实就是在开发中方便程序员用的一些语法,该语法和正常语法的区别就在于:语法糖在底层其时是不能够被一次性直接实现的,它们需要依靠一些技术或普通语法实现。当我们编译.java文件为.class文件的时候,底层编译器解析到语法糖时就会进行解语法糖操作,还原为普通语法。
这些语法虽然不会提供实质性的功能改进,但是能提高我们开发的效率,提供严谨性,但一门语言的语法糖不是越多越好,大量的添加语法糖会让开发者产生依赖,无法知道程序代码的真实行为。
java中常见的语法糖有默认构造器、泛型、自动拆箱自动装箱、 增强for循环、可变长参数……
泛型
在jdk5的时候java推出了泛型的功能,我们来谈谈java泛型的故事和其实现原理。
java和c#的泛型
java和C#在同一年推出了泛型的功能,但是它们两泛型的实现并不相同,java的泛型采用了"类型擦除式泛型",而C#采用的是"具现化式泛型",所谓具现化就是比较具体的,泛型在C#里是真实存在的,在运行环境中泛型充当了一个占位符,其中List<String>和List<int>不是一个类型,因为泛型的存在使得虽然裸类型(泛型前面的类型)相同但是整体却不相同;而类型擦除式泛型是指泛型只在源程序中存在,不会出现在编译后的class文件中,编译时泛型全部会被擦除替换为原来的裸类型,并且在相应的地方加上了强制转换代码,所以List<String>和List<int>其实是一个类型。如下C#可以正常编译,但是java里都是不合法的,因为编译后这些泛型都被擦出了,代码逻辑就不正常了。
- public class GenericsType<T> {
- public void doSomething(Object item){
- if(item instanceof T){
- ……
- }
- T newIntem =new T();
- T[] itemArray=new T[10];
- }
- }
java泛型还有一个缺点就是效率低下,因为它会给程序带来不计其数的拆箱和装箱操作。
总结一下,因为jdk5才出的泛型,所以java开发人员为了保证jdk5之前开发的java代码也能完美兼容,所以实现泛型有很多束缚,有两种实现方式选择,分别是java和C#两条路。而C#是当时才出现2年时间,完全没有太多的顾虑,它采用了开发一套平行于需要加泛型的类型的一套新的类型,以前的老类型可以用,新的类型只不过是在老类型之上添加了一个泛型标志而已。而java不一样,它在jdk1.2就已经这样选择过了,Vector类型用ArrayList代替、HashTable用HashMap代替……,如果因为泛型而分别在这些老新类型上平行的开发一套带有泛型的类型如Vector<T>、ArrayList<T>等,这就可能导致出现一片开发人员的骂声。
类型擦除
如ArrayList<T>的裸类型为ArrayList类型,ArrayList<Integer>和ArrayList<String>都是ArrayList的子类型(不是面向对象的那种子类型),系统会允许子类到父类的完美转换。这些子类型在编译时直接被还原为裸类型了,只有元素访问和修改时自动插入一些强制类型转换和检查命令。
ArrayList可以理解为就是ArrayList<Object>
如下面一段代码,在class文件中其实是另一个模样。
- ArrayList<String> list = new ArrayList<>();
- list.add("123");
- list.add("java");
- System.out.println(list.get(0));
- System.out.println(list.get(1));
反编译后产看结果:
- ArrayList list = new ArrayList();//转为裸类型了
- list.add("123");//实际调用的是list.add(Object e)
- list.add("java");
- System.out.println((String)list.get(0));//添加了强制转换
- System.out.println((String)list.get(1));//实际取得是Object类型强转为String类型
