
- 1Dubbo集群容错方案
- 2npm i 卡在reify:rxjs: timing reifyNode
- 3基于粤嵌gec6818开发板嵌入式电子相册,智能家居,音乐播放,灯光控制,2048游戏_粤嵌开发板相册
- 4python网站开发案例_基于Python-Flask实现的网站例子
- 5【附源码】Java计算机毕业设计校园订餐管理系统(程序+LW+部署)_学校食堂管理系统javaweb课程设计
- 6Ubuntu18.04安装docker和docker-compose_ubuntu18.04安装docker-compose
- 7【Microsoft Message Queuing远程代码执行漏洞(CVE-2023-21554)漏洞修复】
- 8[Python] 机器学习 - 常用数据集(Dataset)之糖尿病(diabetes)数据集介绍,数据可视化和使用案例
- 9Vue3的几款UI组件库:Naive UI、Element Plus、 Ant Design Vue、Arco Design_ant-design-vue3级联组件
- 10模板匹配 解决模板旋转以及重复检测问题_模板匹配如何针对旋转
leetcode---字符串匹配算法_字符串匹配 leetcode
赞
踩
简介
一 暴力匹配(Brute Force 算法),简称BF
假设主串长度为N,匹配串长度为M,该算法最坏的情况下需要进行 M*(N-M) 次比较,算法时间复杂度为O(M*N)。
二 RK(Robin-Karp,哈希检索):
RK算法是对BF算法的一个改进:在BF算法中,每一个字符都需要进行比较,并且当我们发现首字符匹配时仍然需要比较剩余的所有字符。而在RK算法中,就尝试只进行一次比较来判定两者是否相等。
RK算法也可以进行多模式匹配,在论文查重等实际应用中一般都是使用此算法。
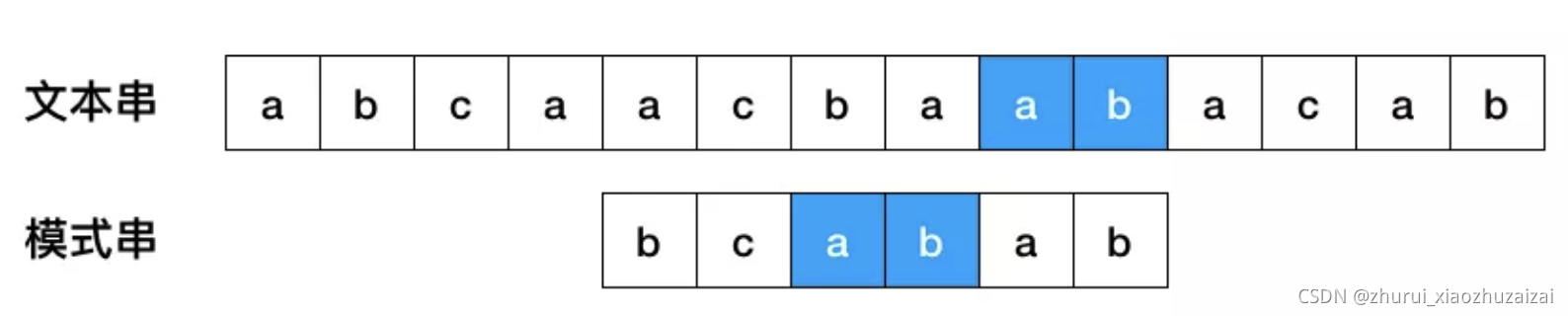
示例:”ABCDEFG", “DEF”
按照此例子,首先计算子串“DEF”HASH值为Hd,之后从原字符串中依次取长度为3的字符串“ABC”、“BCD”、“CDE”、“DEF”计算HASH值,分别为Ha、Hb、Hc、Hd,当Hd相等时,仍然要比较一次子串“DEF”和原字符串“DEF”是否一致。
时间复杂度:O(MN)(实际应用中往往较快,期望时间为O(M+N))
三 kmp算法(Knuth-Morris-Pratt 算法)
,简称KMP,由 Donald Knuth,James H. Morris,Vaughan Pratt 1977年联合发表。
text长度为n,模式为m, 时间复杂度就是O(n+m)。
预处理模式串的时间O(m), 匹配时间复杂度是O(n)

