
- 1ros2配合yolov8具体实现
- 2HarmonyOS鸿蒙学习笔记(9)Navigator组件实现页面路由跳转_鸿蒙购物车点击跳转
- 3有效的github下载提速方法_github 下载加速
- 4python入门教程(非常详细)
- 5PHP-MYSQL学生信息管理系统(附源码免费)_php学生管理系统源码免费
- 62024年网络安全人才市场的十大趋势_数读网安人才
- 7利用遗传算法求解TSP问题_用遗传算法解决tsp问题 编码、初始群体的产生、适应度计算、选择运算、交叉运算、
- 8【kubernetes系列】Kubernetes之Taints和tolerations_kubernetes tolerations
- 9python提取图片型pdf中的文字(提取pdf扫描件文字)_pyhon pdf中图片的文字
- 10git用法总结
基于飞桨复现ScaledYOLOv4_train2017.cache
赞
踩
ScaledYOLOv4-Paddle
ScaledYOLOv4(论文点此)主要在YOLOv4上针对不同计算设备优化其推理速度而提出的一些缩放模型。与先前的EfficientDet不同(参见目标检测:基于Paddle框架的EfficientDet论文复现),EfficientDet 无非是首先选择网络基础模块,它往往又好又快,然后针对影响目标检测的重要参数如:网络宽度w、深度d、输入图像分辨率size等进行(满足一定条件下按照一定规律)调参。
