
- 1【Flink Scala】时间语义和Watermark_scala flink event time
- 2Linux--基础开发工具篇(1)(yum)
- 3Visual Studio Code 插件安装_vscode安装插件
- 4简单的渗透(远程反向控制)——kali linux操控Android系统_kali远程入侵安卓手机
- 5java 判断 string null_Java 多个String(字符串)判断是否null(空值)简单方法代码
- 6python 新年代码原创_电脑新年程序代码大全可复制免费软件
- 7【Django】单元测试TestCase、Client的用法_django testcase使用
- 8Git提交规范及使用说明(简略笔记)_git提交规格
- 9linux shell json操作命令 jq 简介_linux shell jq 后面插入
- 10抖音AI图文带货项目玩法教程,0门槛操作简单容易上手操作
Pytorch深度学习之神经网络入门详解_pytorch神经网络高效入门教程
赞
踩
目录
1.将每个图片的label作为txt文件写入另外一个文件夹(txt文件名与图片文件名相同)
Pytorch 入门
1.将每个图片的label作为txt文件写入另外一个文件夹(txt文件名与图片文件名相同)
- root_dir=r"F:\yolo\img"
- target_dir="car_img"
- print(os.path.join(root_dir,target_dir))
- img_path_list=os.listdir(os.path.join(root_dir,target_dir))
- print(img_path_list)
- out_dir="car_label"
- for i in img_path_list:
- file_name=i.split(".jpg")[0]
- f=open((os.path.join(root_dir,out_dir,file_name)+".txt"),"w")
- f.write("car")
- f.close()
2.tensorboard的summary writer
- import numpy as np
- import os
- import cv2 as cv
- from torch.utils.tensorboard import SummaryWriter
- from torchvision import transforms
- writer=SummaryWriter("logs1")
- cv_img=cv.imread(r"F:\yolo\img\street.jpg")
- # for i in range(1,100):
- # writer.add_scalar("y=2x",2*i,i)
- writer.add_image("test_img",cv_img,1,dataformats='HWC')
- tensor_trans=transforms.ToTensor()
- test_img1=tensor_trans(cv_img)
- writer.add_image("test_img",test_img1,2)
- writer.close()
查看可视化结果
控制台 tensorboard --logdir=logs1命令即可
3.torchvision中的transforms
torchvision.transforms是pytorch中的图像预处理包。一般用Compose把多个步骤整合到一起:
- transforms.Compose([
- transforms.CenterCrop(10),
- transforms.ToTensor(),
- ])
下面列举两个常用的 transforms中的函数:
class torchvision.transforms.Normalize(mean, std)
给定均值:(R,G,B) 方差:(R,G,B),将会把Tensor正则化。即:Normalized_image=(image-mean)/std。

实例代码如下:
- import cv2 as cv
- from torch.utils.tensorboard import SummaryWriter
- from torchvision import transforms
