
- 1C++查看完整变量类型_cxxabi.h
- 2Python爬虫(6)-selenium用requests、wget、urllib3这3种方法搞定图片和PDF文件下载_爬虫 如何通过文件下载链接直接获取pdf
- 3VSCode 设置代理
- 4Linux查看系统与资源
- 5SGX Enable_sgx disabled by bios
- 6git rebase合并提交记录_git 合并提交历史记录
- 7【Python入门篇】——Python中判断语句(if elif else语句,判断语句的嵌套与实战案例)_if else语句嵌套的例子
- 8“Git:不容错过的现代化版本控制系统” 基础入门篇_初探git,理解和使用版本控制的魔法
- 9蓝桥杯第十三届青少年Python组省赛试题_十三届蓝桥杯python组省赛试题
- 10【收藏】Linux系统常用命令速查手册(附PDF下载方式)_linux命令大全详解pdf
【Flink Scala】时间语义和Watermark_scala flink event time
赞
踩
时间语义
Flink中的时间语义
在Flink的流式处理中,会涉及到时间的不同概念,如下图所示:

Event Time:是事件创建的时间。它通常由事件中的时间戳描述,例如采集的 日志数据中,每一条日志都会记录自己的生成时间,Flink 通过时间戳分配器访问事 件时间戳。
Ingestion Time:是数据进入 Flink的时间。
Processing Time:是每一个执行基于时间操作的算子的本地系统时间,与机器 相关,默认的时间属性就是Processing Time
例如,一条日志进入 Flink的时间为 2017-11-12 10:00:00.123,到达 Window 的 系统时间为 2017-11-12 10:00:01.234,日志的内容如下:
2017-11-02 18:37:15.624 INFO Fail over to rm2
- 1
Event Time的引入
在 Flink 的流式处理中,绝大部分的业务都会使用 eventTime,一般只在 eventTime 无法使用时,才会被迫使用 ProcessingTime或者IngestionTime。
如果要使用EventTime,那么需要引入 EventTime 的时间属性,引入方式如下所示
val env = StreamExecutionEnvironment.getExecutionEnvironment
// 从调用时刻开始给 env 创建的每一个 stream 追加时间特征
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime)
- 1
- 2
- 3
我们可以看到TimeCharacteristic是枚举时间类型
// // Source code recreated from a .class file by IntelliJ IDEA // (powered by FernFlower decompiler) // package org.apache.flink.streaming.api; import org.apache.flink.annotation.PublicEvolving; @PublicEvolving public enum TimeCharacteristic { ProcessingTime, IngestionTime, EventTime; private TimeCharacteristic() { } }

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
三个参数就是三个时间语义
事件时间语义不能简简单单的设置一下,需要设置一下那个字段作为时间语义
Waterkmark(水位线)
基本概念
我们知道,流处理从事件产生,到流经source,再到 operator,中间是有一个过 程和时间的,虽然大部分情况下,流到operator的数据都是按照事件产生的时间顺 序来的,但是也不排除由于网络、分布式等原因,导致乱序的产生,所谓乱序,就 是指Flink接收到的事件的先后顺序不是严格按照事件的Event Time顺序排列的。

那么此时出现一个问题,一旦出现乱序,如果只根据 eventTime决定 window的运行,我们不能明确数据是否全部到位,但又不能无限期的等下去,此时必须要有 个机制来保证一个特定的时间后,必须触发 window去进行计算了,这个特别的机 制,就是 Watermark。
-
Watermark是一种衡量Event Time进展的机制。 -
Watermark是用于处理乱序事件的,而正确的处理乱序事件,通常用Watermark机制结合window来实现。 -
数据流中的
Watermark用于表示timestamp小于Watermark的数据,都已经 到达了,因此,window的执行也是由Watermark触发的。 -
Watermark可以理解成一个延迟触发机制,我们可以设置Watermark的延时时长t,每次系统会校验已经到达的数据中最大的maxEventTime,然后认定eventTime小于maxEventTime - t的所有数据都已经到达,如果有窗口的停止时间等于maxEventTime – t,那么这个窗口被触发执行。 -
其实也就是说,
WaterMark是一个时间的延迟,当时间事件到达之后,不立即计算,而是等待一段时间,上图的理想情况,以事件时间做系统时间,因为有有序的所以没问题,但是遇到无序事件时间时,如果大的时间时间先到,就会出现问题,因为时间是不可倒退的,所以需要设置一个时延,当5秒的数据输入时,此时认为系统时间为2秒
Watermark的特点
Watermark是一条特殊的数据记录Watermark必须单调递增,以确保任务的事件时间再向前推进,而不是在后退Watermark与数据的时间戳相关
理解案例
有序流的Watermark如下图所示,Watermark设置为0

