
- 1华南X99主板安装ESXi7.0或ESXi8.0的配置说明_esxi 8.0 瑞昱 rtl8168
- 2小程序 rich-text 富文本回显 解决video节点不显示问题_微信小程序rich-text video
- 3【MATLAB】高斯分布 均匀分布 以及其他分布 的随机数生成函数
- 4angular 安装batarang踩到的那些坑儿_angularjs batarang chrome
- 5云计算技术,主要包含哪些关键技术?_云计算的关键技术包括
- 6Sublime Text 3配置 Java 开发环境_sublimetext配java
- 7基于FPGA的可变模计数器VHDL代码Quartus仿真
- 8开源啦!!!轻量级工作流引擎管理系统
- 9图像处理之轮廓特征_传统处理轮廓特征图
- 10C# 封面图片生成器_c# 使用color生成图片
Elasticsearch在flink中的应用_elasticsearch + flink
赞
踩
Flink数据下沉到Elasticsearch示例
简介
当初做课程设计的时候,找到的flink接入elasticsearch的文章除了flink的文档示例之外版本都挺老的,所以自己按照flink的文档把原来的改造了一下。现在再更新最新版本,然后做一下整理。
最新版本flink1.12,scala2.12.7,elasticsearch7.10.1,kibana7.10.1。
flink1.10更新至1.12说明
在开始之前需要提一下flink和es更新之后的一些问题。
1.flink1.11的更新
提交任务的时候报了IllegalStateException: No ExecutorFactory found to execute the application.原因是缺少flink-clients的依赖。

意思就是说,从flink1.11开始,flink-streaming-java这个模块不再有flink-clients的依赖了,如果项目需要这个依赖就要在maven的pom.xml文件里自己加上去。
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients_2.12</artifactId>
<version>${flink.version}</version>
</dependency>
- 1
- 2
- 3
- 4
- 5
2.flink1.12的更新
更新了一些过时的方法。
2.1timeWindow过时更新

timeWindow方法过时了,以后都用window(windowAssigner)这个方法。windowAssigner就是几种window的类型,如TumblingEventTimeWindows,SlidingEventTimeWindows,TumblingProcessingTimeWindows,SlidingProcessingTimeWindows。
2.2默认TimeCharacteristic设置为event time
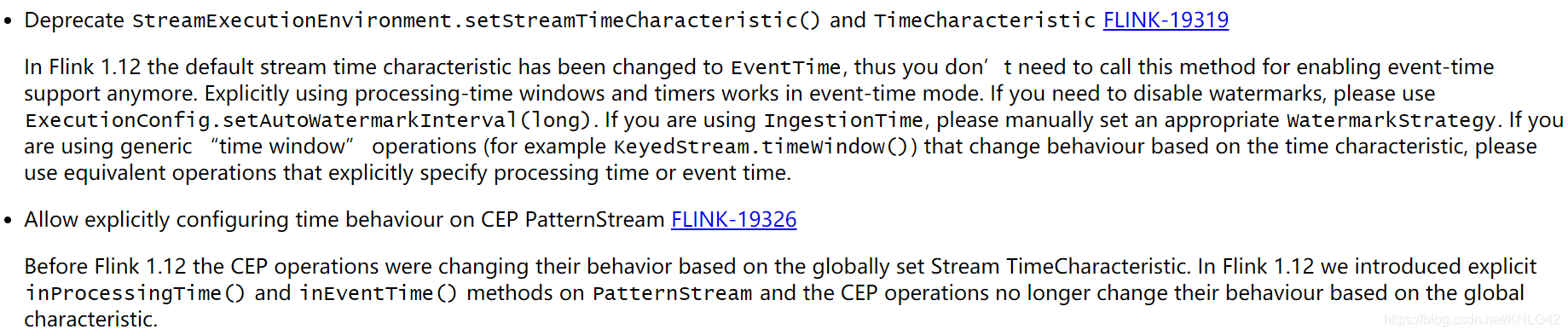
以前本来要env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime),从flink1.12开始这句话就不用了。
2.3清理了过时的DataStream#fold()方法

fold()永远地从api列表里清楚了,以后就用reduce吧。这两个的区别也不是很大,就是fold可以设置一个累加器初始值然后累加,而reduce是两个元素合并。
任务说明
这个demo来源于https://github.com/dataartisans/flink-streaming-demo。它是flink的官方DataStream APi的demo,不过版本非常老旧,flink0.10.0版本,es1.7.1版本。当初的课程设计是升级到flink1.10版本,并能够把输出下沉到es,然后用kibana可视化显示结果。现在flink已经来到了1.12,那么这个demo也就要更新到最新版。
这个demo有三个任务,如下:
1.识别流量大的区域
TotalArrivalCount.scala识别纽约市流量大的区域。它接收出租车搭乘事件的流,并计算每个地点租车到达的人数。
2.识别过去十五分钟流量大的区域
SlidingArrivalCount.scala 识别过去十五分钟流量大的区域。它会收集出租车搭乘记录,并每隔5分钟计算出过去15分钟内到达每个地点的人数。这种类型的计算称为滑动窗口(sliding window)。
3.计算流量大的区域之前的流量
一些流处理用例依赖于及时的事件聚合,例如发送通知或警报。 EarlyArrivalCount.scala 扩展了我们之前的滑动窗口应用程序。和之前那个程序一样,它每五分钟计算一次在过去15分钟内到达每个地点的人数。此外,当50人到达一个位置时,它会发出一个早期的部分计数,也就是说,如果超过50、100、150(等等)人到达一个位置,它会发出一个更新的计数。
另外比较关键的是,大数据分析中比较重要的东西就是模型,一个好的模型可以让我们分析数据做到事半功倍。官方已经为我们提供了一个数据模型TaxiRide。