- writer=SummaryWriter("logs1")
- cv_img=cv.imread(r"F:\yolo\img\street.jpg")
- tensor_trans=transforms.ToTensor()
- test_img1=tensor_trans(cv_img)
- writer.add_image("test_img",test_img1,1)
- print(test_img1[0][0][0])
- trans_norm=transforms.Normalize([0.5,0.5,0.5],[0.5,0.5,0.5])
- img_norm=trans_norm(test_img1)
- print(img_norm[0][0][0])
- writer.add_image("test_img",img_norm,2)
- writer.close()
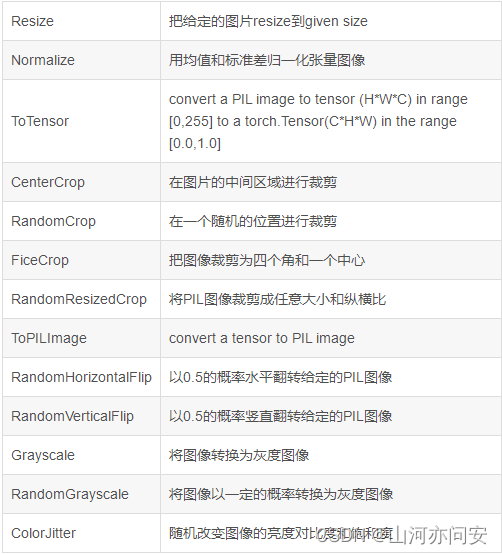
class torchvision.transforms.ToTensor
把一个取值范围是[0,255]的PIL.Image或者shape为(H,W,C)的numpy.ndarray,转换成形状为[C,H,W],取值范围是[0,1.0]的torch.FloadTensor
方法总结如下图:
4.DataLoader
数据加载器。组合数据集和采样器,并在数据集上提供单进程或多进程迭代器。
参数:
- dataset (Dataset) – 加载数据的数据集。
- batch_size (int, optional) – 每个batch加载多少个样本(默认: 1)。
- shuffle (bool, optional) – 设置为
True时会在每个epoch重新打乱数据(默认: False). - sampler (Sampler, optional) – 定义从数据集中提取样本的策略。如果指定,则忽略
shuffle参数。 - num_workers (int, optional) – 用多少个子进程加载数据。0表示数据将在主进程中加载(默认: 0)
- collate_fn (callable, optional) –
- pin_memory (bool, optional) –
- drop_last (bool, optional) – 如果数据集大小不能被batch size整除,则设置为True后可删除最后一个不完整的batch。如果设为False并且数据集的大小不能被batch size整除,则最后一个batch将更小。(默认: False)
- import cv2 as cv
- from torch.utils.tensorboard import SummaryWriter
- from torchvision import transforms
- from torch.utils.data import DataLoader
- import torchvision
- train_set=torchvision.datasets.CIFAR10(root="./dataset",train=True,download=True,transform=torchvision.transforms.ToTensor())
- # shuffle 为true设置为打乱顺序
- train_loader=DataLoader(dataset=train_set,batch_size=64,shuffle=True,num_workers=0,drop_last=False)
- writer=SummaryWriter("logs1")
- step=0
- for data in train_loader:
- imgs,targets=data
- writer.add_images("imgs",imgs,step)
- step=step+1
- break
- writer.close()
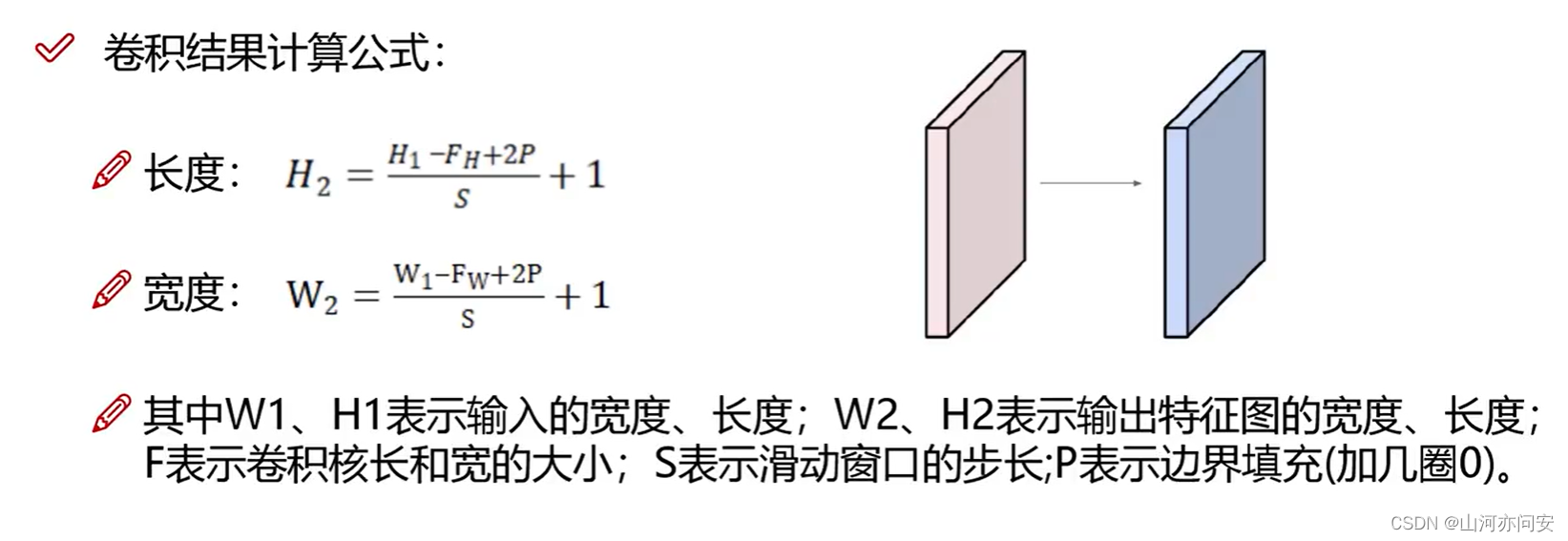
5.神经网络-卷积层Conv2d
class torch.nn.Conv2d(in_channels, out_channels, kernel_size, stride=1, padding=0, dilation=1, groups=1, bias=True)
Parameters:
