
热门标签
热门文章
- 1Eclipse 连接SQL_eclipse中.sql
- 2Openstack报错:Connection to the hypervisor is broken on host: compute 的解决办法_hypervisorunavailable: connection to the hyperviso
- 3安卓逆向——Frida安装和使用_frida12.11.6
- 4【Python】函数Д_python def函数
- 5springboot整合Java High Level REST Client调动elasticsearch进行增删改查_spring elasticsearch rest high level增删改查
- 6Codeforces 919 (div2) a-c题题解
- 7利用Docker Compose快速部署FastGPT知识库问答_fastgpt本地部署
- 8C语言 printf() 详解 非常详细_c printf
- 9Java学习 - 使用类与对象创建一个自己的登录界面_java swing登录注册界面包和类设计
- 10解决Ubuntu 20.04打开Terminal闪退问题
当前位置: article > 正文
python实现线性可分支持向量机模型_随机生成两个样本点,每一类不少于100的数据集
作者:人工智能逻辑思维 | 2024-02-01 10:53:18
赞
踩
随机生成两个样本点,每一类不少于100的数据集
内容:
随机生成两类且维数为2的100个样本的数据集(注:每类均为100个样本) ,使用2/3数据训练支持向量机,剩余1/3数据进行测试,计算正确率。
代码:
实在不想写了就来这看看吧~~~
- import math # 数学
- import random # 随机
- import numpy as np
- import matplotlib.pyplot as plt
-
-
- def zhichi_w(zhichi, xy, a): # 计算更新 w
- w = [0, 0]
- if len(zhichi) == 0: # 初始化的0
- return w
- for i in zhichi:
- w[0] += a[i] * xy[0][i] * xy[2][i] # 更新w
- w[1] += a[i] * xy[1][i] * xy[2][i]
- return w
-
-
- def zhichi_b(zhichi, xy, a): # 计算更新 b
- b = 0
- if len(zhichi) == 0: # 初始化的0
- return 0
- for s in zhichi: # 对任意的支持向量有 ysf(xs)=1 所有支持向量求解平均值
- sum = 0
- for i in zhichi:
- sum += a[i] * xy[2][i] * (xy[0][i] * xy[0][s] + xy[1][i] * xy[1][s])
- b += 1 / xy[2][s] - sum
- return b / len(zhichi)
-
-
- def SMO(xy):