ScaledYOLOv4针对不同的GPU设计不同模型。思路依然是寻找基础模块,然后调整网络宽度w、深度d、输入图像分辨率
- 对于传统的大多数GPU环境,作者选取
CSPDarknet53优化后的模型作为backbone。
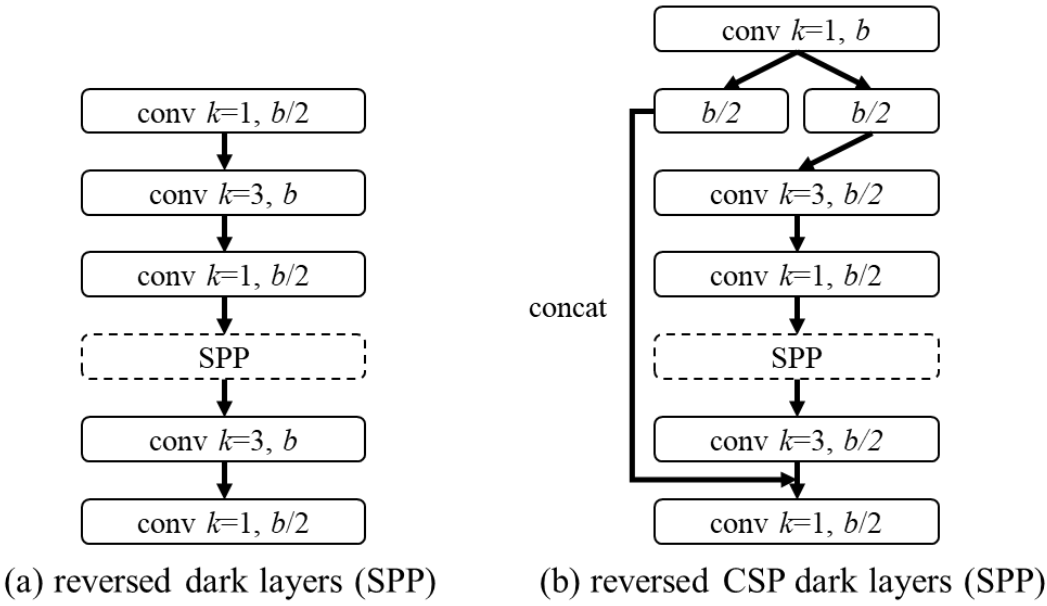
- 针对嵌入式平台的GPU算力,作者设计了YOLOv4-tiny
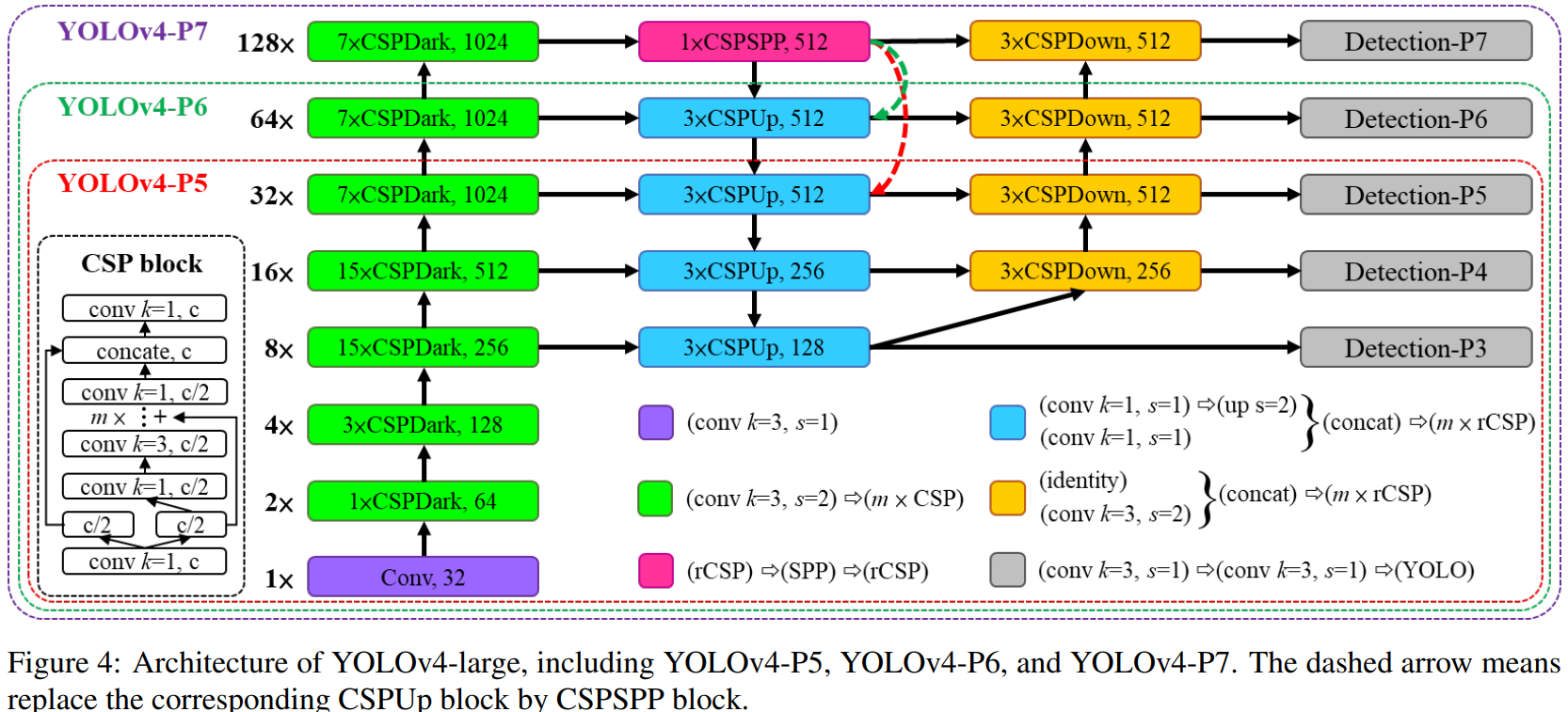
- 对于高端GPU,例如AIStudio提供的Tesla V100,作者设计了YOLOv4-Large,通过提高输入图像分辨率和增加stage的方式提高模型精度
数据文件准备
数据集已挂载至aistudio项目中,如果需要本地训练可以从这里下载数据集,和标签文件
数据集目录大致如下,可根据实际情况修改
Data |-- coco | |-- annotions | |-- images | |-- train2017 | |-- val2017 | |-- test2017 | |-- labels | |-- train2017 | |-- val2017 | |-- train2017.cache(初始解压可删除,训练时会自动生成) | |-- val2017.cache(初始解压可删除,训练时会自动生成) | |-- test-dev2017.txt | |-- val2017.txt | |-- train2017.txt ` `-- validation

