
热门标签
热门文章
- 1NotImplementedError: Cannot convert a symbolic Tensor (lstm/strided_slice:0) to a numpy array.
- 2奥森图标的基本使用方法
- 3多任务:分层特征融合网络 NDDR-CNN_多任务cnn
- 42021年9月 python一级程序题 【龟兔赛跑/画菱形】_用python画一个正方形,里面画一个菱形,并用红色涂满
- 5::在c++中的意思_c++中::是什么意思
- 6Cmake出现CMake Error: Could not find CMAKE_ROOT !!!
- 7新买计算机硬盘不小于,买了一个硬盘要怎么添加到电脑上而不破坏原来的数据文?...
- 8软件测试期末测试题及解析(五套试题共两万余字)_软件质量保证与测试期末考试题
- 9产品经理常见面试题目——思维/场景问题_未来五年我认为会成为一个重要的方向,无论是从政策层面还是从融资方面,都显示web3
- 10【AI_Design】Midjourney技巧进阶
当前位置: article > 正文
【lesson9】高并发内存池Page Cache层释放内存的实现
作者:思考机器4 | 2024-02-04 12:57:07
赞
踩
【lesson9】高并发内存池Page Cache层释放内存的实现
Page Cache层释放内存的流程
如果central cache释放回一个span,则依次寻找span的前后page id的没有在使用的空闲span,看是否可以合并,如果合并继续向前寻找。这样就可以将切小的内存合并收缩成大的span,减少内存碎片。
Page Cache层释放内存的实现
void PageCache::ReleaseSpanToPageCache(Span* span) { // 对span前后的页,尝试进行合并,缓解内存碎片问题 //补充点1:向前合并的逻辑介绍 while (1) { PAGE_ID prevId = span->_pageId - 1; auto ret = _idSpanMap.find(prevId); // 前面的页号没有,不合并了 if (ret == _idSpanMap.end()) { break; } // 前面相邻页的span在使用,不合并了 Span* prevSpan = ret->second; if (prevSpan->_isUse == true) { break; } // 合并出超过128页的span没办法管理,不合并了 if (prevSpan->_n + span->_n > NPAGES-1) { break; } span->_pageId = prevSpan->_pageId; span->_n += prevSpan->_n; _spanLists[prevSpan->_n].Erase(prevSpan); delete prevSpan; } // 向后合并 //补充点2:向后合并的逻辑介绍 while (1) { PAGE_ID nextId = span->_pageId + span->_n; auto ret = _idSpanMap.find(nextId); if (ret == _idSpanMap.end()) { break; } Span* nextSpan = ret->second; if (nextSpan->_isUse == true) { break; } if (nextSpan->_n + span->_n > NPAGES-1) { break; } span->_n += nextSpan->_n; _spanLists[nextSpan->_n].Erase(nextSpan); delete nextSpan; } _spanLists[span->_n].PushFront(span); span->_isUse = false; _idSpanMap[span->_pageId] = span; _idSpanMap[span->_pageId+span->_n-1] = span; }

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
补充点1:向前合并的逻辑介绍
向前合并代码
while (1) { PAGE_ID prevId = span->_pageId - 1; auto ret = _idSpanMap.find(prevId); // 前面的页号没有,不合并了 if (ret == _idSpanMap.end()) { break; } // 前面相邻页的span在使用,不合并了 Span* prevSpan = ret->second; if (prevSpan->_isUse == true) { break; } // 合并出超过128页的span没办法管理,不合并了 if (prevSpan->_n + span->_n > NPAGES-1) { break; } span->_pageId = prevSpan->_pageId; span->_n += prevSpan->_n; _spanLists[prevSpan->_n].Erase(prevSpan); delete prevSpan; }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
我们假设Central Cache还回来了一个3页的span
_pageid = 2000
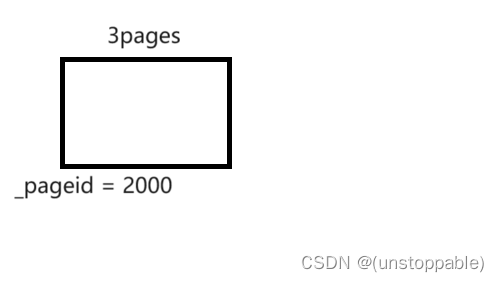
而我们向前合并就是要找前面_pageid为1999的span
假设1999有且没被使用