部分匹配值
KMP算法不是向BF算法那样向后移动一位,而是按照事先计算好的“部分匹配表”中记载的位数来移动,节省了大量时间
移动(已匹配字符串长度-部分匹配值)
"部分匹配"的实质是,有时候,字符串头部和尾部会有重复。利用字符串自身具有的重复性避免了指针的回退!!
"部分匹配值"就是"前缀"和"后缀"的最长的共有元素的长度。以"ABCDABC"为例


优化:next表
pl(文本字符串的长度)
sl(模式字符串的长度)
i(文本字符串的下标)
j(模式字符串的下标)
n(需要移动的位数)
当发生失配时,i不变,j=next[j], 意味着向右移动j - next [j] 位
next数组 就是为了简化公式而弄出来的。
next 数组各值的含义:代表当前字符之前的字符串中,有多大长度的相同前缀后缀。例如,如果 next [j] = k,代表 j 之前的字符串中有最大长度为 k 的相同前缀后缀。

方法1:根据部分匹配表得到next表
接下来将部分匹配表复制一行,去掉最后一个数,在开头添加一个-1,向右平移一个格,然后每个值在加1的到next值
方法2,根据上一个next值计算当前next值
第一位的next值为-1
第二位的next值为0,
后面求解每一位的next值时,根据前一位 进行比较。
首先将前一位与其next值对应的位进行比较,
如果相等,则该位的next值就是前一位的next值加上1;
如果不等,向前继续寻找next值对应的内容来与前一位进行比较,直到找到某个位上内容的next值对应的内容与前一位相等为止,则这个位对应的值加上1即为需求的next值;如果找到 第一位都没有找到与前一位相等的内容,那么需求的位上的next值即为1。

已知当前j = 17,
next[16] = 7, 可以推出 p[:7] = p[9:16]
next[7]=4, 可以推出 p[:4] = p[3:7]
则判断str[16]是否等于str[7],
如果相等,则+1
否则,判断str[16]是否等于str[4]
//KMP计算next数组 def nextTable(matchStr): if len(matchStr) == 0: return [] pl = len(matchStr) next_table = [-1] k = -1 j = 0 while j < pl - 1: //p[k]表示前缀,p[j]表示后缀 if k == -1 || matchStr[j]== matchStr[k]: k = k + 1 j = j + 1 next_table.append(k) else: k = next_table[k] return next_table //KMP,字符串匹配算法 => O(n+m) def matchSubStr(matchStr, str_in): if len(matchStr) == 0: return -1 next_table = self.nextTable(matchStr) i = 0 //文本串 j = 0 //模式串 pl = len(matchStr) sl = len(str_in) while i < pl && j < sl: if j == -1 || matchStr[i] == str_in[j]: i = i + 1 j = j + 1 else: j = next_table[j] if j == sl: return i-j else: return -1

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
nextVal数组
KMP算法中有next数组和nextval数组之分。 他们代表的意义和作用完全一样,完全可以混用。 唯一不同的是,next数组在一些情况下有些缺陷,而nextval是为了弥补这个缺陷而产生的。
当next和部分匹配表不相等时,将next的值填入
当next和部分匹配表相等时,填入对应序号为next值的nextVal值