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
训练
单卡训练
python train.py --batch-size 8 --img 896 896 --data coco.yaml --cfg yolov4-p5.yaml --weights '' --sync-bn --device 0 --name yolov4-p5
- 1

多卡训练
python train_multi_gpu.py --batch-size 12 --img 896 896 --data coco.yaml --cfg yolov4-p5.yaml --weights '' --sync-bn --name yolov4-p5 --notest
- 1
多卡训练项目已提交至脚本任务ScaledYOLOv4
多卡训练日志以及模型可在此处下载,提取码:mxz8
验证
确保已安装pycocotools
pip install pycocotools
- 1
python test.py --img 896 --conf 0.001 --batch 8 --data coco.yaml --weights scaledyolov4.pdparams
- 1
需要注意到,在test.py的58行指定模型配置文件路径model = Model('/home/aistudio/ScaledYOLOv4-yolov4-large/models/yolov4-p5.yaml', ch=3, nc=80)以及227行的标签路径cocoGt = COCO(glob.glob('/home/aistudio/Data/coco/annotations/instances_val2017.json')[0]),运行后会出现test_batch0_gt.jpg和test_batch0_pred.jpg
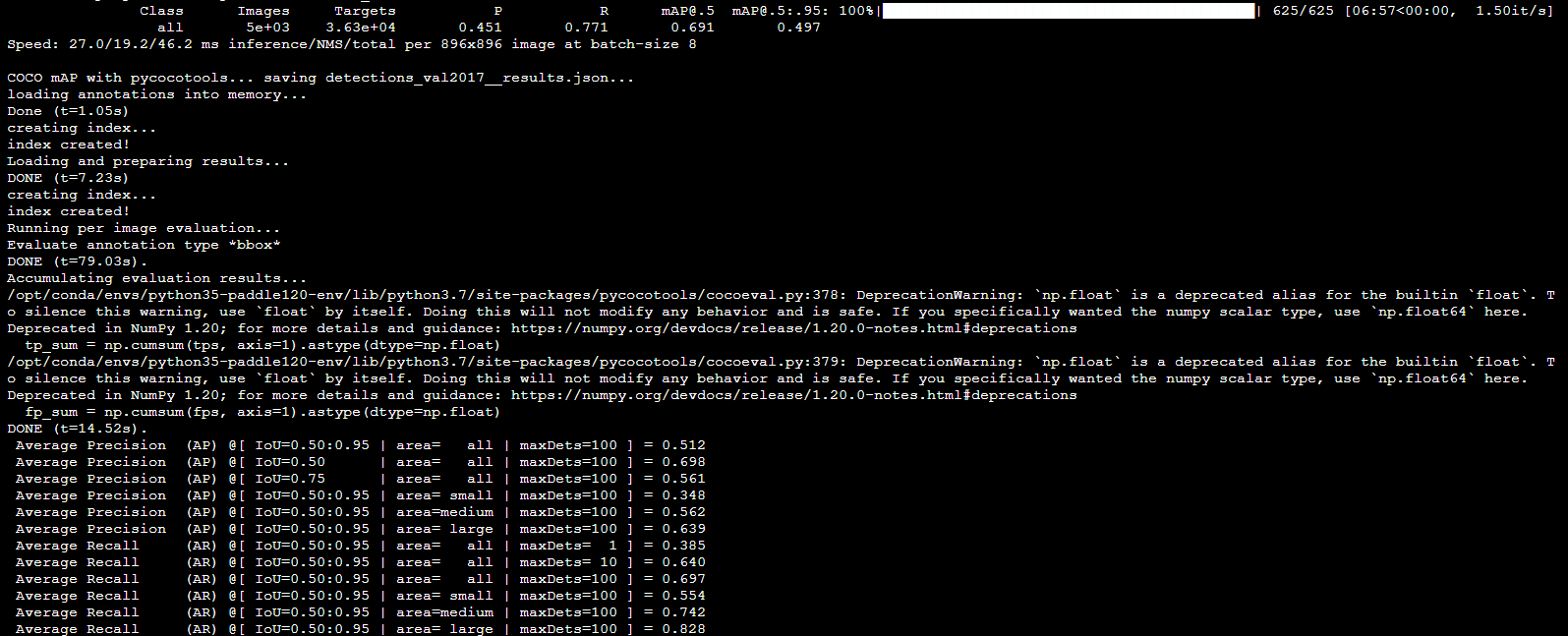
验证结果如下所示

