
- 1转载:windows开机自启python服务(任务计划程序+bat脚本)_开机子自启动cmd和flask服务
- 2软件测试常见面试题合集(内附详细答案)_软件测试 的面试题目及答案
- 3深度学习框架-Keras:特点、架构、应用和未来发展趋势_keras框架
- 42024年华为OD机试真题-分配土地-(C++)-OD统一考试(C卷)
- 5IO设备错误,无法运行此项请求,要怎样寻回数据_io设备错误无法运行此项请求
- 6CMAC计算步骤
- 7python函数(4)— 位置参数和关键字参数
- 8基于R语言的文本分类:使用支持向量机
- 9猿人学web端爬虫攻防大赛赛题解析_第十九题:乌拉乌拉乌拉_猿人学题19题
- 10更新Microsoft.PowerShell遇到 尝试更新源失败: winget_尝试更新源失败: winget
任务6 -传统机器学习--SVM_高斯核函数物理意义
赞
踩
SVM原理
SVM是一个二元分类算法,线性分类和非线性分类都支持。经过演进,现在也可以支持多元分类,同时经过扩展,也能应用于回归问题。
这里因为我之前整理过一次SVM,所以不在这里推到SVM的公式,简单列出我学习的思维导图,如有不合理的地方,恳请指出。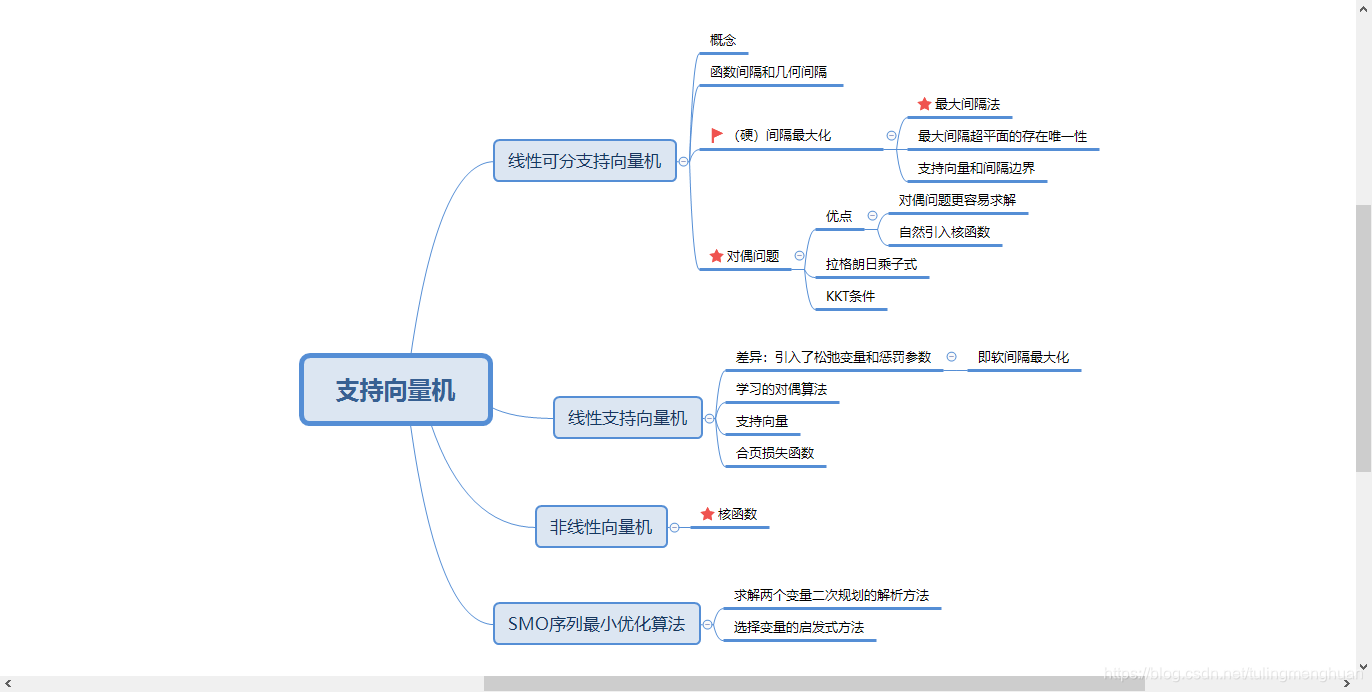
SVM应用场景
文本分类、图像识别、主要二分类领域
SVM的优缺点
SVM优点
1、解决小样本下机器学习问题。
2、解决非线性问题。
3、无局部极小值问题。(相对于神经网络等算法)
4、可以很好的处理高维数据集。
5、泛化能力比较强。
SVM缺点
1、对于核函数的高维映射解释力不强,尤其是径向基函数。
2、对缺失数据敏感
SVM sklearn 参数学习
常用核函数:
1.linear核函数:
K
(
x
i
,
x
j
)
=
x
i
T
x
j
K(x_i,x_j)=x_i^Tx_j
K(xi,xj)=xiTxj
2.polynomial核函数:
K
(
x
i
,
x
j
)
=
(
γ
x
i
T
x
j
+
r
)
d
,
d
>
1
K(x_i,x_j)=(\gamma x_i^Tx_j + r)^d, d>1
K(xi,xj)=(γxiTxj+r)d,d>1
3.RBF核函数(高斯核函数):
K
(
x
i
,
x
j
)
=
e
x
p
(
−
γ
∣
∣
x
i
−
x
j
∣
∣
2
)
,
γ
>
0
K(x_i,x_j)=exp(-\gamma ||x_i-x_j||^2),\gamma>0
K(xi,xj)=exp(−γ∣∣xi−xj∣∣2),γ>0
4.sigmoid核函数:
K
(
x
i
,
x
j
)
=
t
a
n
h
(
γ
x
T
i
x
j
+
r
)
,
γ
>
0
,
r
<
0
K(xi,xj)=tanh(γxTixj+r),γ>0,r<0
K(xi,xj)=tanh(γxTixj+r),γ>0,r<0
首先介绍下与核函数相对应的参数:
1)对于线性核函数,没有专门需要设置的参数
2)对于多项式核函数,有三个参数。-d用来设置多项式核函数的最高次项次数,也就是公式中的d,默认值是3。-g用来设置核函数中的gamma参数设置,也就是公式中的gamma,默认值是1/k(特征数)。-r用来设置核函数中的coef0,也就是公式中的第二个r,默认值是0。
3)对于RBF核函数,有一个参数。-g用来设置核函数中的gamma参数设置,也就是公式中gamma,默认值是1/k(k是特征数)。
4)对于sigmoid核函数,有两个参数。-g用来设置核函数中的gamma参数设置,也就是公式中gamma,默认值是1/k(k是特征数)。-r用来设置核函数中的coef0,也就是公式中的第二个r,默认值是0。
具体来说说**rbf核函数中C和gamma **:
SVM模型有两个非常重要的参数C与gamma。其中 C是惩罚系数,即对误差的宽容度。c越高,说明越不能容忍出现误差,容易过拟合。C越小,容易欠拟合。C过大或过小,泛化能力变差
gamma是选择RBF函数作为kernel后,该函数自带的一个参数。隐含地决定了数据映射到新的特征空间后的分布,gamma越大,支持向量越少,gamma值越小,支持向量越多。支持向量的个数影响训练与预测的速度。
这里面大家需要注意的就是gamma的物理意义,大家提到很多的RBF的幅宽,它会影响每个支持向量对应的高斯的作用范围,从而影响泛化性能。我的理解:如果gamma设的太大,方差会很小,方差很小的高斯分布长得又高又瘦, 会造成只会作用于支持向量样本附近,对于未知样本分类效果很差,存在训练准确率可以很高,(如果让方差无穷小,则理论上,高斯核的SVM可以拟合任何非线性数据,但容易过拟合)而测试准确率不高的可能,就是通常说的过训练;而如果设的过小,则会造成平滑效应太大,无法在训练集上得到特别高的准确率,也会影响测试集的准确率。
参考链接:https://xijunlee.github.io/2017/03/29/sklearn中SVM调参说明及经验总结/
利用SVM模型结合 Tf-idf 算法进行文本分类