我们可以看到,事件时间和系统时间是一致的

乱序流的Watermark,Watermark设置为2

当 Flink接收到数据时,会按照一定的规则去生成 Watermark,这条 Watermark 就等于当前所有到达数据中的 maxEventTime - 延迟时长,也就是说,Watermark 是 基于数据携带的时间戳生成的,一旦 Watermark比当前未触发的窗口的停止时间要 晚,那么就会触发相应窗口的执行。由于 event time是由数据携带的,因此,如果 运行过程中无法获取新的数据,那么没有被触发的窗口将永远都不被触发。
上图中,我们设置的允许最大延迟到达时间为 2s,所以时间戳为7s 的事件对应 的 Watermark是5s,时间戳为 12s的事件的 Watermark是 10s,如果我们的窗口 1是 1s~5s,窗口2是 6s~10s,那么时间戳为 7s的事件到达时的 Watermarker恰好触 发窗口 1,时间戳为 12s 的事件到达时的 Watermark恰好触发窗口 2。
Watermark是触发前一窗口的“关窗时间”,一旦触发关门那么以当前时刻 为准在窗口范围内的所有所有数据都会收入窗中。
只要没有达到水位那么不管现实中的时间推进了多久都不会触发关窗。
还可以理解成,在读入数据后不是立即处理的而是还有一个装桶的操作,当触发了关窗时就会进行关桶的操作
假定我们设延时为3S

当数据1来的时候,当前最大时间戳是1,1-3(延时)是小于5(窗口),任何将数据1装入所对应的桶,然后以继续,不执行任何操作
然后每一次时间戳来时,都需要比较最大的时间戳-延时是否大于某个窗口,大于的话就需要关闭,然后将数据放入所对应的桶

当数据8来时,时间戳-时延是5,已经大于第一个窗口了,所以0-5这个窗口需要关闭,此时就算此窗口有还未装入的数据也不会再读取,会被丢弃
我们上面只是考虑了分区数为1的watermark出现的状况,但是当数据出现并行或者分区时,该如何确定使用哪一个Watermark?

如Task处理其他分区传递的数据,当其他分区传输的watermark不一致时,Task会自己先创建一个分区watermark,然后以最小的来作为自己的watermark,设Task有接收两个watermark的结果,一个是2(代表2以前的数据都已经接收完毕),一个是3(代表3以前的数据都已经接受完毕),这时Task会选择以2作为自己的watermark时钟
Watermark的导入
如上述所示,有两种导入的方法,一直是升序数据的导入,也就是排好序的数据,具体入方式如下
package Window import Source.SensorReading import org.apache.flink.streaming.api.TimeCharacteristic import org.apache.flink.streaming.api.scala.StreamExecutionEnvironment import org.apache.flink.streaming.api.scala._ class WatermarkTest { def main(args: Array[String]): Unit = { val env = StreamExecutionEnvironment.getExecutionEnvironment //设置并行度 env.setParallelism(1) //时间语义(TimeEvent) env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime) val inputStream = env.socketTextStream("localhost", 7777) //转换成样例类 val dataStream = inputStream .map(data => { val arr = data .split(",") SensorReading(arr(0), arr(1).toLong, arr(2).toDouble) }) .assignAscendingTimestamps(_.timeStamp * 1000l) } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
assignAscendingTimestamps所需要的参数是一个毫秒数据
乱序数据导入方式如下
所需要使用到的方法是:assignTimestampsAndWatermarks()