rideId: Long // 每次搭乘的唯一id
time: DateTime // 开始、结束事件的时间戳
isStart: Boolean // 搭乘是否开始
location: GeoPoint // 上车、下车的经纬度
passengerCnt: short // 乘客数量
travelDist: float // 总的距离,如果是搭乘开始事件,那么值为-1
- 1
- 2
- 3
- 4
- 5
- 6
我们将通过这个模型,去达成这三个任务。那么,接下来就开始吧。
任务一:TotalArrivalCount
先给出流程图。
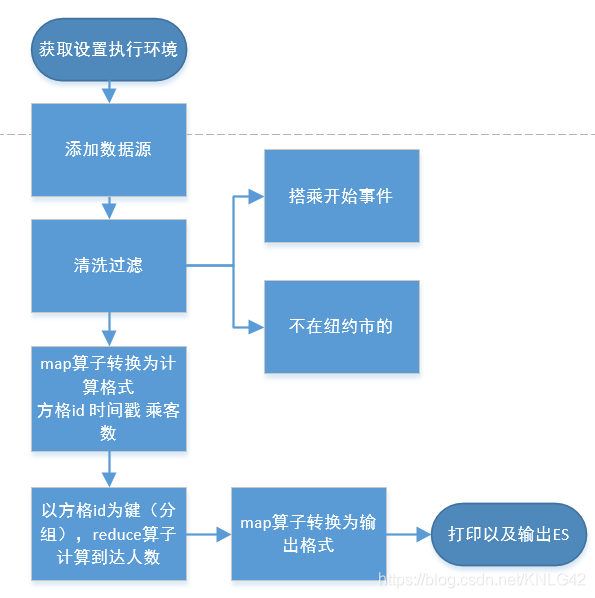
//设置执行环境 val env = StreamExecutionEnvironment.getExecutionEnvironment //添加数据源 val rides: DataStream[TaxiRide] = env.addSource(new TaxiRideSource( data, maxServingDelay, servingSpeedFactor)) val cleansedRides = rides //过滤掉开始事件 .filter(new FilterFunction[TaxiRide] { override def filter(t: TaxiRide): Boolean = !t.isStart }) //过滤掉不在纽约市的事件 .filter(new FilterFunction[TaxiRide] { override def filter(t: TaxiRide): Boolean = NycGeoUtils.isInNYC(t.location) }) //map算子转换为计算需要的格式cell Id, timestamp, passenger count val cellIds: DataStream[(Int, Long, Short)] = cleansedRides .map { new MapFunction[TaxiRide,(Int, Long, Short)] { override def map(t: TaxiRide): (Int, Long, Short) = (NycGeoUtils.mapToGridCell(t.location), t.time.getMillis, t.passengerCnt) } } val passengerCnts: DataStream[(Int, Long, Int)] = cellIds //设cell id为键转为KeydStream .keyBy(a => a._1) //计算每个cell id的搭乘人数和 .reduce((r, s) => (s._1, r._2.max(s._2), (r._3 + s._3).toShort)) .map(r => (r._1, r._2, r._3.toInt)) //map算子转换回GeoPoint输出格式 val cntByLocation: DataStream[(Int, Long, GeoPoint, Int)] = passengerCnts .map( r => (r._1, r._2, NycGeoUtils.getGridCellCenter(r._1), r._3 ) ) //打印 cntByLocation .print() if (writeToElasticsearch) { //下沉到ES,这个后面会单独讲 cntByLocation .addSink(new CntTimeByLocUpsert(elasticsearchHost, elasticsearchPort)) } env.execute("Total passenger count per location")

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
任务二:SlidingArrivalCount
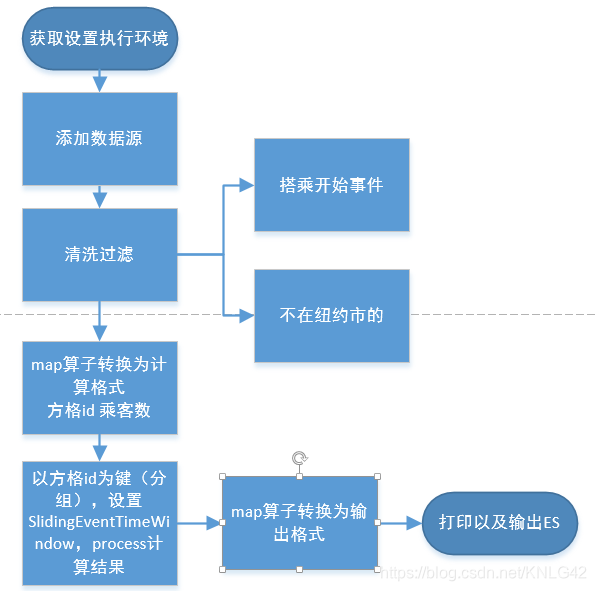
//map算子转换为计算需要的格式cell Id, passenger count val cellIds: DataStream[(Int, Short)] = cleansedRides .map(new MapFunction[TaxiRide, (Int, Short)] { override def map(t: TaxiRide): (Int, Short) = (NycGeoUtils.mapToGridCell(t.location), t.passengerCnt) }) val passengerCnts: DataStream[(Int, Long, Int)] = cellIds .keyBy(a => a._1) //设置滑动窗口 .window(SlidingEventTimeWindows.of(Time.minutes(countWindowLength), Time.minutes(countWindowFrequency)))、 //数据处理,窗口里面的元素根据cell id合并,在窗口结束时返回 .process(new ProcessWindowFunction[(Int, Short), (Int, Long, Int), Int, TimeWindow] { override def process(key: Int, context: Context, elements: Iterable[(Int, Short)], out: Collector[(Int, Long, Int)]): Unit = out.collect((key, context.window.getEnd, elements.map(_._2).sum)) })
