
热门标签
热门文章
- 1Python tkinter (6) —— Listbox控件
- 2CVAE(条件自编码) Condition GAN (条件GAN) 和 VAE-GAN模型之间的区别之CVAE_vae与cvae区别
- 3Antdesign-Vue中抽屉的使用_getcontainer 指定dom
- 4数值分析期末总结三_求积公式的代数精度
- 5QT进度条控件封装(QML)
- 6【Git】解决fatal: unable to access..Failure when receiving data from the peer或者OpenSSL SSL_read: Connect
- 7Git 的基本概念和使用方式
- 8项目管理:如何利用工具做好工作汇报?
- 9AIGC专栏1——Pytorch搭建DDPM实现图片生成_diffusion pytorch
- 10【Vue.js】Vue3全局配置Axios并解决跨域请求问题_前端vue3请求跨域如何解决
当前位置: article > 正文
Python支持向量机
作者:编程变革者 | 2024-02-01 10:50:46
赞
踩
Python支持向量机
Python支持向量机
1 声明
本文的数据来自网络,部分代码也有所参照,这里做了注释和延伸,旨在技术交流,如有冒犯之处请联系博主及时处理。
2 支持向量机简介
相关概念见下:
支持向量机通过寻找训练数据里最大化类之间距离的超平面来来对数据进行分类。
间隔是对是对训练样本里距离分离超平面(决策边界)最近时的距离,这些最近的训练样本叫做支持向量,支持向量机由此得名。
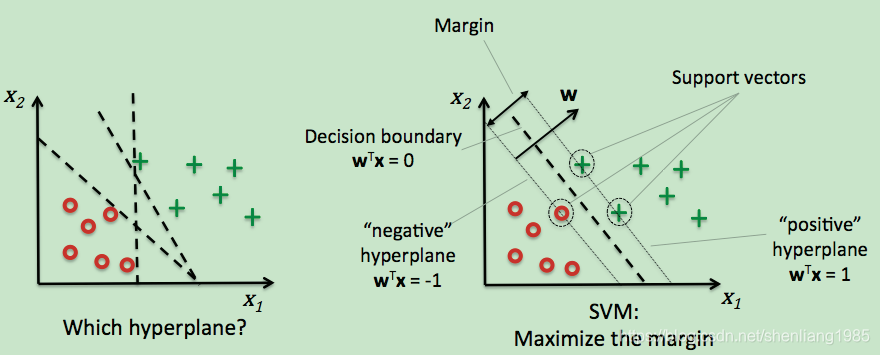
由上图不难发现这里的间隔即为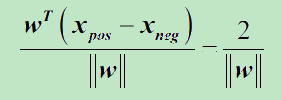
而 这里对最大间隔的求解转换为求ω的最小值。详细的推导这里不再展开,后续再补充。
这里对最大间隔的求解转换为求ω的最小值。详细的推导这里不再展开,后续再补充。
松弛变量
软间隔英文名soft-margin classification记作![]() ,对于非线性可分数据,需要放宽限制,在存在误分类的情况下,加入适当的惩罚,以达到优化收敛的目的。将正的松弛变量添加到线性约束中:
,对于非线性可分数据,需要放宽限制,在存在误分类的情况下,加入适当的惩罚,以达到优化收敛的目的。将正的松弛变量添加到线性约束中: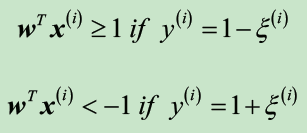
新的目标函数变成: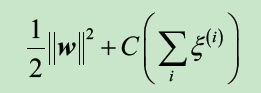
这里C是个控制参数,用它控制对错误分类的惩罚程度。较大的C值对应较大的错误惩罚,对错误分类越敏感,越接近硬间隔,而如果选择较小的C值,则对误分类错误不那么严格。
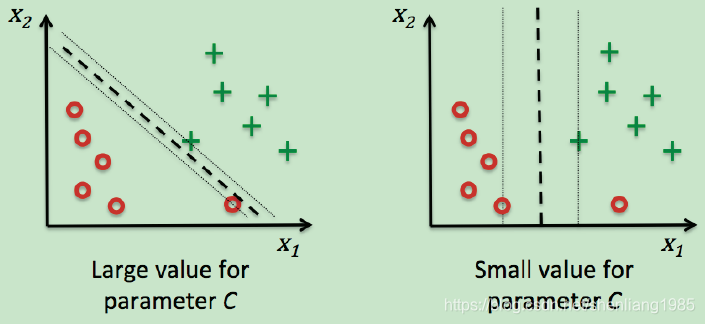
对于数据集线性不可分的,可以将数据映射到高维空间中找到该空间的分离超平面,从而对数据进行分类。
核函数
为了利用支持向量机解决非线性问题,我们通过映射函数![]() 将训练数据转换到一个高维特征空间,并训练一个线性支持向量机模型,在这个新的特征空间对数据进行分类。为了降低两点间点积的昂贵的计算,引进了核函数。常见核函数有:径向基函数核(Radial Basis Function kernel RBF核)或高斯核(Gaussian kernel)
将训练数据转换到一个高维特征空间,并训练一个线性支持向量机模型,在这个新的特征空间对数据进行分类。为了降低两点间点积的昂贵的计算,引进了核函数。常见核函数有:径向基函数核(Radial Basis Function kernel RBF核)或高斯核(Gaussian kernel)
3 支持向量机代码与注释示例
- # 加载相关包
- from sklearn.svm import SVC
- from sklearn import datasets
- from sklearn.preprocessing import StandardScaler
- import numpy as np
- # 加载鸢尾花数据集
- iris = datasets.load_iris()
- features = iris.data
- target = iris.target
- # 标准化特征
- scaler = StandardScaler()
- features_standardized = scaler.fit_transform(features)
- # 常见支持向量机
- svc = SVC(kernel="linear", probability=True, random_state=0)
- # 训练分类
- model = svc.fit(features_standardized, target)
- new_observation = [[.4, .4, .4, .4]]
- # 查看概率值
- print(model.predict_proba(new_observation))
4 总结
无
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/article/detail/53378
推荐阅读


相关标签