我们发现有两个实现方法,第一个是周期性生成Watermark,就是上面讲的那种;第二个是断点式生成,每来一个数据就判断是否需要生成
周期性生成适用于数据密集型的数据,断点式适用于数据稀疏的数据
.assignTimestampsAndWatermarks(new BoundedOutOfOrdernessTimestampExtractor[SensorReading](Time.seconds(3)) {
override def extractTimestamp(t: SensorReading) = t.timeStamp * 1000l
})
- 1
- 2
- 3
如何准确的设置watermark值?,我们可以先设置一个小的时延,然后设置迟到再一定时间内的数据也放入计算,最后设置一个侧输出流
package WindowAndWatermark import Source.SensorReading import org.apache.flink.streaming.api.TimeCharacteristic import org.apache.flink.streaming.api.functions.timestamps.BoundedOutOfOrdernessTimestampExtractor import org.apache.flink.streaming.api.scala.StreamExecutionEnvironment import org.apache.flink.streaming.api.scala._ import org.apache.flink.streaming.api.windowing.time.Time class WatermarkTest { def main(args: Array[String]): Unit = { val env = StreamExecutionEnvironment.getExecutionEnvironment //设置并行度 env.setParallelism(1) //事件时间 env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime) val inputStream = env.socketTextStream("localhost", 7777) //转换成样例类 val dataStream = inputStream .map(data => { val arr = data .split(",") SensorReading(arr(0), arr(1).toLong, arr(2).toDouble) }).assignTimestampsAndWatermarks( new BoundedOutOfOrdernessTimestampExtractor[SensorReading](Time.milliseconds(3)) { override def extractTimestamp(t: SensorReading) = t.timeStamp }) //每十五秒统计窗口内个传感器的温度最小值,以及最新的时间戳 val resultStream = dataStream .map(data => (data.id, data.temperature, data.timeStamp)) .keyBy(_._1) //按照二元组第一个元素id分组 .timeWindow(Time.seconds(5)) .allowedLateness(Time.minutes(1)) //设置迟到数据 .sideOutputLateData(new OutputTag[(String, Double, Long)]("late")) //迟到的流 .reduce((CurRes, newData) => (CurRes._1, CurRes._2.min(newData._2), newData._3)) resultStream.print("res") env.execute() } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
上文我们使用的是周期性生成的watermark,那么问题就来了,周期是多少?,这点我们可以通过源码来看到
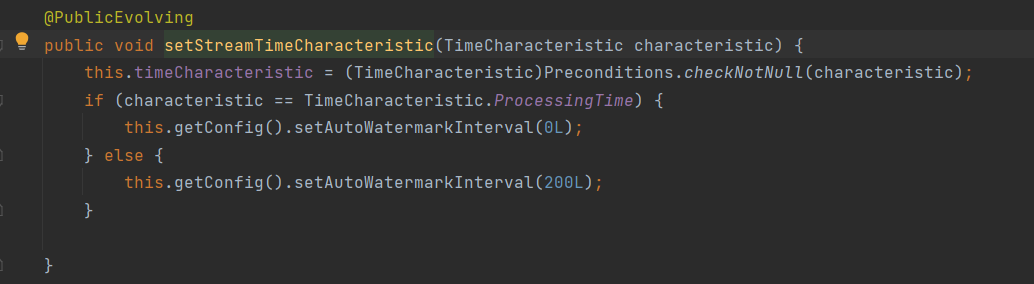
当时间语义是Process时,周期是0;当时间语义是其他的时候,周期是200
我们也可以自己设置周期
env.getConfig.setAutoWatermarkInterval(150l)
- 1
自定义生成watermark
自定义一个周期性的时间戳抽取
class PeriodicAssigner extends AssignerWithPeriodicWatermarks[SensorReading] {
val bound = 60 * 1000l //延时为1分钟
var maxTS = Long.MinValue //观察到最大的时间戳
override def getCurrentWatermark: Watermark = {
new Watermark(maxTS - bound) //判断是否关闭窗口
}
override def extractTimestamp(t: SensorReading, l: Long): Long = {
maxTS = maxTS.max(t.timeStamp) //更新最大值
t.timeStamp //取出时间戳
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
AssignerWithPeriodicWatermarks 的 getCurrentWatermark()方法。如果方法返回一个 时间戳大于之前水位的时间戳,新的 watermark会被插入到流中。这个检查保证了 水位线是单调递增的。如果方法返回的时间戳小于等于之前水位的时间戳,则不会 产生新的watermark
该如何使用?
.assignTimestampsAndWatermarks(new PeriodicAssigner)
- 1
间断式地生成 watermark。和周期性生成的方式不同,这种方式不是固定时间的, 而是可以根据需要对每条数据进行筛选和处理。直接上代码来举个例子,我们只给sensor_1的传感器的数据流插入 watermark
class PunctuatedAssigner extends AssignerWithPunctuatedWatermarks[SensorReading] {
val bound = 60 * 1000l
override def checkAndGetNextWatermark(t: SensorReading, l: Long): Watermark = {
if (t.id == "sensor_1") {
new Watermark(l - bound)
} else {
null
}
}
override def extractTimestamp(t: SensorReading, l: Long): Long = {
t.timeStamp
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15