- # 初始化=========================================
- fx = [] # 储存所有的fx
- yfx = [] # 储存所有yfx-1的值
- Ek = [] # Ek,记录fx-y用于启发式搜索
- E_ = -1 # 贮存最大偏差,减少计算
- a1 = 0 # SMO a1
- a2 = 0 # SMO a2
- # 初始化结束======================================
- a = [0.0] * len(xy[0]) # 拉格朗日乘子
- zhichi = set() # 支持向量下标
- loop = 1 # 循环标记(符合KKT)
- w = [0, 0] # 初始化 w
- b = 0 # 初始化 b
- while loop:
- loop += 1
- if loop == 50:
- print("达到早停标准")
- print("循环了:", loop, "次")
- loop=0
- break
- # 初始化=========================================
- fx = [] # 储存所有的fx
- yfx = [] # 储存所有yfx-1的值
- Ek = [] # Ek,记录fx-y用于启发式搜索
- E_ = -1 # 贮存最大偏差,减少计算
- a1 = 0 # SMO a1
- a2 = 0 # SMO a2
- # 初始化结束======================================
- # 寻找a1,a2======================================
- for i in range(len(xy[0])): # 计算所有的 fx yfx-1 Ek
- fx.append(w[0] * xy[0][i] + w[1] * xy[1][i] + b) # 计算 fx=wx+b
- yfx.append(xy[2][i] * fx[i] - 1) # 计算 yfx-1
- Ek.append(fx[i] - xy[2][i]) # 计算 fx-y
- if i in zhichi: # 之前看过的不看了,防止重复找某个a
- continue
- if yfx[i] <= yfx[a1]:
- a1 = i # 得到偏离最大位置的下标(数值最小的)
- if yfx[a1] >= 0: # 最小的也满足KKT
- print("循环了:", loop, "次")
- loop = 0 # 循环标记(符合KKT)置零(没有用到)
- break
- for i in range(len(xy[0])): # 遍历找间隔最大的a2
- if i == a1: # 如果是a1,跳过
- continue
- Ei = abs(Ek[i] - Ek[a1]) # |Eki-Eka1|
- if Ei < E_: # 找偏差
- E_ = Ei # 储存偏差的值
- a2 = i # 储存偏差的下标
- # 寻找a1,a2结束===================================
- zhichi.add(a1) # a1录入支持向量