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
任务三:EarlyArrivalCount
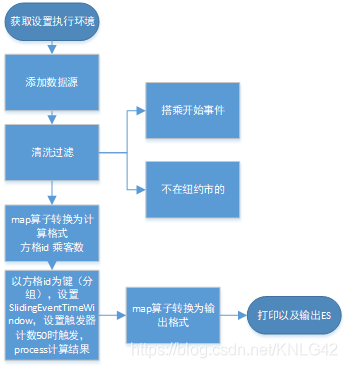
val passengerCnts: DataStream[(Int, Long, Int)] = cellIds .keyBy(a => a._1) .window(SlidingEventTimeWindows.of(Time.minutes(countWindowLength), Time.minutes(countWindowFrequency))) //注册触发器 .trigger(new EarlyCountTrigger(earlyCountThreshold)) .process(new ProcessWindowFunction[(Int, Short), (Int, Long, Int), Int, TimeWindow] { override def process(key: Int, context: Context, elements: Iterable[(Int, Short)], out: Collector[(Int, Long, Int)]): Unit = out.collect((key, context.window.getEnd, elements.map(_._2).sum)) }) class EarlyCountTrigger(triggerCnt: Int) extends Trigger[(Int, Short), TimeWindow] { val stateDescriptor = new ValueStateDescriptor[Integer]("personCnt", Integer.TYPE) override def onElement( event: (Int, Short), timestamp: Long, window: TimeWindow, ctx: TriggerContext): TriggerResult = { //注册timer ctx.registerEventTimeTimer(window.getEnd) //获取当前状态,这个状态就是指乘客的数量 val personCnt = ctx.getPartitionedState(stateDescriptor) //更新乘客数量 personCnt.update(personCnt.value() + event._2) if (personCnt.value() < triggerCnt) { //没达到要求继续 TriggerResult.CONTINUE } else { //到达要求的乘客数量(50) personCnt.update(0) TriggerResult.FIRE } } override def onEventTime( time: Long, window: TimeWindow, ctx: TriggerContext): TriggerResult = { //触发器完成计算 TriggerResult.FIRE_AND_PURGE } override def onProcessingTime( time: Long, window: TimeWindow, ctx: TriggerContext): TriggerResult = { throw new UnsupportedOperationException("I am not a processing time trigger") } //状态清除 override def clear(w: TimeWindow, triggerContext: TriggerContext): Unit = { triggerContext.getPartitionedState(stateDescriptor).clear() } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
Elasticsearch与Kibana
完成了上面的任务,接下来讨论如何将结果下沉到ES。我们需要定义一个ElasticsearchSink,它继承自RichSinkFunction。例子程序如下:
