- 1深入浅出Java虚拟机_深入浅出:java虚拟机设计与实现
- 2【ssmp】springboot综合开发——图书管理系统【CRUD】_黑马程序员sql图书管理系统
- 3数学建模算法集合_数学建模中的集合
- 4使用git合并两次commit_gerrit合并两次commit
- 5Dockerfile(11) - COPY 指令详解
- 6归并排序_public class mergesort { // 将arr[l...mid]和arr[mid+
- 7mongodb java分页查询_JAVA代码实现MongoDB动态条件之分页查询
- 8STM32 使用SPI读写FLASH(W25Q64型号)_stm32读写w25q64代码库函数
- 9at32f403 rtthread adc_at32f403a adc数据错误
- 10【SpringSecurity系列4】基于Spring Webflux集成SpringSecurity实现前后端分离无状态Rest API的权限控制原理分析_reactivesecuritycontextholder
多任务模型PLE:Progressive Layered Extraction_progressive layered extraction (ple): a novel mult
赞
踩
Progressive Layered Extraction (PLE): A Novel Multi-Task Learning (MTL) Model for Personalized Recommendations
论文地址:https://dl.acm.org/doi/abs/10.1145/3383313.3412236
要解决的问题
多任务学习中常见的2个问题
- 负向迁移问题
多任务学习由同一个底层输入来学习不同的任务,数据量少的任务可以通过transfor learning补充学习增益,可以借助底层共享的Embedding层或者上层的共享结构来实现。