- zhichi.add(a2) # a2录入支持向量
- # 分析约束条件=====================================
- # c=a1*y1+a2*y2
- c = a[a1] * xy[2][a1] + a[a2] * xy[2][a2] # 求出c
- # n=K11+k22-2*k12
- n = xy[0][a1] ** 2 + xy[1][a1] ** 2 + xy[0][a2] ** 2 + xy[1][a2] ** 2 - 2 * (
- xy[0][a1] * xy[0][a2] + xy[1][a1] * xy[1][a2])
- # 确定a1的可行域=====================================
- if xy[2][a1] == xy[2][a2]:
- L = max(0.0, a[a1] + a[a2] - 0.5) # 下界
- H = min(0.5, a[a1] + a[a2]) # 上界
- else:
- L = max(0.0, a[a1] - a[a2]) # 下界
- H = min(0.5, 0.5 + a[a1] - a[a2]) # 上界
- if n > 0:
- a1_New = a[a1] - xy[2][a1] * (Ek[a1] - Ek[a2]) / n # a1_New = a1_old-y1(e1-e2)/n
- # print("x1=",xy[0][a1],"y1=",xy[1][a1],"z1=",xy[2][a1],"x2=",xy[0][a2],"y2=",xy[1][a2],"z2=",xy[2][a2],"a1_New=",a1_New)
- # 越界裁剪============================================================
- if a1_New >= H:
- a1_New = H
- elif a1_New <= L:
- a1_New = L
- else:
- a1_New = min(H, L)
- # 参数更新=======================================
- a[a2] = a[a2] + xy[2][a1] * xy[2][a2] * (a[a1] - a1_New) # a2更新
- a[a1] = a1_New # a1更新
- w = zhichi_w(zhichi, xy, a) # 更新w
- b = zhichi_b(zhichi, xy, a) # 更新b
- # print("W=", w, "b=", b, "zhichi=", zhichi, "a1=", a[a1], "a2=", a[a2])
- # 标记支持向量======================================
- for i in zhichi:
- if a[i] == 0: # 选了,但值仍为0
- loop = loop + 1
- e = 'silver'
- else:
- if xy[2][i] == 1:
- e = 'b'
- else:
- e = 'r'