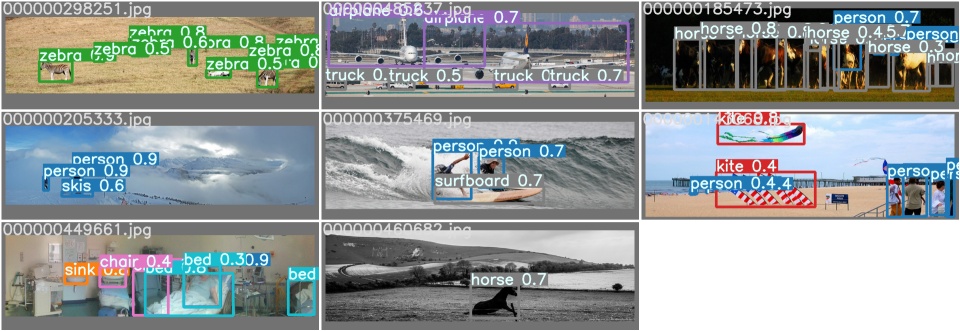
验证完成后会生成detections_val2017__results.json并打印验证信息
推理
python detect.py
- 1
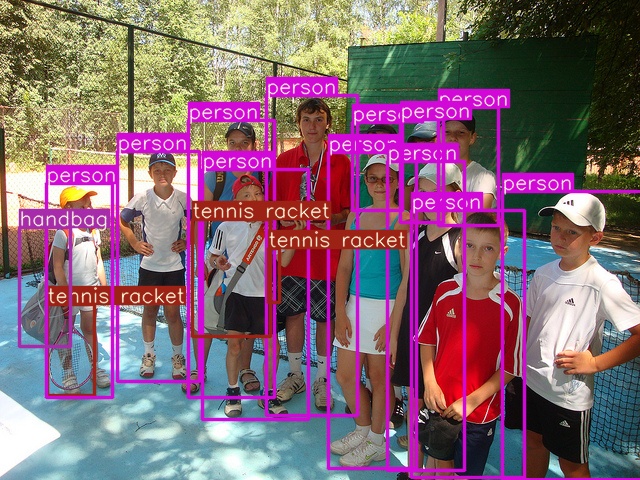
与验证相同,你需要指定detec.py中33行模型配置文件路径,在inference下放置了一些测试图像,运行结果将会保存在inference/output文件夹下




GitHub地址
训练Custom数据集
这里我以一个简单的YOLO格式光栅数据集为例,数据集已上传至AIStudio
其组织结构如下:
Data
|-- guangshan
| |-- images
| |-- train
| |-- val
| |-- labels
| |-- train
| |-- val
| |-- val.txt
| |-- train.txt
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
另外你需要构建ScaledYOLOv4-Paddle/models/guangshan-yolov4-p5.yaml和ScaledYOLOv4-Paddle/models/guangshan-yolov4-p5.yaml,相关文件已放入相关目录,主要用于指定数据集读取路径和模型配置。
训练
python train.py --batch-size 8 --img 512 512 --data guangshan.yaml --cfg guangshan-yolov4-p5.yaml --weights '' --sync-bn --device 0 --name yolov4-p5 --notest
- 1
测试
python test.py --img 512 --conf 0.001 --batch 8 --data guangshan.yaml --weights guangshan.pdparams
- 1
注意到你需要修改test.py中配置文件的路径,并注释model.fuse()
Class Images Targets P R mAP@.5 mAP@.5:.95: 100%|██████████████████████████████████████████████| 2/2 [00:05<00:00, 2.69s/it]
all 16 29 0.104 1 0.995 0.714
- 1
- 2
推理
创建推理的文件目录如下
guangshan
|-- images
|-- output
- 1
- 2
- 3
python detect.py
- 1
注意到你需要修改test.py中配置文件的路径,并注释model.fuse()
推理结果保存在ScaledYOLOv4-Paddle/guangshan/output,推理展示如下:
标签

推理

TODO
- 代码优化
- 打印信息优化
关于作者

| 姓名 | 郭权浩 |
|---|---|
| 学校 | 电子科技大学研2020级 |
| 研究方向 | 计算机视觉 |
| 主页 | Deep Hao的主页 |
如有错误,请及时留言纠正,非常蟹蟹!
后续会有更多论文复现系列推出,欢迎大家有问题留言交流学习,共同进步成长!