但是现实中多个任务彼此之间的相关性很弱或很复杂时,这种参数共享的transfor learning反而有害,使得多个任务的性能出现下降。 - 跷跷板效应
多个任务同时优化时,经常出现一个任务效果较好,而另外一个任务的效果下降,换言之,效果好的任务可能是以损害另外一个任务的效果而得到的。
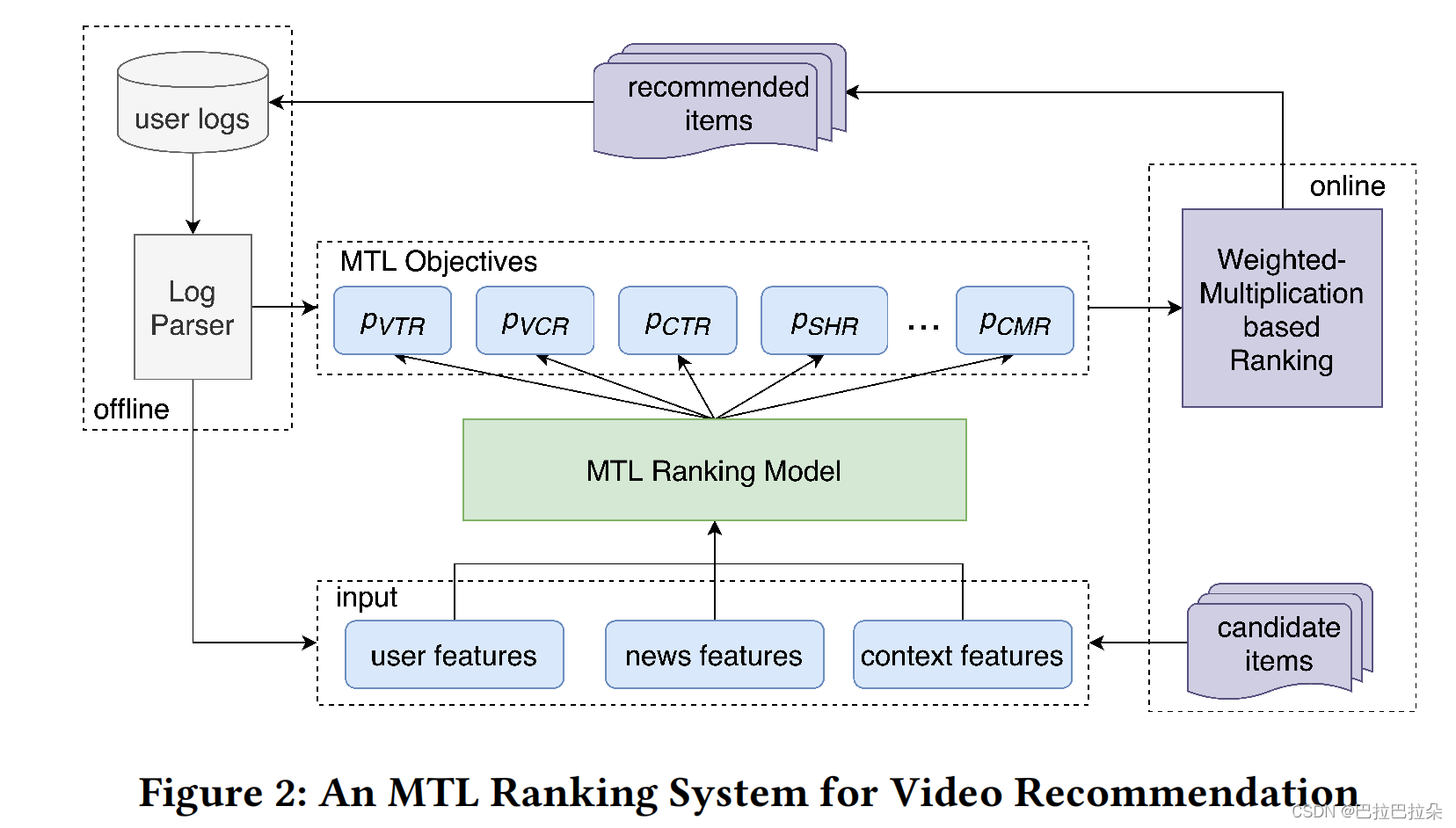
跷跷板效应论文中给出了详细的实例演示。论文的场景是腾讯新闻中的视频推荐(如下图),需要预估的多个目标包括VTR(视频点击率,定义为超过一定时间阈值的播放行为,二分类问题),VCR(视频完成度,定义为视频完成播放的比例,回归问题),SHR(新闻分享率),CMR(新闻评论率)等等。论文重点关注的是VTR和VCR,这两个任务的相关性比较复杂,容易出现跷跷板效应。
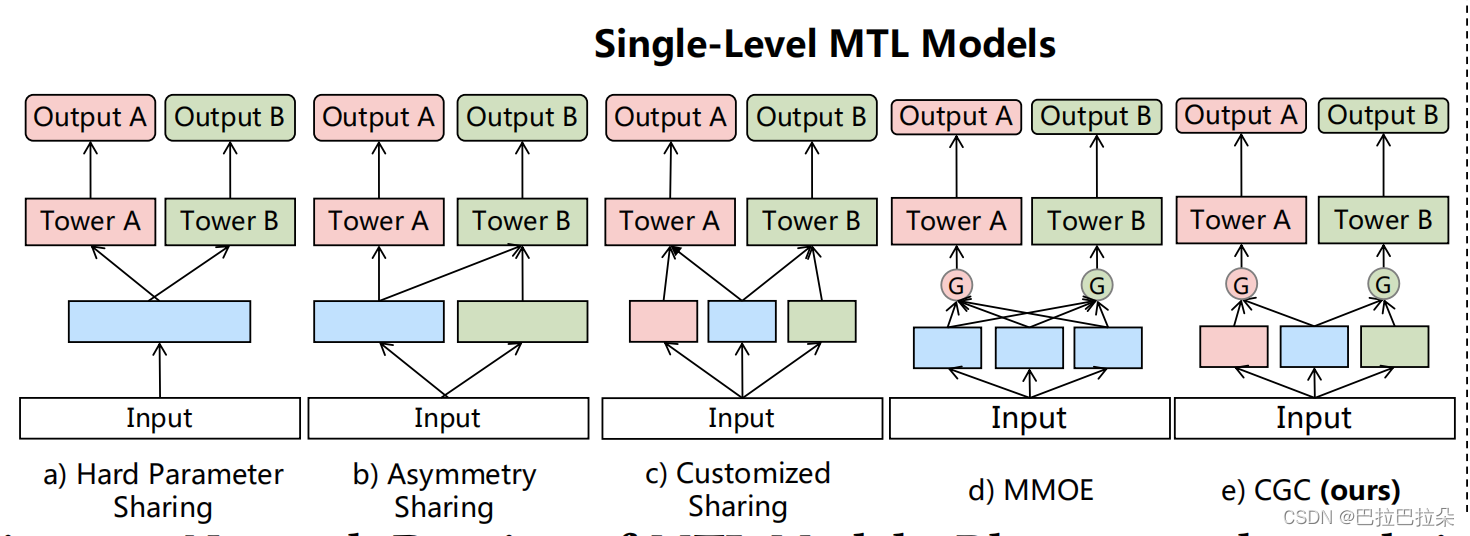
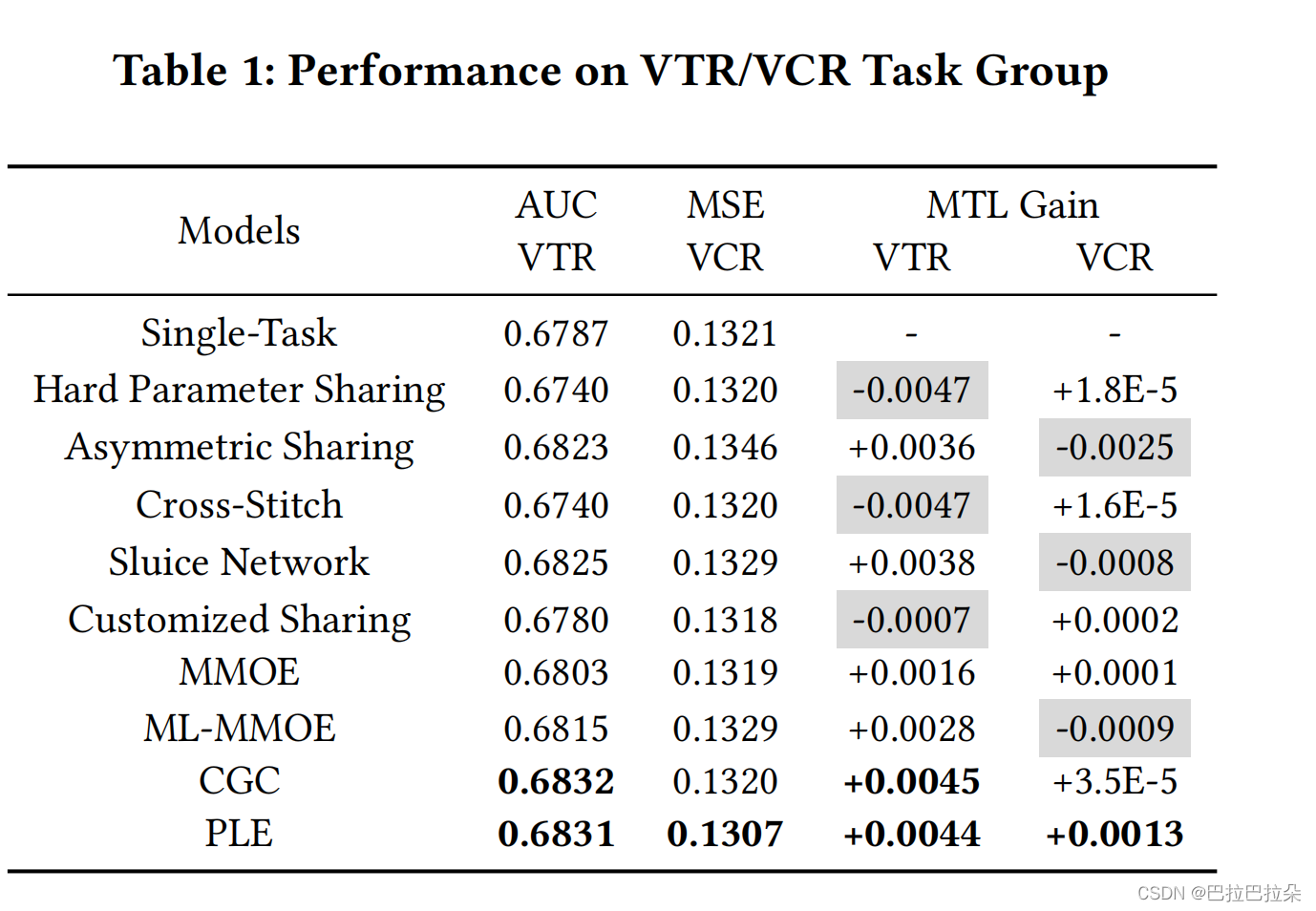