类型擦除方法还有一个缺陷就是对原始类型数据的支持又成了新麻烦,如下一段代码(目前java不支持)
- ArrayList<int> ilist = new ArrayList<int>();
- ArrayList<long> llist = new ArrayList<long>();
- ArrayList list;
- list=ilist;
- list=llist;
如果当类型擦出了,可以想象得出当往下用到强制类型转换时,代码就往下执行不了了,因为不支持int、long类型和Object类型的转换,只有引用类型才能全是Object的子类,才能转换,所以java简单粗暴的禁止掉了原生类型的泛型,这也导致了无数的装箱拆箱。
还有如下代码,该代码是不能被编译通过的,因为类型擦除后压根就是同一个类型,达不到方法重载。
- //'doSomething(ArrayList<String>)' clashes with 'doSomething(ArrayList<Integer>)';both methods have same erasure
- public void doSomething(ArrayList<String> item){
- }
- public void doSomething(ArrayList<Integer> item){
- }
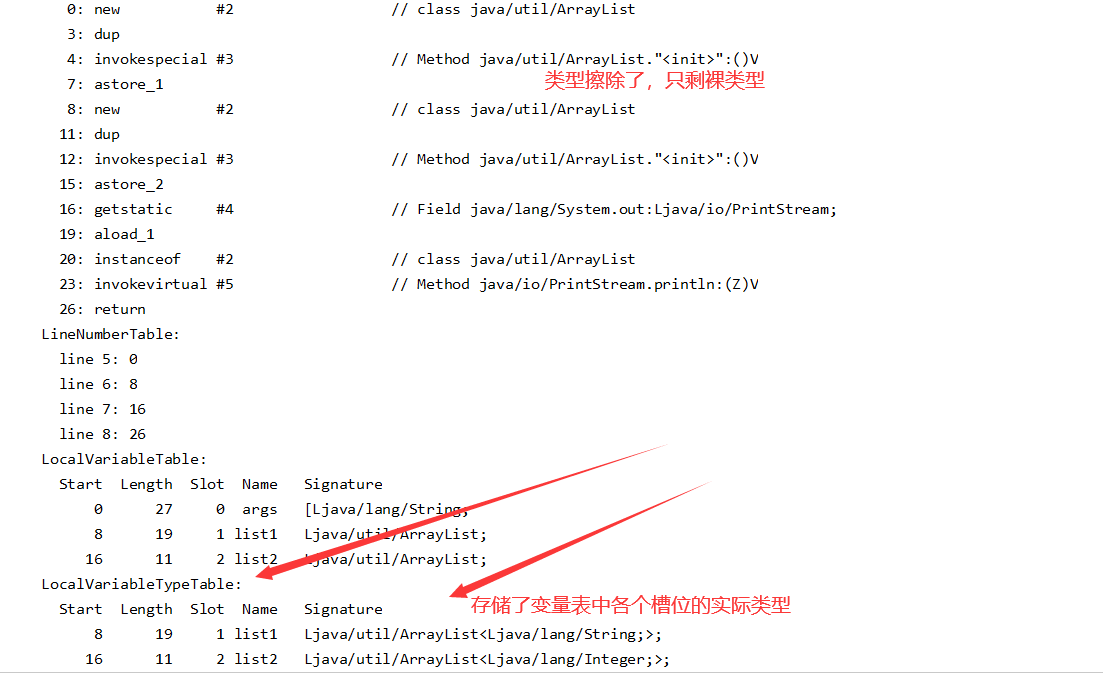
擦除法所谓的擦除仅仅是对方法的Code的属性中的字节码擦除,实际上元数据还是保留了泛型信息的,如Signature属性和LocalVariableType都是为泛型而生的。可以看到LocalVariableType Table仍然保留了方法参数泛型的信息。通过反射依然能获取这些信息
- ArrayList<String> list1 = new ArrayList<>();
- ArrayList<Integer> list2=new ArrayList<>();
上面代码的字节码为
自动装箱、拆箱
jdk5提供的新功能,因为泛型的加入,一些集合的泛型只支持包装类型,所以会发生很多的类型转换,也就出现了减少这种重复操作的自动拆箱和自动装箱语法糖。
- Integer x=1;
- int y=x;
如上一段代码,编译器会在编译阶段给我们的代码解语法糖改为如下代码:
- Integer x=Integer.valueOf(1);
- int y=x.intValue();
其中第一行为装箱操作,第二行为拆箱。
可变参数
可变参数也是JDK 5开始加入的新特性:
- public static void main(String[] args) {
- f("hello","world");
- }
- public static void f(String... args){
- String[]arrays=args;//直接赋值
- System.out.println(arrays);
- }
可变参数String... args实是一个String[] args, 从代码中的赋值语句中就可以看出来。
同样java编译器会在编译期间将上述代码变换为:
- public static void main(String[] args) {
- f(new String[]{"hello","world"});//其实就是一个数组
- }
- public static void f(String... args){
- String[]arrays=args;//直接赋值
- System.out.println(arrays);
- }
如果调用了f() 则等价代码为foo(new String[]{}),创建了一个空的数组,而不会传递null进去
增强for循环
- public static void main(String[] args) {
- int[] array = {1, 2, 3, 4, 5};
- for (int item : array) {
- System.out.println(item);
- }
- }
上面的代码包含了两个语法糖,经过反编译之后,其实就是以下的代码:
- public static void main(String[] args) {