- in_channels(
int) – 输入信号的通道 - out_channels(
int) – 卷积产生的通道 - kerner_size(
intortuple) - 卷积核的尺寸 - stride(
intortuple,optional) - 卷积步长 - padding(
intortuple,optional) - 输入的每一条边补充0的层数 - dilation(
intortuple,optional) – 卷积核元素之间的间距 - groups(
int,optional) – 从输入通道到输出通道的阻塞连接数 - bias(
bool,optional) - 如果bias=True,添加偏置

- import cv2 as cv
- import torch
- from torch.utils.tensorboard import SummaryWriter
- from torchvision import transforms
- from torch.utils.data import DataLoader
- import torchvision
- train_set=torchvision.datasets.CIFAR10(root="./dataset",train=True,download=True,transform=torchvision.transforms.ToTensor())
- # shuffle 为true设置为打乱顺序
- train_loader=DataLoader(dataset=train_set,batch_size=64,shuffle=True,num_workers=0,drop_last=False)
- from torch import nn
-
- class test(nn.Module):
- def __init__(self):
- super(test, self).__init__()
- self.conv1 = nn.Conv2d(3, 6, 3, stride=1, padding=0)
-
- def forward(self, x):
- x = self.conv1(x)
- return x
- test=test()
- writer=SummaryWriter("logs1")
- step=0
- for data in train_loader:
- imgs,targets=data
- writer.add_images("imgs",imgs,step)
- step=step+1
- output=test(imgs)
- # 由于图片只能以三个通道显示,因此要把6个channel改成3个
- # torch.size([64,6,30,30])->[???,3,30,30]
- # batch_size不知道写多少的时候就写-1,它会自动计算
- output=torch.reshape(output,(-1,3,30,30))
- writer.add_images("imgs", output, step)
- break
- writer.close()
6.最大池化层
参数:class torch.nn.MaxPool2d(kernel_size, stride=None, padding=0, dilation=1, return_indices=False, ceil_mode=False)
- kernel_size(
intortuple) - max pooling的窗口大小 - stride(
intortuple,optional) - max pooling的窗口移动的步长。默认值是kernel_size - padding(
intortuple,optional) - 输入的每一条边补充0的层数 - dilation(
intortuple,optional) – 一个控制窗口中元素步幅的参数 - return_indices - 如果等于
True,会返回输出最大值的序号,对于上采样操作会有帮助 - ceil_mode - 如果等于
True,计算输出信号大小的时候,会使用向上取整,代替默认的向下取整的操作
- import cv2 as cv
- import torch
- from torch.utils.tensorboard import SummaryWriter