论文对比了几种多任务学习参数共享的方法在VCR和VTR上面的效果,首先对参数共享的方式进行了归类,分为hard parameter sharing、asymmetry parameter sharing、customized parameter sharing、MMoE、CGC(论文提出的共享结构)
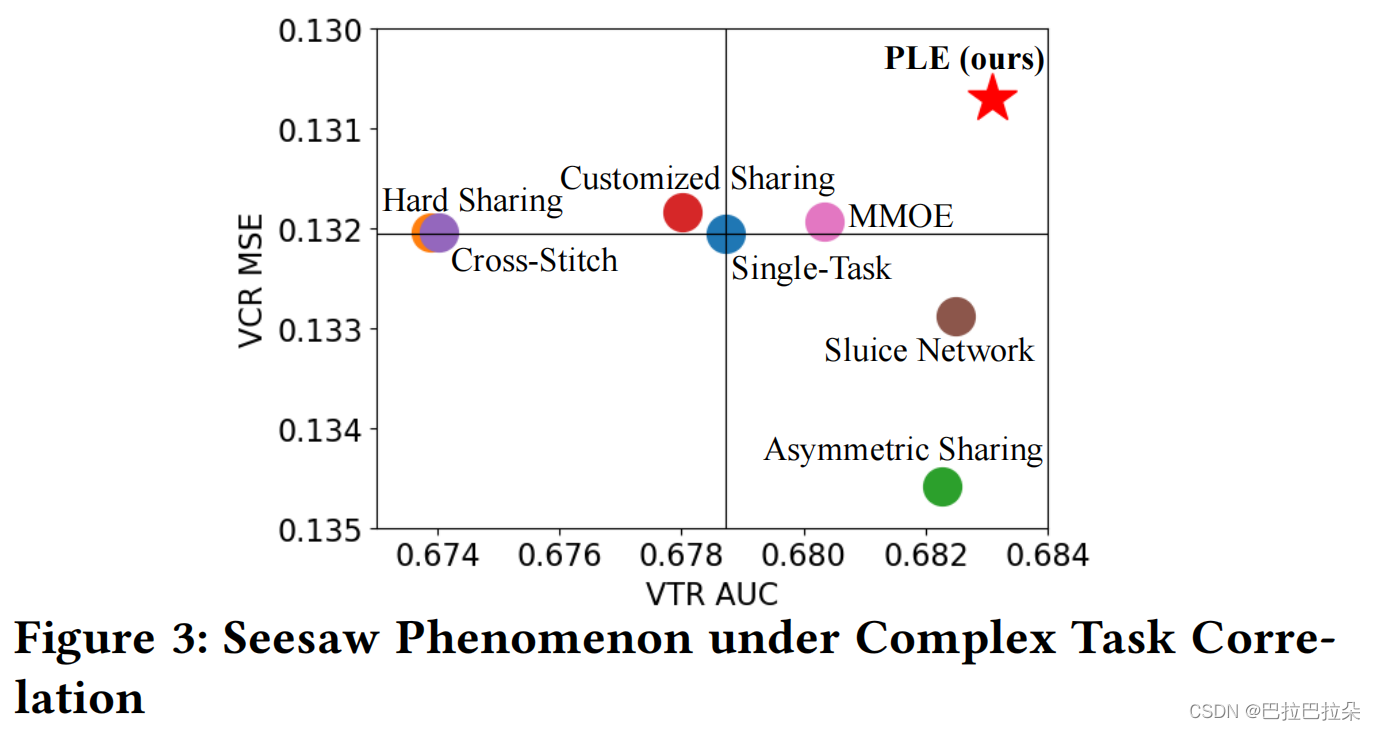
然后对应的模型进行评测,按照VTR的auc和VCR的mse结果进行展示。如下图,可以看到横轴是VTR auc,纵轴是VCR的mse,中间的原点表示VTR和VCR单个任务优化的指标。除了MMoE和PLE外,其他的model要么在VCR上面表现好,但是VTR表现差,要么在VTR上面表现好但是在VCR上面表现差,MMoE在VTR和VCR上面都不错,但是相对于单任务来讲,对于每个单任务的提升都不多,只有PLE在2个任务上面表现出色,相对单个任务提升都较多,这个图展示跷跷板非常明显。