合并两个span
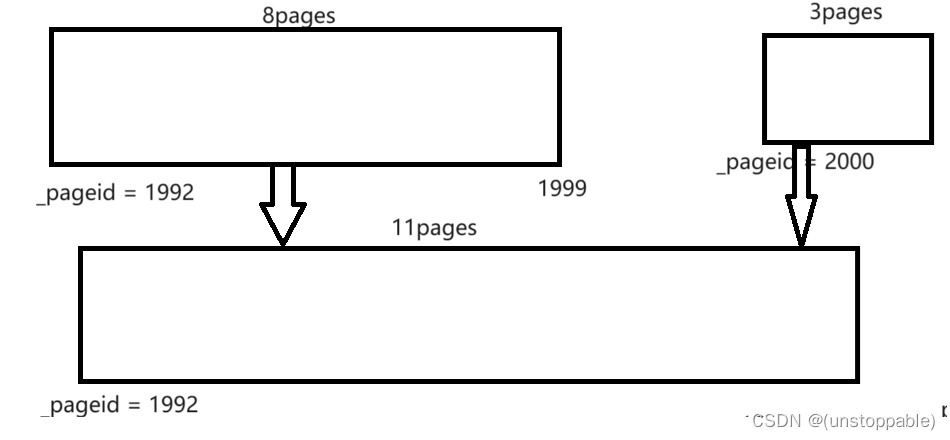
然后继续往前合,直到不能合了为止
不能合情况:
1.前面对应的页号不存在
2.前面的页号正在使用
3.和前面的span加起来页数超过128
补充点2:向后合并的逻辑介绍
向后合并代码:
while (1) { PAGE_ID nextId = span->_pageId + span->_n; auto ret = _idSpanMap.find(nextId); if (ret == _idSpanMap.end()) { break; } Span* nextSpan = ret->second; if (nextSpan->_isUse == true) { break; } if (nextSpan->_n + span->_n > NPAGES-1) { break; } span->_n += nextSpan->_n; _spanLists[nextSpan->_n].Erase(nextSpan); delete nextSpan; }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
前面已经向前合并了,那么之后,我们就要看看向后还能不能合并

我们向后合并也是
现在的span的_pageid + 页数,在该场景中也就是1992+11 = 2003,所以我们应该向后找2003页的span看有没有。
假设有

合并两span
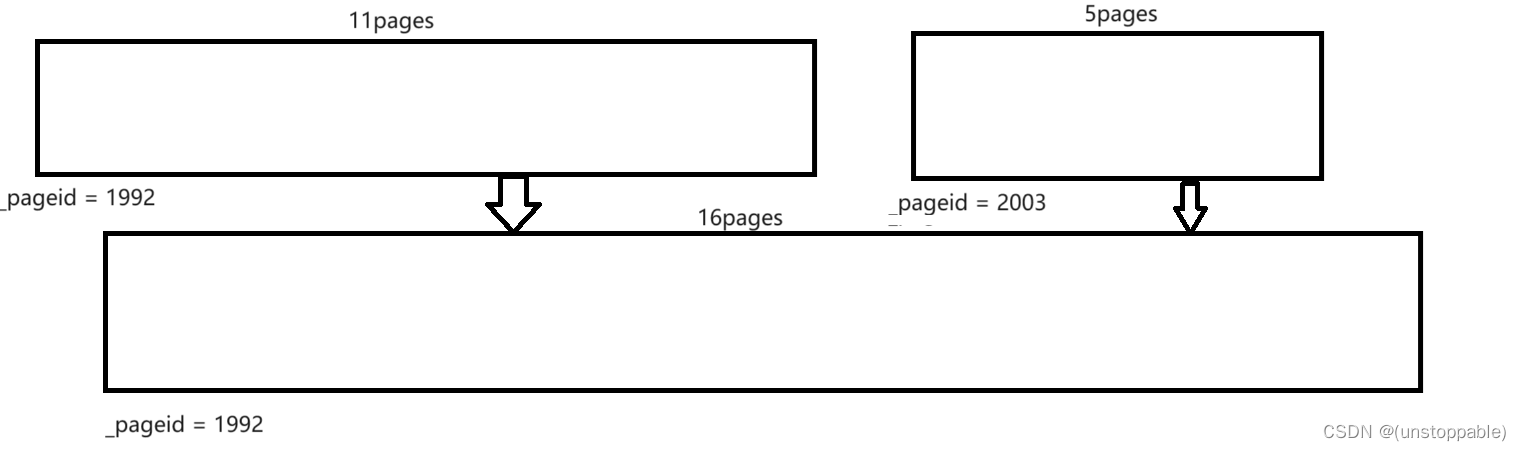
然后也继续往后合,直到不能合了为止
不能合情况:
1.后面对应的页号不存在
2.后面的页号正在使用
3.和后面的span加起来页数超过128
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/article/detail/58660
推荐阅读
相关标签