- from torchvision import transforms
- from torch.utils.data import DataLoader
- import torchvision
- from torch.nn import MaxPool2d
- train_set=torchvision.datasets.CIFAR10(root="./dataset",train=True,download=True,transform=torchvision.transforms.ToTensor())
- # shuffle 为true设置为打乱顺序
- train_loader=DataLoader(dataset=train_set,batch_size=64,shuffle=True,num_workers=0,drop_last=False)
- from torch import nn
-
- class test(nn.Module):
- def __init__(self):
- super(test, self).__init__()
- self.maxpool1 = MaxPool2d(kernel_size=3, ceil_mode=True)
-
- def forward(self, input):
- output = self.maxpool1(input)
- return output
- test=test()
- writer=SummaryWriter("logs1")
- step=0
- for data in train_loader:
- imgs,targets=data
- writer.add_images("imgs1",imgs,step)
- step=step+1
- output=test(imgs)
- writer.add_images("imgs1", output, step)
- break
- writer.close()
7.非线性激活函数Relu
Relu函数的作用是将将小于0的数据变成为0,实例代码如下:
- from torch.nn import ReLU
- input=torch.tensor([[1,-0.5],
- [-1,3]])
- class test(nn.Module):
- def __init__(self):
- super(test, self).__init__()
- #inplace-选择是否进行覆盖运算
- self.relu1=ReLU(inplace=False)
- def forward(self,input):
- output=self.relu1(input)
- return output
-
- test=test()
- output=test(input)
- print(output)
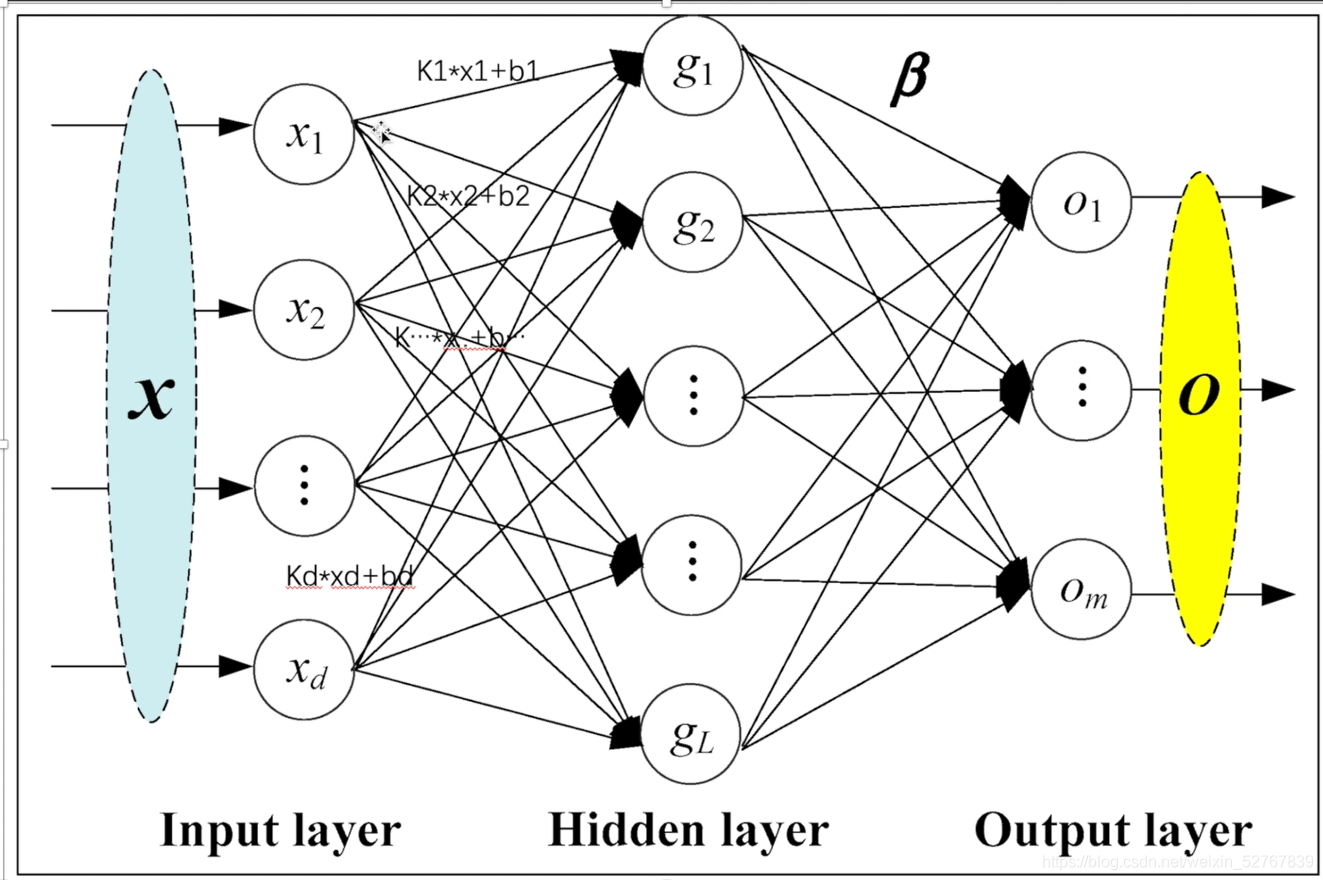
9.线性层
Linear layers
对输入数据做线性变换:y=Ax+b
参数:
- in_features - 每个输入样本的大小
- out_features - 每个输出样本的大小
- bias - 若设置为False,这层不会学习偏置。默认值:True
形状:
- 输入: (N,in_features)(N,in_features)
- 输出: (N,out_features)(N,out_features)
变量:
- weight -形状为(out_features x in_features)的模块中可学习的权值
- bias -形状为(out_features)的模块中可学习的偏置
如下图:
代码实例如下:
- import torch
- import torchvision
- from torch import nn
- from torch.nn import Linear
- from torch.utils.data import DataLoader
-
- dataset=torchvision.datasets.CIFAR10("dataset",train=False,transform=torchvision.transforms.ToTensor(),
- download=True)
- dataloader=DataLoader(dataset,batch_size=64,drop_last=True)
