
热门标签
热门文章
- 1浅谈Volatile三大特性
- 2windows版 docker desktop学习笔记——2 容器仓库管理_docker desktop创建命名空间
- 3STM32f103C8T6的优势是什么?
- 4python对文件操作 r w a 文件复制/修改_r 复制其他文件夹下的文件追加内容
- 5前端登录界面网站设计模板--HTML+CSS
- 6使用Sqoop将Hive数据导出到TiDB
- 7解决浏览器访问Github访问速度慢问题_github加速访问
- 8使用IDA对ipa进行反编译_windows反编译ipa
- 9选择排序 | 冒泡排序 | C语言(详解)
- 10回归预测 | MATLAB实现CNN-GRU-Attention多输入单输出回归预测_机器学习之心 多变量预测回归
当前位置: article > 正文
Python:pycharm爬微博博主博文及转赞评数量_用pycharm爬取微博转赞评
作者:编程变革者 | 2024-02-03 15:22:51
赞
踩
用pycharm爬取微博转赞评
萌新们刚开始爬微博数据一定要用微博手机端的网页https://m.weibo.cn/
用谷歌浏览器,先分析网站结构
进入博主主界面,右键,然后点击检查,点击Network
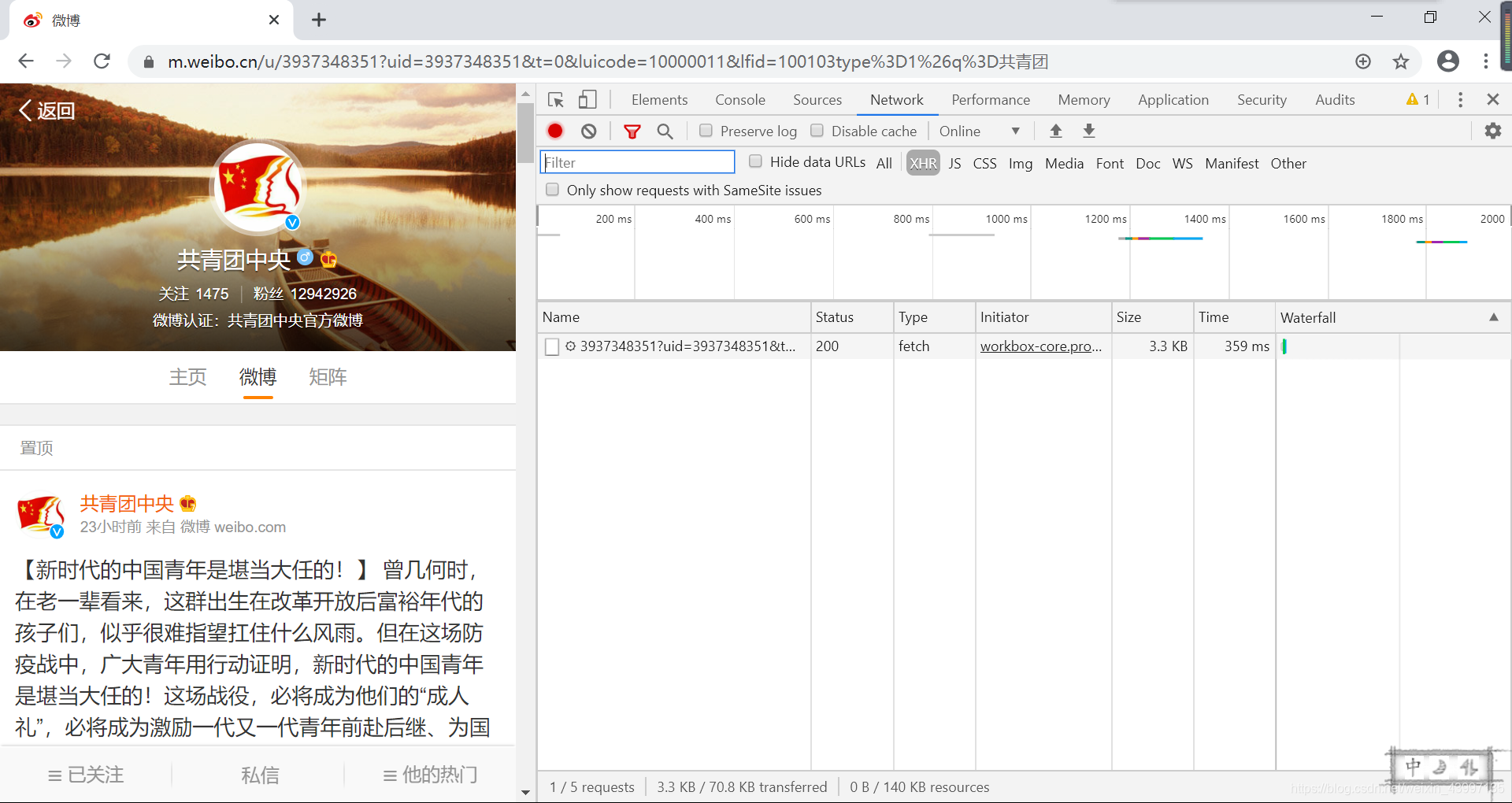
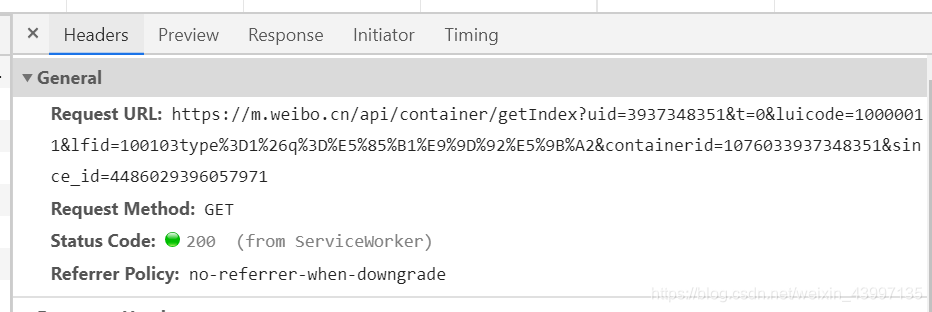