PLE怎么做的
CGC
为了解决负向迁移问题和跷跷板效应,论文提出了CGC(Customized Gate Control)。如下图
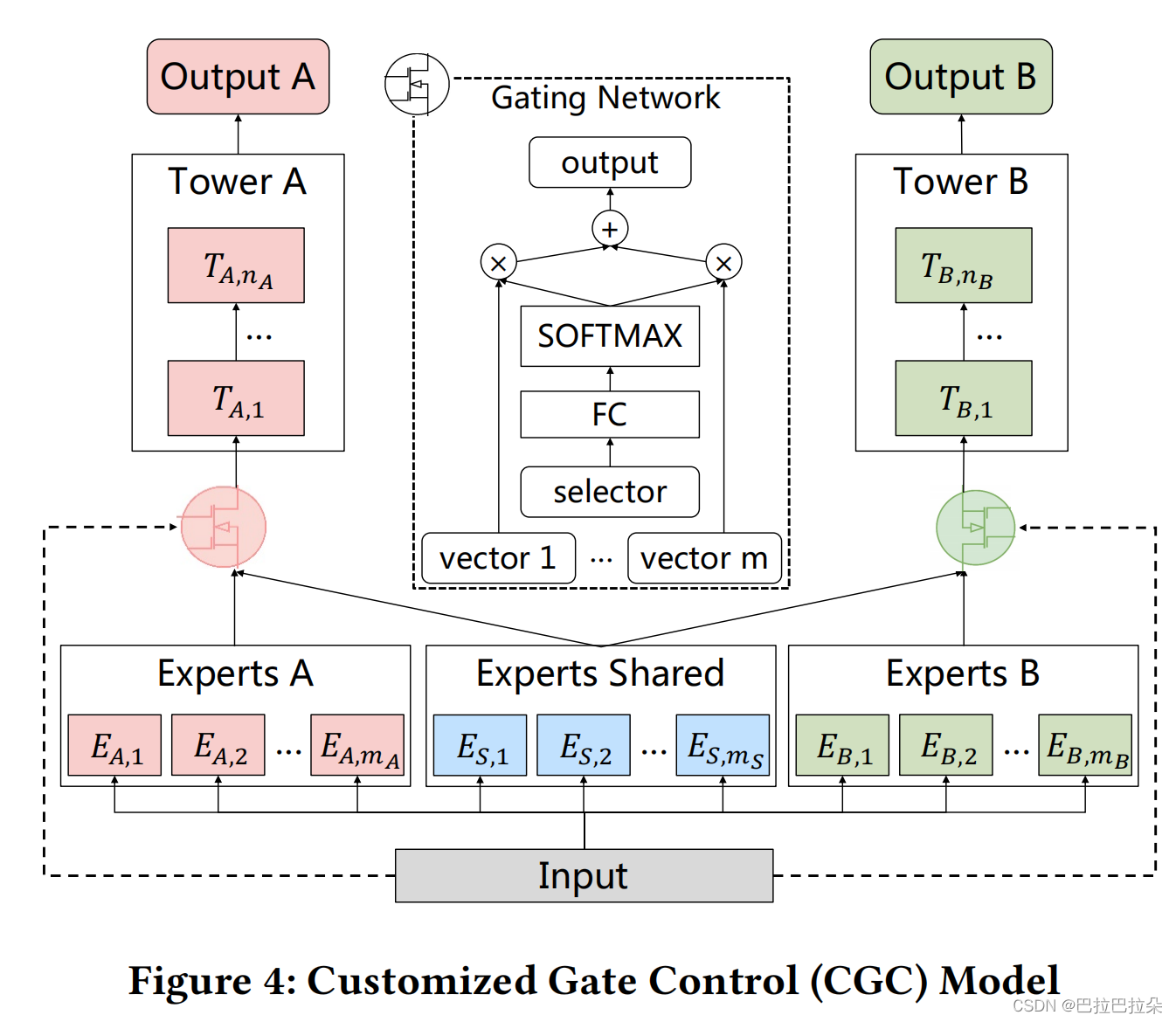
相较于MMoE(所有任务用到的expert没有区别),CGC将expert分成了2种,一种是特定任务相关的,一种是所有任务共享的。这种设计避免了expert之间参数共享的相互干扰,每个任务都有自己的expert组,可以集中精力学习本任务独特的一些信息,同时每个任务自己的gate网络也能从共享的expert组中汲取信息,获得更多的信息增益。
举例说明,对于任务
k
k
k,其gate网络的输出为
g
k
(
x
)
=
w
k
(
x
)
S
k
(
x
)
g^k(x) = w^k(x)S^k(x)
gk(x)=wk(x)Sk(x)
x
x
x表示输入向量,
w
k
(
x
)
w^k(x)
wk(x)表示向量的权重,由softmax层计算得到
w
k
(
x
)
=
S
o
f
t
m
a
x
(
W
g
k
x
)
w^k(x)=Softmax(W^k_gx)
wk(x)=Softmax(Wgkx)
其中
W
g
k
∈
R
(
m
k
+
m
s
)
×
d
W^k_g \in R^{(m_k+m_s) \times d}
Wgk∈R(mk+ms)×d即softmax的全连接矩阵参数,
m
k
m_k
mk和
m
s
m_s
ms分别表示任务
k
k
k的expert的个数和共享expert的个数,
d
d
d表示向量维度。
S
k
(
x
)
S^k(x)
Sk(x)是选定的向量组,包括任务
k
k
k的expert组和共享任务的expert组,表示如下
S
k
(
x
)
=
[
E
(
k
,
1
)
T
,
E
(
k
,
2
)
T
,
.
.
.
,
E
(
k
,
m
k
)
T
,
E
(
s
,
1
)
T
,
E
(
s
,
2
)
T
,
.
.
.