-
- class test(nn.Module):
- def __init__(self):
- super(test, self).__init__()
- self.linear1=Linear(3072,10)
- def forward(self,input):
- output=self.linear1(input)
- return output
- test1=test()
- for data in dataloader:
- imgs,t=data
- print(imgs.shape)
- #将图片线性化
- output=torch.flatten(imgs)
- print(output.shape)
- output=test1(output)
- print(output.shape)
-
- output:
- #torch.Size([64, 3, 32, 32])
- #torch.Size([64, 1, 1, 3072])
- #torch.Size([64, 1, 1, 10])
10.损失函数
损失函数这里列举几个:
class torch.nn.L1Loss(size_average=True)[source]
创建一个衡量输入x(模型预测输出)和目标y之间差的绝对值的平均值的标准。
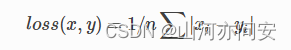
-
x和y可以是任意形状,每个包含n个元素。 -
对
n个元素对应的差值的绝对值求和,得出来的结果除以n。 -
如果在创建
L1Loss实例的时候在构造函数中传入size_average=False,那么求出来的绝对值的和将不会除以n
代码如下实例
- import torch
- from torch.nn import L1Loss
-
- input=torch.tensor([1,2,3],dtype=torch.float32)
- output=torch.tensor([1,2,5],dtype=torch.float32)
- loss=L1Loss()
- result=loss(input,output)
- print(result)
运行结果如下图,如果不需要求平均可以这样设置
loss=L1Loss(reduction="sum")

class torch.nn.MSELoss(size_average=True)[source]
创建一个衡量输入x(模型预测输出)和目标y之间均方误差标准。
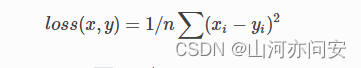
-
x和y可以是任意形状,每个包含n个元素。 -
对
n个元素对应的差值的绝对值求和,得出来的结果除以n。 -
如果在创建
MSELoss实例的时候在构造函数中传入size_average=False,那么求出来的平方和将不会除以n
class torch.nn.CrossEntropyLoss(weight=None, size_average=True)
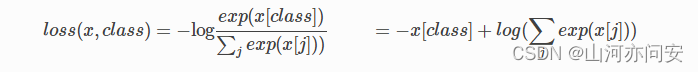
当训练一个多类分类器的时候,这个方法是十分有用的。exp是以e为底的指数函数,在一个猫狗二分类问题中,一个图片经过神经网络模型输出为x[0.5,0.7],其中这张图片的target为0,0代表为猫,1代表为狗,损失函数的计算为-x[0(target)]+ln(exp(x[0])+exp(x[1])。
代码如下
- import torch
- from torch.nn import CrossEntropyLoss
-
- x=torch.tensor([0.1,0.2,0.3])
- y=torch.tensor([1])
- x=torch.reshape(x,(1,3))
- loss=CrossEntropyLoss()
- result=loss(x,y)
- print(result)
11.反向传播和优化器
反向传播 loss.backward()