- int[] array = new int[]{1, 2, 3, 4, 5};//第一个语法糖,数组赋初值的简化写法
-
- //开始第二个语法糖
- int[] var2 = array;
-
- for(int var4 = 0; var4 < array.length; ++var4) {
- int item = var2[var4];
- System.out.println(item);
- }
- }
如果我们遍历的不是数组而是list集合,如
- List<String> list= Arrays.asList("1","2","3");
- for (String s : list) {
- System.out.println(s);
- }
其实就是如下代码,其中包含了3个语法糖
- List<String> list = Arrays.asList(new String[]{"1","2","3"});
- Iterator var2 = list.iterator();
-
- while(var2.hasNext()) {
- String s = (String)var2.next();
- System.out.println(s);
- }
集合是采用的迭代器实现的增强for循环,如果集合要使用增强for循环,那可想而知,肯定是要实现Iterable接口的。Iterable接口需要实现一个iterator()方法,返回一个Iterator迭代器,即接口定义了规范。
switch字符串与枚举
从JDK 7开始,switch 可以作用于字符串和枚举类,这个功能其实也是语法糖,例如:
- String str = "hello";
- switch (str) {
- case "hello": {
- System.out.println("hello");
- break;
- }
- case "world": {
- System.out.println("world");
- break;
- }
- }
真实代码为:
- String str = "hello";
- byte var3 = -1;//该值作为标识符
- //首先比较字符串的hash值
- switch(str.hashCode()) {
- case 99162322:
- //里面的if和equals是为了防止hash冲突的
- if (str.equals("hello")) {
- var3 = 0;
- }
- break;
- case 113318802:
- if (str.equals("world")) {
- var3 = 1;
- }
- }
- //再根据获得的标识符来选择要执行的具体代码逻辑
- switch(var3) {
- case 0:
- System.out.println("hello");
- break;
- case 1:
- System.out.println("world");
- }

比较hash值后再equals比较是很严谨的,不会因为hash冲突导致一系列问题。这样做是为了用hash值来提高效率,再让equals来防止hash冲突
用两个switch而不直接输出的原因可能是:直接输出没办法达到用不用break这个操作,有可能用户忘记写break了,但是直接输出不会一直输出下去而是像正常使用的一样,这就有问题。
- public enum Sex {
- MALE,FEMALE
- }
- public static void main(String[] args) {
- Sex sex = Sex.MALE;
- switch (sex) {
- case MALE:
- System.out.println("MALE");
- break;
- case FEMALE:
- System.out.println("FEMALE");
- break;
- }
- }
解语法糖后为:
- //定义一个合成类(仅jvm使用,对我们不可见)
- //用来映射枚举的ordinal 与数组元素的关系
- //枚举的ordinal 表示枚举对象的序号,从0开始
- //即MALE的ordinal()=0, FEMALE的ordinal()=1 .