点击Headers container和type在这里找
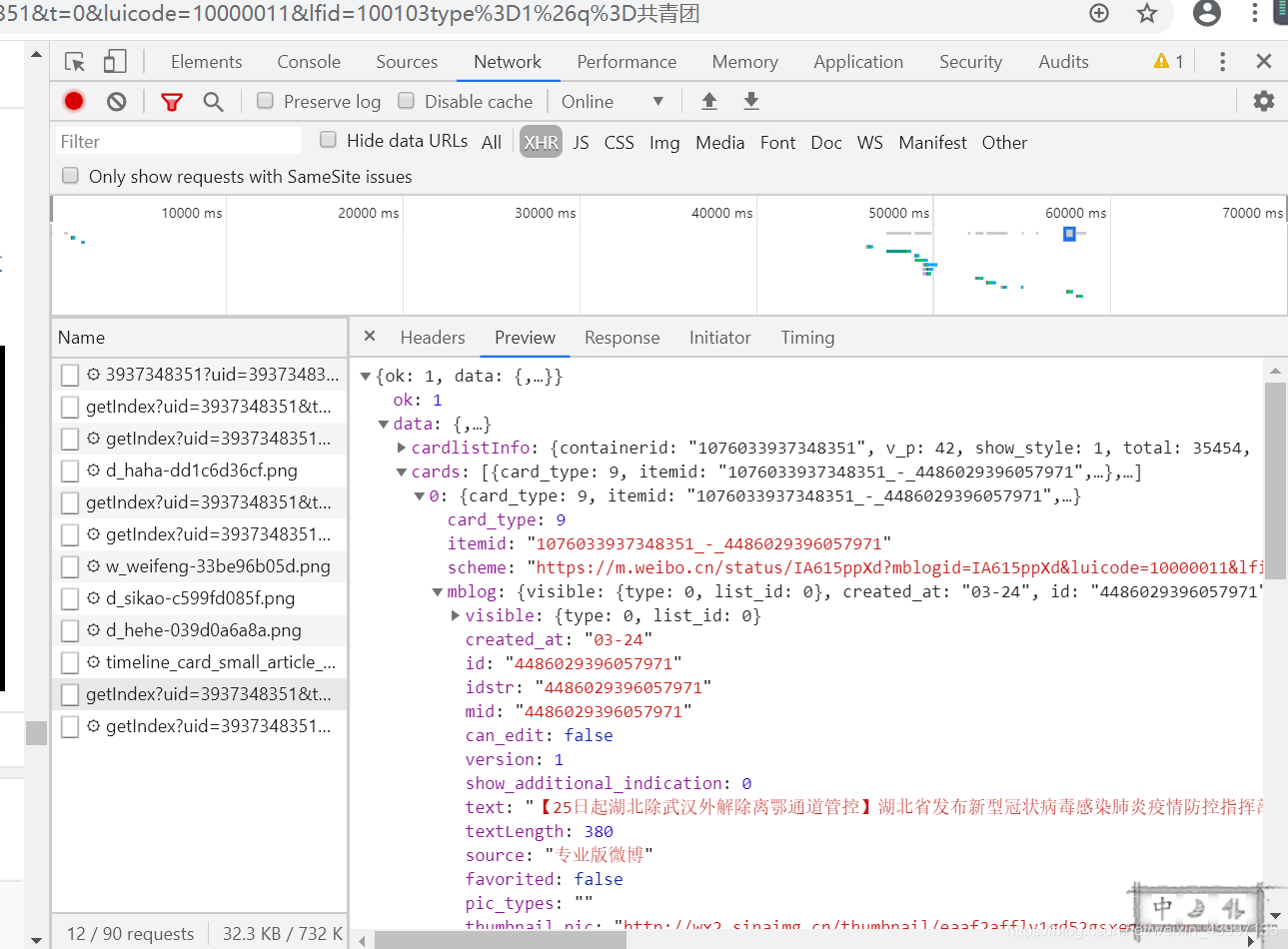
然后preview看网站结构
data,cards,mblog以及要爬取的数据都在这里
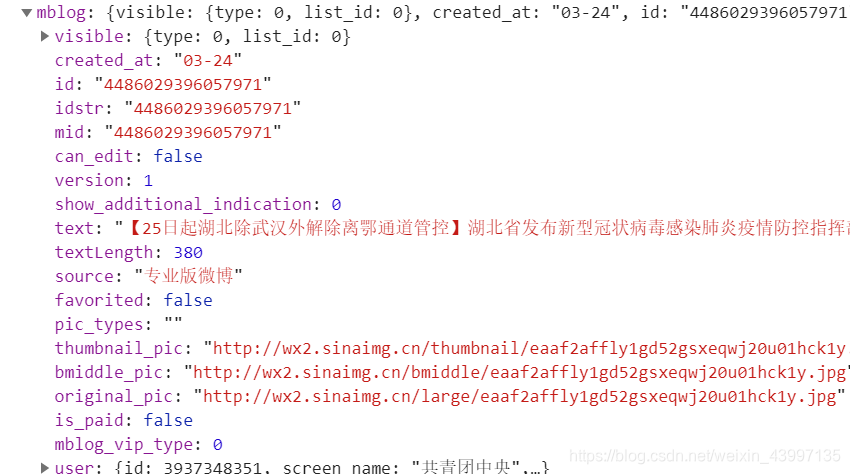
import requests import pprint from urllib.parse import urlencode from pyquery import PyQuery import json base_url='https://m.weibo.cn/api/container/getIndex?' #代码块 请求的方法 #根据页数获取数据 def get_page(page): prames ={ 'containerid':'1076033937348351', 'value':'3937348351', 'page':page } response = requests.get(base_url+urlencode(prames)) return response.json() #解析数据 def prase_data(res_json): if res_json.get('data'): for node in res_json['data']['cards']: item = dict() item['text'] = PyQuery(node['mblog']['text']).text() item['id'] = node['mblog']['id'] item['screen_name'] = node['mblog']['user']['screen_name'] item['attitudes_count'] = node['mblog']['attitudes_count'] item['comments'] = node['mblog']['comments_count'] item['reposts_count'] = node['mblog']['reposts_count'] print(item) def main(): for page in range(1,20): res_jsom = get_page(page) prase_data(res_jsom) if __name__ == '__main__': main() #get_page()

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
爬取结果,下篇介绍如何导入Excel中

声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/article/detail/57160
推荐阅读




相关标签