优化器一般是使用梯度下降的方法进行优化:在梯度法中,函数的取值从当前位置沿着梯度方向前进一定距离,然后在新的地方重新求梯度,再沿着新梯度方向前进,如此反复,不断地沿梯度方向前进。像这样,通过不断地沿梯度方向前进,逐渐减小函数值的过程就是梯度法(gradient method)。梯度法是解决机器学习中最优化问题的常用方法,特别是在神经网络的学习中经常被使用。根据目的是寻找最小值还是最大值,梯度法的叫法有所不同。严格地讲,寻找最小值的梯度法称为梯度下降法(gradient descent method),寻找最大值的梯度法称为梯度上升法(gradient ascent method)。但是通过反转损失函数的符号,求最小值的问题和求最大值的问题会变成相同的问题,因此“下降”还是“上升”的差异本质上并不重要。一般来说,神经网络(深度学习)中,梯度法主要是指梯度下降法。
反向传播和优化器代码实例如下:
- test1=test()
- #lossFunction模型
- loss=nn.CrossEntropyLoss()
- #优化器模型
- optim=torch.optim.SGD(test1.parameters(),0.01)
- #进行20次优化
- for epcho in range (20):
- running_loss=0.0
- for data in dataloader:
- imgs,t=data
- output=test1(imgs)
- loss=loss(output,t)
- #将每个梯度清为0(初始化)
- optim.zero_grad()
- #反向传播,得到每个可调节参数对应的梯度(grad不再是none)
- loss.backward()
- #对每个参数进行改变,weight-data被改变
- optim.step()
- #计算每轮优化中每个变量的loss和
- running_loss=running_loss+result_loss
- print(running_loss)
-
- output:
- #总loss在逐渐变小
- # tensor(18712.0938, grad_fn= < AddBackward0 >)
- # tensor(16126.7949, grad_fn= < AddBackward0 >)
- # tensor(15382.0703, grad_fn= < AddBackward0 >)
12.残差网络
传统的神经网络,由于网络层数增加,会导致梯度越来越小,这样会导致后面无法有效的训练模型,这样的问题成为梯度消弭。为了解决这样的问题,引入残差神经网络(Residual Networks),残差神经网络的核心是”跳跃”+“残差块”。通过引入RN网络,可以有效缓解梯度消失的问题,可以训练更深的网络。
下图是一个基本残差块。它的操作是把某层输入跳跃连接到下一层乃至更深层的激活层之前,同本层输出一起经过激活函数输出。
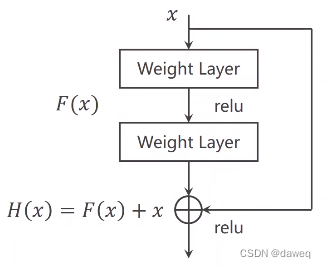
定义残差模型,根据最基本的残差块,残差中间需要经过卷积->激活->卷积这样的操作,为了保证输入输出大小一致,故中间两个卷积层的输入输出大小都和模型最初输入大小保持一致。
- class ResidualBlock(nn.Module):
- def __init__(self, channels):
- super(ResidualBlock, self).__init__()
- self.channels = channels
- self.conv1 = nn.Conv2d(channels, channels, kernel_size=3, padding=1)
- self.conv2 = nn.Conv2d(channels, channels, kernel_size=3, padding=1)
-
- def forward(self, x):
- y = F.relu(self.conv1(x))
- y = self.conv2(y)
- return F.relu(x + y)
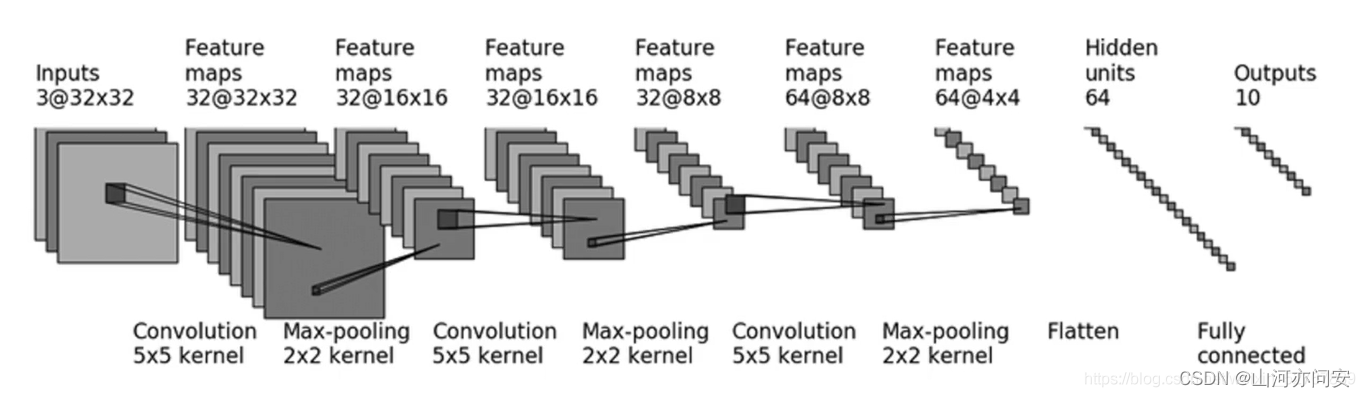
13.CIFAR10模型结构
下面是利用CIFAR10模型结构进行图像分类数据的训练和预测。
- import torch
- import torchvision
- from torch import nn
- from torch.utils.data import DataLoader
- from torch.utils.tensorboard import SummaryWriter
- #import自己写的models
- from p27_1model import *
-