nextval表的每一位反映该位失配后回退的地方
1.第一位的nextval值必定为0,
第二位如果于第一位相同则为0,如果不同则为1。
2.第三位的next值为1,那么将第三位和第一位进行比较,均为a,相同,则,第三位的nextval值为0。
3.第四位的next值为2,那么将第四位和第二位进行比较,不同,则第四位的nextval值为其next值,为2。
4.第五位的next值为2,那么将第五位和第二位进行比较,相同,第二位的next值为1,则继续将第二位与第一位进行比较,不同,则第五位的 nextval值为第二位的next值,为1。
5.第六位的next值为3,那么将第六位和第三位进行比较,不同,则第六位的nextval值为其next值,为3。
6.第七位的next值为1,那么将第七位和第一位进行比较,相同,则第七位的nextval值为0。
7.第八位的next值为2,那么将第八位和第二位进行比较,不同,则第八位的nextval值为其next值,为2。:
next和nextval比较
Next数组的缺陷举例如下:
比如主串是“aab……” 省略号代表后面还有字符。
模式串“aac”
通过计算aac的next数组为012(另外,任何字符串的第二位字符的next总是1,因此你可以认为他固定为1)
当模式串在字符c上失配时,会跳到第2个字符,然后再和主串当前失配的字符重新比较,即此处用模式串的第二个a和主串的b比较
即 aab aac
显然a也不等于b。然后 会跳到1,接着比,然后又失配,直到最后才使主串后移一位。
而“aac”的nextval数组为002 当在c失配时会跳到2,若还失配就直接跳到0,比next数组少比较了1次。
在如果模式串很长的话,那可以省去很多比较,因此你应该使用nextval数组。
BM算法
KMP 的匹配是从模式串的开头开始匹配的,而 1977 年,德克萨斯大学的 Robert S. Boyer 教授和 J Strother Moore 教授发明了一种新的字符串匹配算法:Boyer-Moore 算法,简称 BM 算法。该算法从模式串的尾部开始匹配,且拥有在最坏情况下 O(N) 的时间复杂度。在实践中,比 KMP 算法的实际效能高。
不是简单的++j,而是j+=max (shift(好后缀), shift(坏字符))

缺点
BM算法与KMP思想类似,但是更好了利用了预处理数组,使得更有效率,但是模式串的预处理数组也变得相对更加复杂,所以当面临较小场景时,并不一定适合选用BM算法。
优点
时间复杂度
KMP O(m+n)
BM O(m/n) - O(m*n)
坏字符规则
当文本串中的某个字符跟模式串的某个字符不匹配时,我们称文本串中的这个失配字符为坏字符,此时模式串需要向右移动,
坏字符没出现在模式串中,这时可以把模式串移动到坏字符的下一个字符

坏字符出现在模式串中,这时可以把模式串中第一个出现(从后往前数第一个出现,也就是从前往后数,最靠右出现的)的坏字符和原串的坏字符对齐;

后移位数 = 坏字符的位置 - 模式串中的上一次出现位置
# bmBc[k]表示坏字符k在模式串中出现的位置 距离模式串末尾的最大长度。
def preBmBc(pattern) {
bmBc = [len(pattern) for i in range(256)]
i = 0
for i in range(len(pattern)):
bmBc[ord(x[i])] = len(pattern) - i - 1
return bmBc
#向后移动:当前位置 - bmbc位置
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
好后缀规则
模式串中有子串匹配上好后缀,此时移动模式串,让子串和好后缀对齐即可,如果超过一个子串匹配上好后缀,则选择最靠左边的子串对齐;
模式串中没有子串匹配上后缀,接着寻找模式串中的一个和好后缀(子串)相等的最长前缀,并让该前缀和好后缀对齐即可;
模式串中没有子串匹配上好后缀,并且在模式串中找不到和好后缀(子串)相等的最长前缀,此时,直接移动模式到好后缀的下一个字符;
好后缀的规则:
后移位数 = 好后缀的位置 - 模式串中的上一次出现的位置
# bmGs[i] 表示遇到好后缀时,模式串应该移动的距离,i表示好后缀前面一个字符的位置 # bmGs数组分三种情况: # 1. 模式串有子串匹配上好后缀 # 2. 模式串没有子串匹配上好后缀,但找到一个最大前缀 # 3. 模式串中没有匹配上好后缀,同时也没有最大前缀和好后缀匹配 def preBmGs(pattern) { pLen = len(pattern) # suffix数组表示以i为边界,与模式串后缀匹配的最大长度 suff = suffix(pattern) # 没有匹配上子串没有好后缀,移动pLen bmGs = [pLen for i in range(pLen)] j = 0; for i in range(pLen-1, -1, -1): # suff[i] == i+1时,说明s=i-1, P[i-s, i] == P[m-s, m] if suff[i] == i+1: #前缀长度i+1,后缀的长度肯定大于 i+1 while j < pLen-1-i: if (bmGs[j] == pLen) bmGs[j] = pLen-1-i j += 1 for i in range(pLen-1): # 计算出现好后缀的位置,index # 此时应该往后移动的长度:pLen-1-i index = pLen-1-suff[i] bmGs[index] = pLen-1-i # suffix数组表示以i为边界,与模式串后缀匹配的最大长度, # 用公式描述:满足P[i-s, i] == P[m-s, m] # 如果i不等于m,suffixs[i] 肯定是0,第一个字母都不等。 def suffixs(pattern): pLen = len(pattern) suff = [0 for i in range(pLen)] suff[-1] = pLen #模式串末尾的前缀是整个模式串 for i in range(pLen-2, -1, -1): s = 0; #代表匹配的后缀的长度 #这里之所以 +q是用了q在逐渐减小1, 用另外的变量减一也可以。 while i-s >= 0 and pattern[i-s] == pattern[pLen-1-s]: s += 1 suff[i] = s; return suff
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
代码
例如:遇到如下情况,I不匹配
根据坏字符规则,移动2位到I的下一位置
根据好后缀规则,好后缀MPLE,PLE, LE, E与前缀E.移动4位到E的位置