- plt.scatter(x1[0][i], x1[1][i], c='none', s=100, linewidths=1, edgecolor=e)
- print("支持向量数为:", len(zhichi), "\na为零支持向量:", loop)
- print("有用向量数:", len(zhichi) - loop)
- # 返回数据 w b =======================================
- return [w, b]
-
-
- def panduan(xyz, w_b):
- c = 0
- for i in range(len(xyz[0])):
- if (xyz[0][i] * w_b[0][0] + xyz[1][i] * w_b[0][1] + w_b[1]) * xyz[2][i] < 0:
- c = c + 1
- return (1 - c / len(xyz[0])) * 100
-
-
- # 生成数据集=============================================
- x = [] # 数据集x属性
- y = [] # 数据集y属性
- x.extend(np.random.normal(loc=40.0, scale=10, size=100)) # 向x中放100个均值为30,方差为10,正态分布的随机数
- x.extend(np.random.normal(loc=80.0, scale=10, size=100)) # 向x中放100个均值为80,方差为10,正态分布的随机数
- y.extend(np.random.normal(loc=80.0, scale=10, size=100)) # 向y中放100个均值为80,方差为10,正态分布的随机数
- y.extend(np.random.normal(loc=40.0, scale=10, size=100)) # 向y中放100个均值为30,方差为10,正态分布的随机数
- c = [1] * 100 # c标签第一类为 1 x均值:30 y均值:80
- c.extend([-1] * 100) # # c标签第二类为 -1 x均值:80 y均值:30
- # 生成训练集与测试集=======================================
- lt = list(range(200)) # 得到一个顺序序列
- random.shuffle(lt) # 打乱序列
- x1 = [[], [], []] # 初始化x1
- x2 = [[], [], []] # 初始化x2
- for i in lt[0:150]: # 截取部分做训练集
- x1[0].append(x[i]) # 加上数据集x属性
- x1[1].append(y[i]) # 加上数据集y属性
- x1[2].append(c[i]) # 加上数据集c标签
- for i in lt[150:200]: # 截取部分做测试集
- x2[0].append(x[i]) # 加上数据集x属性
- x2[1].append(y[i]) # 加上数据集y属性
- x2[2].append(c[i]) # 加上数据集c标签