- train_data=torchvision.datasets.CIFAR10("../datasets",train=True,transform=torchvision.transforms.ToTensor(),
- download=True)
- test_data=torchvision.datasets.CIFAR10("../datasets",train=False,transform=torchvision.transforms.ToTensor(),
- download=True)
- #查看数据集长度
- train_size=len(train_data)
- test_size=len(test_data)
- print("size of train,test is:{},{}".format(train_size,test_size))
- #利用dataloader加载
- train_dataloader=DataLoader(train_data,64)
- test_dataloader=DataLoader(test_data,64)
- #创建网络模型
- test1=test()
- #损失函数
- loss_f=nn.CrossEntropyLoss()
- #优化器
- #1e-2=0.01
- learning_rate=1e-2
- opt=torch.optim.SGD(test1.parameters(),lr=learning_rate,)
- #设置训练网络的参数
- #记录训练次数
- train_step=0
- #测试次数
- test_step=0
- #训练轮数
- epoch=10
- #添加tensoeboard
- writer=SummaryWriter("train_log")
-
-
- for i in range(epoch):
- print("第{}轮训练开始".format(i+1))
- #训练步骤开始
- #有时不必要:test1.train()
- for data in train_dataloader:
- imgs,t=data
- output=test1(imgs)
- loss=loss_f(output,t)
- #优化器优化模型
- opt.zero_grad()
- loss.backward()
- opt.step()
- train_step=train_step+1
- #loss.item更加规范(.item不会打印数据类型,例如tensor(5))
- if train_step%100==0:
- print("训练次数{},loss值为{}".format(train_step,loss.item()))
- writer.add_scalar("train_loss",loss.item(),train_step)
- loss_total=0
- #测试步骤开始
- #有时不必要:test1.eval()
- total_correct=0
- with torch.no_grad():
- for data in test_dataloader:
- imgs,t=data
- output=test1(imgs)
- loss=loss_f(output,t)
- loss_total=loss_total+loss.item()
- test_step=test_step+1
- #argmax参数:1为横向比较,2为纵向比较,output为64,10的矩阵
- #output.argmax(1)==t是为了得到[Ture,False,True....]这种形式
- #.sum:T为1,F为0
- corect=(output.argmax(1)==t).sum()
- total_correct=total_correct+corect
- accuracy=total_correct/test_size
- print("测试集总loss{}".format(loss_total))
- writer.add_scalar("test_loss",loss_total,test_step)
- writer.add_scalar("accuracy",accuracy,test_step)
-
- torch.save(test1,"test1{}.pth".format(i))
- print("模型已保存")