- static class $MAP{
- //数组大小即为枚举元素个数,里面存储case用来对比的数字
- static int[]map = new int[2];
- static{
- map[Sex.MALE.ordinal()]=1;
- map[Sex.FEMALE.ordinal()]=2;
- }
- }
-
- public static void main(String[] args) {
- Sex sex = Sex.MALE;
- int x=$MAP.map[sex.ordinal()]=1;
- switch(x) {
- case 1:
- System.out.println("MALE");
- break;
- case 2:
- System.out.println("FEMALE");
- }
- }
枚举类
JDK 7新增了枚举类,以前面的性别枚举为例:
- public enum Sex {
- MALE,FEMALE
- }
就是如下:
- public final class Sex extends Enum<Sex>{
- public static final Sex MALE;
- public static final Sex FEMALE;
- public static Sex[] $VALUES;
- static {
- MALE=new Sex("MALE",0);
- FEMALE=new Sex("FEMALE",1);
- $VALUES =new Sex[]{MALE,FEMALE};
- }
- private Sex(String name,int ordinal){
- super(name,ordinal);
- }
- public static Sex[] values(){
- return $VALUES.clone();
- }
-
- public static Sex valueOf(String name){
- return Enum.valueOf(Sex.class,name);
- }
- }
try-with-resource
jdk7新增的对关闭资源处理的特殊语法。
- try(FileInputStream stream = new FileInputStream(new File("1.txt"))){
- System.out.println(stream);
- } catch (Exception e) {
- e.printStackTrace();
- }
try中的资源对象需要实现AutoCloseable接口,只要放在try的括号中不需要我们自己去关闭资源,简化开发。
其语法解糖后如下:
- try {
- FileInputStream stream = new FileInputStream(new File("1.txt"));
- Throwable var2 = null;//临时变量
-
- try {
- //我们的代码逻辑
- System.out.println(stream);
- } catch (Throwable var12) {
- var2 = var12;
- throw var12;
- } finally {
- if (stream != null) {
- //判断我们的代码中是否有异常
- if (var2 != null) {
- try {
- stream.close();//关闭流
- } catch (Throwable var11) {
- //防止异常丢失
- var2.addSuppressed(var11);
- }
- } else {
- stream.close();
- }
- }
-
- }
- } catch (Exception var14) {
- var14.printStackTrace();
- }
给我们生成了两个try语句块。
方法重写时的桥接方法
我们都知道,方法重写时对返回值分两种情况:
- 父子类的返回值完全一致
- 子类返回值可以是父类返回值的子类(见下面的例子)
- public class A {
- public Number m(){
- return 1;
- }
- }
- class B extends A{
- @Override//返回值类型必须是父类该方法的子类型
- public Integer m() {
- return 2;
- }
- }
该重写时成立的,Override并没有报错。
解糖后类B如下:
- class B extends A{
- public Integer m() {
- return 2;
- }
- public synthetic bridge Number m(){
- return m();
- }
- }
它会给我们加上实际的方法重写,且间接调用我们原来的方法,这里的两个不认识的关键字我们是看不到的,只在jvm内部存在,这种方法就是桥接方法。
其中桥接方法比较特殊,仅对java虚拟机可见,并且与原来的public Integer m()没有命名冲突,可以用下面反射代码来验证:
- for (Method method : B.class.getDeclaredMethods()) {
- System.out.println(method);
- }
结果为:
- public java.lang.Integer vm.B.m()
- public java.lang.Number vm.B.m()
匿名内部类
- public class Candy {
- public static void main(String[] args) {
- Runnable run=new Runnable() {
- @Override
- public void run() {
- System.out.println("OK");
- }
- };
- }
- }
该代码编译为class文件时会自动生成一个类,名字中有$的一般都是jvm给我们自动生成的类

- class Candy$1 implements Runnable{
- @Override
- public void run() {
- System.out.println("OK");
- }
- }
再有,如果该匿名内部类中引用了外部的变量,该变量必须为final类型的
- public class Candy {
- public static void main(String[] args) {
- int x = 0;//该变量被匿名内部类所引用,jvm会给他自动加上final
- //x=1; //不能给他赋值,如果赋值了就报错,Variable 'x' is accessed from within inner class, needs to be final or effectively final
- Runnable run=new Runnable() {
- @Override
- public void run() {
- System.out.println(x);
- }
- };
- }
- }
生成的类为:
- class Candy$1 implements Runnable{
- int val$x;//新增的变量
- public Candy$1(int val$x) {//构造方法里赋值
- this.val$x = val$x;
- }
-
- @Override
- public void run() {
- System.out.println(this.val$x);
- }
- }
这同时解释了为什么匿名内部类引用局部变量时,局部变量必须是final的:因为在创建candy$1对象时,将x的值赋值给了Candy$1对象的valx属性,所以x不应该再发生变化了,如果变化那么valx属性
没有机会再跟着一起变化。