- # 计算 w b============================================
- plt.figure(1) # 第一张画布
- wb = SMO(x1)
- print("w为:", wb[0], " b为:", wb[1])
- # 计算正确率===========================================
- print("训练集上的正确率为:", panduan(x1, wb), "%")
- print("测试集上的正确率为:", panduan(x2, wb), "%")
- # 绘图 ===============================================
- # 红色和蓝色是训练集,圈着的是曾经选中的值,灰色的是选中但更新为0
- # 黄色和蓝色是测试集
- for i in range(len(x1[2])): # 对训练集‘上色’
- if x1[2][i] == 1:
- x1[2][i] = 'r' # 训练集 1 红色
- else:
- x1[2][i] = 'b' # 训练集 -1 蓝色
- for i in range(len(x2[2])): # 对测试集‘上色’
- if x2[2][i] == 1:
- x2[2][i] = 'y' # 测试集 1 黄色
- else:
- x2[2][i] = 'g' # 测试集 -1 绿色
- plt.scatter(x1[0], x1[1], c=x1[2], alpha=0.8) # 绘点训练集
- plt.scatter(x2[0], x2[1], c=x2[2], alpha=0.8) # 绘点测试集
- plt.xlabel('x') # x轴标签
- plt.ylabel('y') # y轴标签
- plt.title('y=wx+b') # 标题
- plt.xlim((0, 120))
- plt.ylim((0, 120))
- xl = np.arange(-10, 120, 0.1) # 绘制分类线
- yl = (-wb[0][0] * xl - wb[1]) / wb[0][1]
- plt.plot(xl, yl, 'k')
- plt.show() # 显示

ps:
第78行:
曾经试过这么写
if Ei > E_: # 找偏差最大的
E_ = Ei # 储存偏差最大的值
a2 = i # 储存偏差最大的下标
但是不如找最小的效果好,虽然循环次数减少,但是误差可能会更高。
示例:

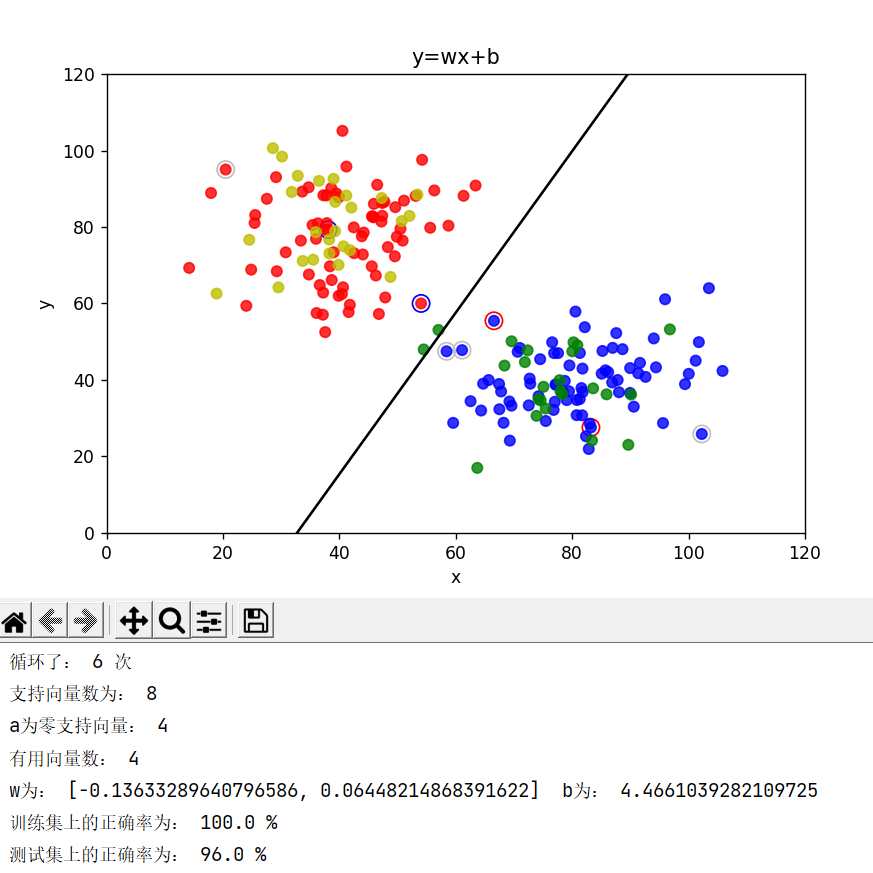
结果实例:
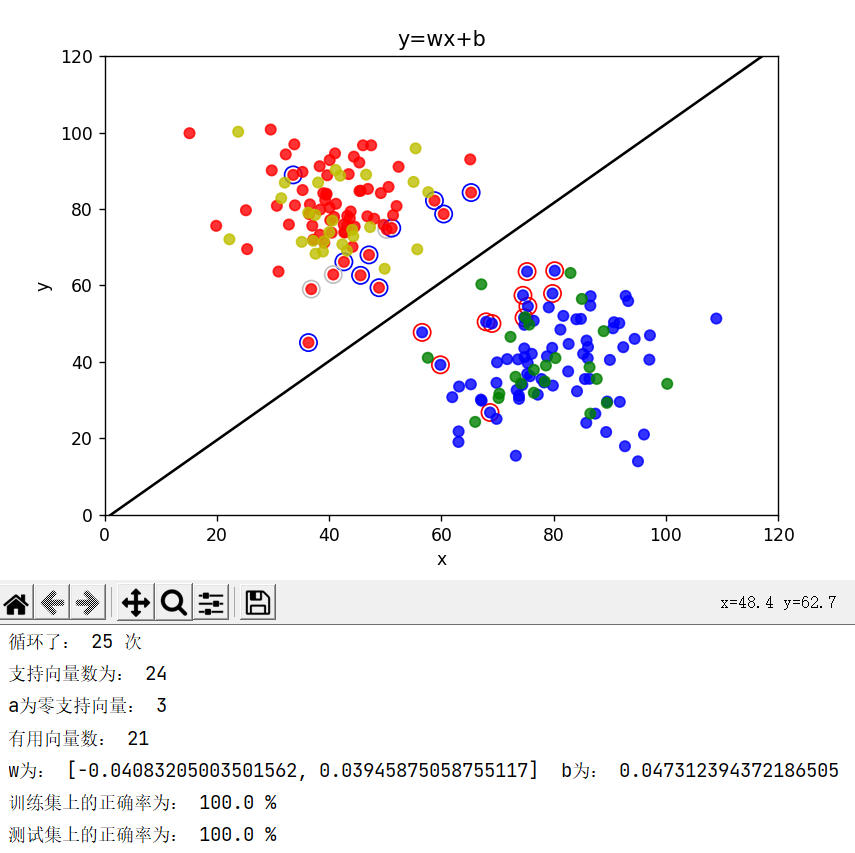
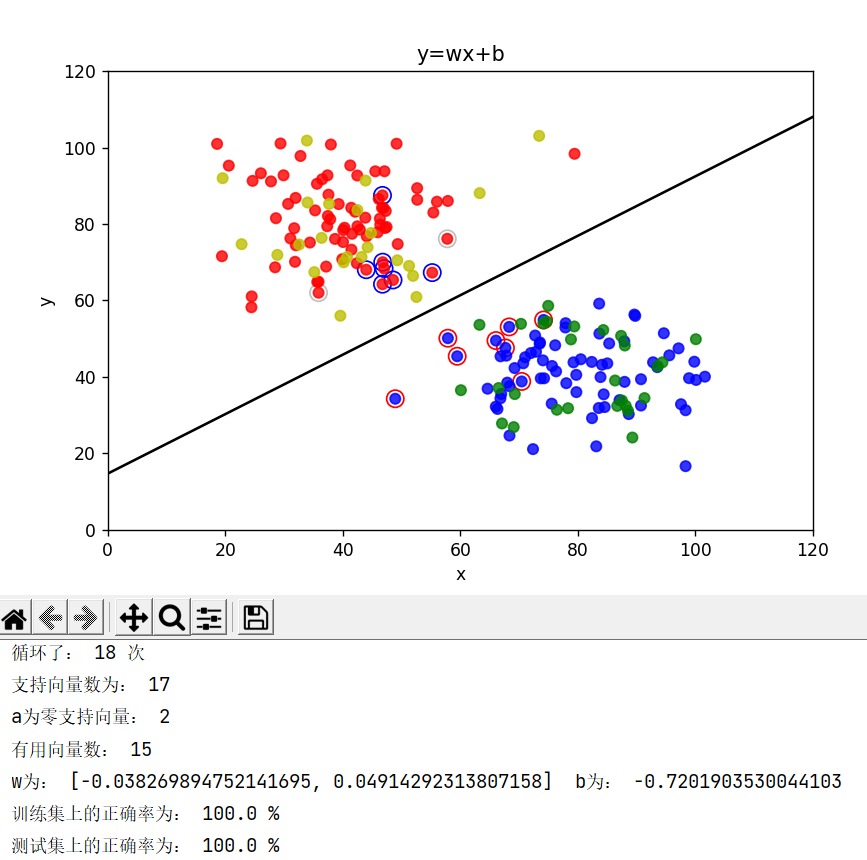
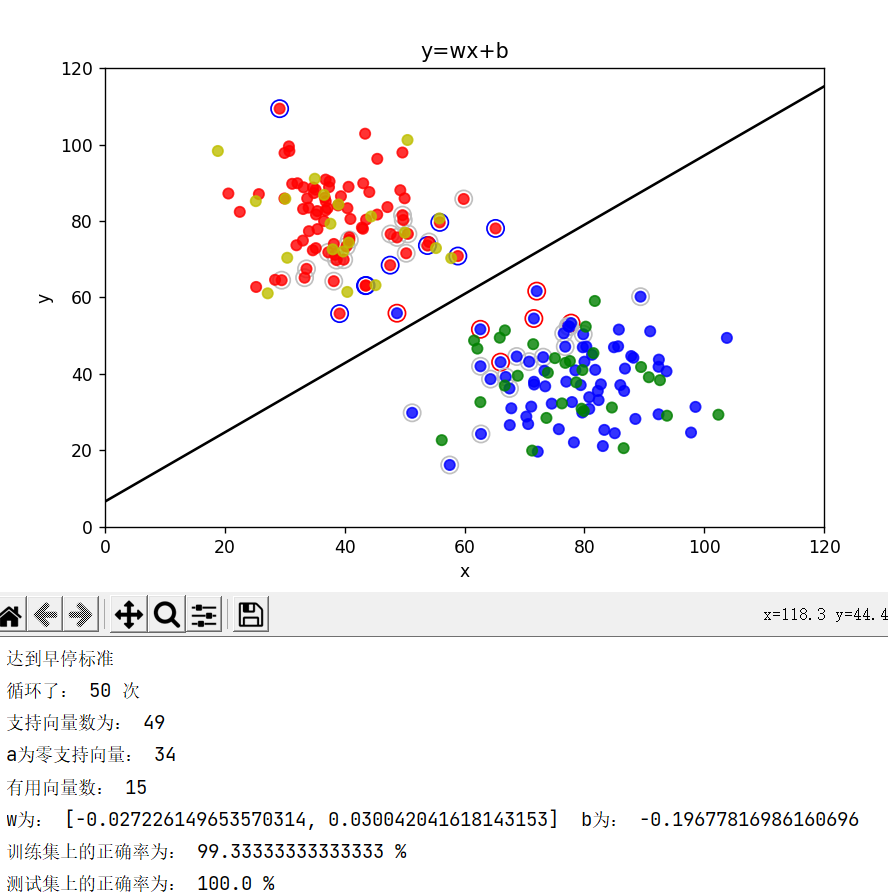
重要的地方:
bug繁多,请多指正。
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/article/detail/53395
推荐阅读


相关标签