abstract class ElasticsearchUpsertSink[T](host: String, port: Int, cluster: String, index: String) extends RichSinkFunction[T] { //使用http协议的rest client,也有使用tcp的transport client,不过已经弃用了 private var client: RestHighLevelClient = _ def insertJson(record: T): Map[String, AnyRef] def updateJson(record: T): Map[String, AnyRef] def indexKey(record: T): String @throws[Exception] override def open(parameters: Configuration) { client = new RestHighLevelClient(RestClient .builder(new HttpHost("localhost", 9200))) } @throws[Exception] override def invoke(value: T, context: SinkFunction.Context): Unit = { //更新文档 //文档不存在就新增 val indexRequest = new IndexRequest(index) .id(indexKey(value)) .source(mapAsJavaMap(insertJson(value))) //存在文档就更新 val updateRequest = new UpdateRequest(index, indexKey(value)) .doc(mapAsJavaMap(updateJson(value))) .upsert(indexRequest) client.update(updateRequest, RequestOptions.DEFAULT).getResult } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
github上面也给出了es的操作指南,但是版本比较低,下面给出es7的操作。
首先启动es,创建索引:
curl -XPUT "http://localhost:9200/nyc-idx"
- 1
需要注意的是,ES7以上的版本已经去除了type,在提供的api里面,原来的type()方法也标注过时了,所以操作如下:
curl -XPUT "http://localhost:9200/nyc-idx/_mapping" -d'
{
"properties" : {
"cnt": {"type": "integer"},
"location": {"type": "geo_point"},
"time": {"type": "date"}
}
}'
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
在demo里开启es。这里要注意的就是ES的端口号。ES9200用于http协议,9300用于tcp协议以及ES集群内部的通讯。之前如果用的是TransportClient做es sink,那么端口应该使用9300。
// Elasticsearch parameters
val writeToElasticsearch = true // set to true to write results to Elasticsearch
val elasticsearchHost = "127.0.0.1" // look-up hostname in Elasticsearch log output
val elasticsearchPort = 9200
- 1
- 2
- 3
- 4
然后运行程序就能输出了。如果要清除数据的话,输入:
curl -XDELETE 'http://localhost:9200/nyc-idx'
- 1
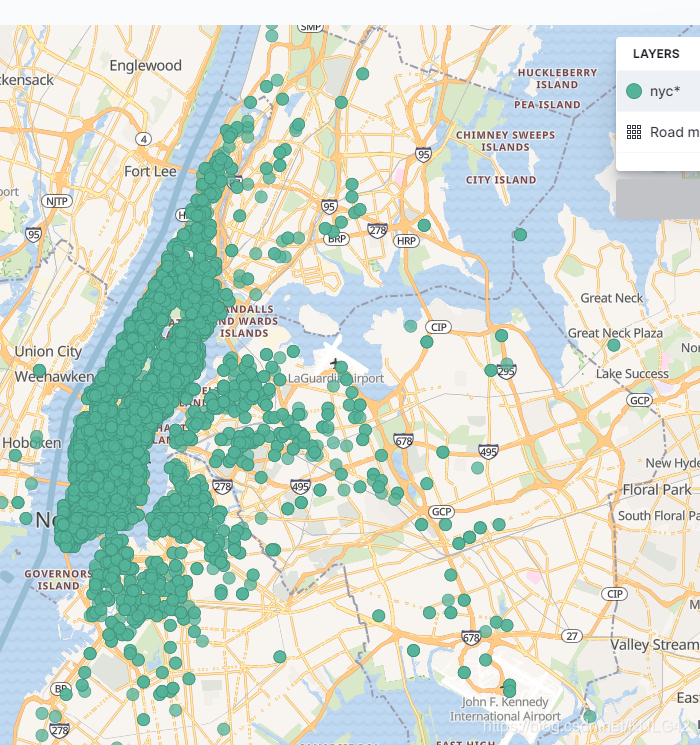
但是光光elasticsearch不太好看这个结果是怎么样的,这里就需要用到kibana。启动kibana,配置之前创建的索引,配置数据的时间范围选择2013-01-01到2013-01-06的绝对时间范围以找到数据。
结果应该会如下图所示:
flink1.12文档地址 https://ci.apache.org/projects/flink/flink-docs-release-1.12/zh/
flink1.12release note https://ci.apache.org/projects/flink/flink-docs-release-1.12/zh/release-notes/flink-1.12.html
elasticsearch https://www.elastic.co/cn/elastic-stack
kibana https://www.elastic.co/cn/kibana
原官方demo地址 https://github.com/dataArtisans/flink-streaming-demo






