
热门标签
热门文章
- 1【毕业季|进击的技术er】作为一个职场人,我想对你们说_纵是世间万象,道却万变不离其
- 2以太坊区块链网络部署及验证实验
- 3Unity导入模型后呈现紫红色_unity模型变成紫红色
- 4汽车网络安全管理体系框架与评价-汽车网络安全管理体系框架
- 5AI智能视频监控系统-监控视频识别人员着装分析报警---豌豆云
- 6Web自动化之Selenium常用操作_driver.find_element
- 7Kali Linux渗透测试之提权(二)——Fgdump、Mimikatz、WCE_渗透测试猕猴桃工具
- 8开源IPad Pro应用IDE:使用SSH远程连接服务器进行云端编程开发
- 9C语言中虚函数的实现及虚函数表解析_虚函数 c语言实现
- 10Python用Tkinter实现体育竞技分析_python借鉴实例15的思路,采用篮球规则模拟比赛,分析体育竞技规律。
当前位置: article > 正文
只需几步即可实现Python对新浪微博手机端的爬虫_手机号查微博号python
作者:程序语言诗人 | 2024-02-03 14:13:48
赞
踩
手机号查微博号python
新浪微博手机端地址 https://m.weibo.cn
我要爬取微博名为[“锦鲤大王”]的2019全部微博
登录微博手机端找到需要的信息
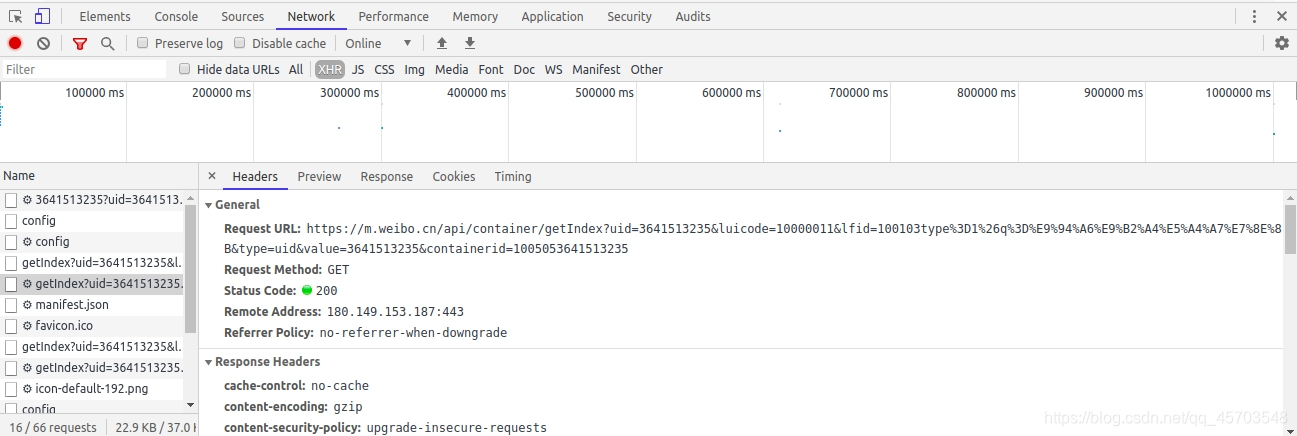
找到Request URL
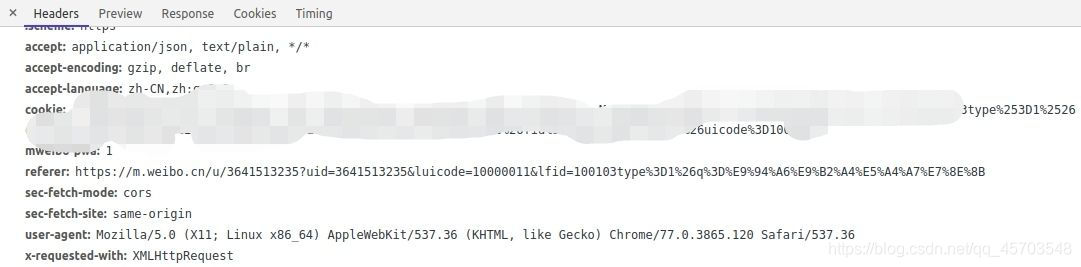
找到user agent 和 cookie
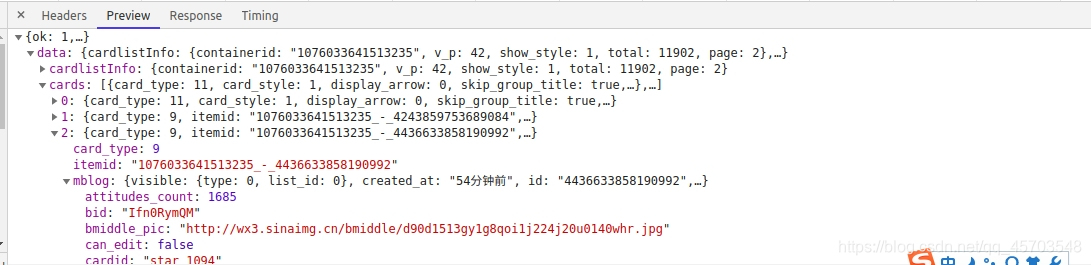
每条微博的具体信息都存放在这里
之后根据上面的信息写爬虫代码,我的爬虫代码很粗糙,没有进一步完善,只是给需要的小伙伴提供一个思路
import requests import csv import time import random import json def spider(page_num): main_url = "https://m.weibo.cn/api/container/getIndex?uid=3641513235&luicode=10000011&" \ "lfid=231093_-_selffollowed&type=uid&value=3641513235&containerid=1076033641513235" # main_url为要爬取博主的主页地址 if page_num: main_url = main_url + '&page=' + str(page_num) # 微博的分页机制是每页10条微博 header = { "user-agent": "Mozilla / 5.0(X11; Linux x86_64) AppleWebKit / 537.36(KHTML, likeGecko) " "Chrome / 77.0.3865.120Safari / 537.36", } # 设置请

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/article/detail/56710?site
推荐阅读




相关标签