# -*- coding: utf-8 -*- import jieba import numpy as np import os import time import codecs import re import jieba.posseg as pseg from sklearn.feature_extraction.text import CountVectorizer from sklearn.feature_extraction.text import TfidfTransformer from sklearn.naive_bayes import MultinomialNB from sklearn.svm import SVC from sklearn.pipeline import Pipeline from sklearn import metrics open=codecs.open path_en='../After/En' path_peo='../After/new_people' content_train_src=[] #训练集文本列表 opinion_train_stc=[] #训练集类别列表 file_name_src=[] #训练集文本文件名列表 train_src=[] #训练集总列表 test_src=[] #测试集总列表 def readfile(path): for filename in os.listdir(path): starttime=time.time() filepath=path+"/"+filename filestr=open(filepath).read() opinion=path[9:] train_src.append((filename,filestr,opinion)) endtime=time.time() print '类别:%s >>>>文件:%s >>>>导入用时: %.3f' % (opinion, filename, endtime - starttime) return train_src train_src_all=readfile(path_en) train_src_all=train_src_all+readfile(path_peo) def readtrain(train_src_list): for (fn,w,s) in train_src_list: file_name_src.append(fn) content_train_src.append(w) opinion_train_stc.append(s) train=[content_train_src,opinion_train_stc,file_name_src] return train def segmentWord(cont): listseg=[] for i in cont: Wordp = Word_pseg(i) New_str = ''.join(Wordp) Wordlist = Word_cut_list(New_str) file_string = ''.join(Wordlist) listseg.append(file_string) return listseg train=readtrain(train_src_all) content=segmentWord(train[0]) filenamel=train[2] opinion=train[1] train_content=content[:3000] test_content=content[3000:] train_opinion=opinion[:3000] test_opinion=opinion[3000:] train_filename=filenamel[:3000] test_filename=filenamel[3000:] test_all=[test_content,test_opinion,test_filename] vectorizer=CountVectorizer() tfidftransformer=TfidfTransformer() tfidf = tfidftransformer.fit_transform(vectorizer.fit_transform(train_content)) # 先转换成词频矩阵,再计算TFIDF值 print tfidf.shape word = vectorizer.get_feature_names() weight = tfidf.toarray() # 分类器 clf = MultinomialNB().fit(tfidf, opinion) docs = ["原任第一集团军副军长", "在9·3抗战胜利日阅兵中担任“雁门关伏击战英雄连”英模方队领队记者林韵诗继黄铭少将后"] new_tfidf = tfidftransformer.transform(vectorizer.transform(docs)) predicted = clf.predict(new_tfidf) print predicted # 训练和预测一体 text_clf = Pipeline([('vect', CountVectorizer()), ('tfidf', TfidfTransformer()), ('clf', SVC(C=1, kernel = 'linear'))]) text_clf = text_clf.fit(train_content, train_opinion) predicted = text_clf.predict(test_content) print 'SVC',np.mean(predicted == test_opinion) print set(predicted) print metrics.confusion_matrix(test_opinion,predicted) # 混淆矩阵

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93