void BM(const char *x, int m, const char *y, int n) { tLen = len(target) #主串的长度 pLen = len(pattern) #模式串的长度 #如果模式串比主串长,没有可比性,直接返回-1 if pLen > tLen: return -1 # 获得坏字符数值的数组 # bmBc[k]表示坏字符k在模式串中出现的位置 距离模式串末尾的最大长度。 bmBc = preBmBc(pattern) # 获得好后缀数值的数组 # bmGs[i]表示遇到好后缀时,模式串应该移动的距离,i表示好后缀前面一个字符的位置 bmGs = preBmGs(pattern) # idt为字符串的位置 # idp为模式串的位置 idt = 0; while (idt <= tLen - pLen) { idp = pLen -1 while idp >= 0 and target[idp + idt] == pattern[idp]: idp -= 1 if idp < 0: print("匹配成功,位置:" + idt); return idt; ## 如果需要匹配多个模式串,break后即可 ## 这里用了如果p[0]不等时的最大好后缀移动长度。加一也可以。 ## idt += bmGs[0]; ## break; else: # 好后缀的下一位置 good_suffix = bmGs[i]; # 坏字符的下一位置,target[i+idt]为当前不匹配的字符 bad_char = idt + bmBc[target[i+idt]] - pLen + 1; idj += MAX(good_suffix, bad_char);
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
Sunday算法
Sunday算法是从前往后扫描模式串的,其思路更像是对于“坏字符”策略的升华。关注的是主串中参与匹配的最末字符(并非正在匹配的)的下一位,稍后看图更容易理解
Case1:当遇到不匹配的字符时,如果关注的字符没有在模式串中出现则直接跳过
即移动位数 = 子串长度 + 1;

Case2: 当遇到不匹配的字符时,如果关注的字符在模式串中也存在时,其
移动位数 = 模式串长度 - 该字符最右出现的位置(以0开始)
或者移动位数 = 模式串中该字符最右出现的位置到尾部的距离 + 1

缺点
如果是下面这个情况,会怎么样?
主串:baaaabaaaabaaaabaaaa
子串:aaaaa
没错,这个时候,效率瞬间变成了O(m*n)
Sunday算法的移动是取决于子串的,这一点跟BM算法没什么区别,当这个子串重复很多的时候,就会非常糟糕了。大家知道这一点,有所取舍就好
优点
时间复杂度
KMP O(m+n)
BM O(m/n) - O(mn)
Sunday O(m/n) - O(mn)
实际使用中 Sunday算法比BM算法略优
def sunday_search(target, pattern): tLen = len(target) #主串的长度 pLen = len(pattern) #模式串的长度 #如果模式串比主串长,没有可比性,直接返回-1 if pLen > tLen: return -1 offset = {} for i in range(pLen): offset[pattern[i]] = pLen - i idt = 0 idp = 0 while (idt <= tLen - pLen) { idp = 0 while target[idt+idp] == pattern[idp]: idp += 1 if idp == pLen: return idt if idt + pLen == tLen: return -1 if target[idt + pLen] in offset: idt += offset[target[idt + pLen]] else: idt += pLen + 1 return -1
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
参考:
https://blog.csdn.net/FX677588/article/details/53406327
https://blog.csdn.net/huashaoyoumanre/article/details/87968983
https://wiki.jikexueyuan.com/project/kmp-algorithm/bm.html
https://blog.csdn.net/DBC_121/article/details/105569440
https://blog.csdn.net/sunnianzhong/article/details/8820123