,
E
(
s
,
m
s
)
T
]
T
S^k(x)= [E^T_{(k,1)},E^T_{(k,2)},...,E^T_{(k, \mathbf m_k)},E^T_{(s,1)},E^T_{(s,2)},...,E^T_{(s,\mathbf m_s)}]^T
Sk(x)=[E(k,1)T,E(k,2)T,...,E(k,mk)T,E(s,1)T,E(s,2)T,...,E(s,ms)T]T
和MMoE相比,实际上是去掉了其他任务的expert组和本任务的tower网络的连接。
PLE
CGC只有一层,为了抽取更加深层次的信息,对CGC进行扩展,将CGC当做一个层,往上面叠加,增加参数量,扩大模型容量,进一步抽取信息。不过如果是多层的话,和CGC有点小区别,除了最上层和CGC一样,底下的层的共享expert组都多一个gate网络,用于将本层的所有expert的信息聚合起来,提供给到下一层使用。如下图
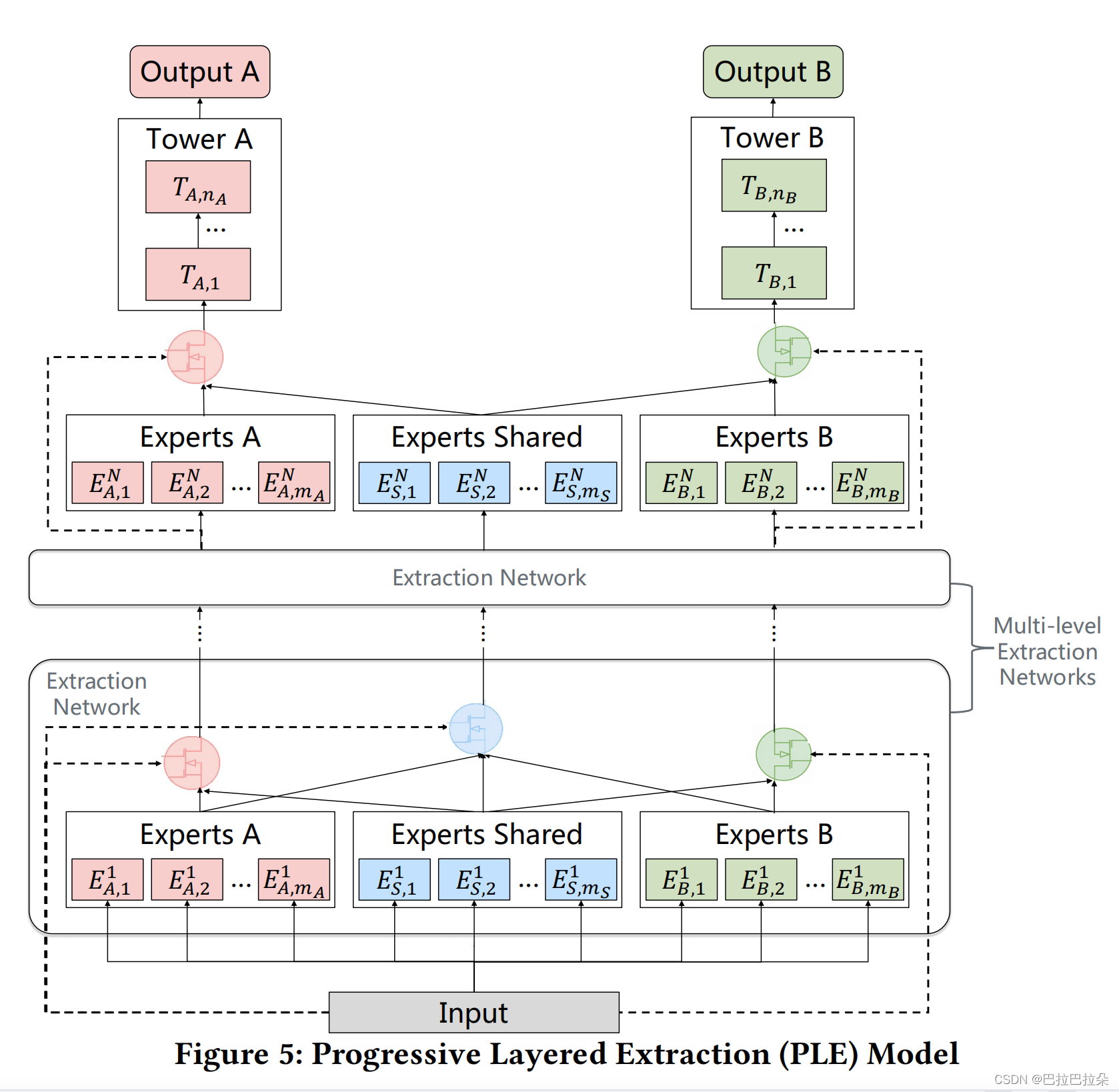
还是以任务
k
k
k为例,任务
k
k
k在PLE的第
j
j
j层的gate网络输出为
g
k
,
j
(
x
)
=
w
k
,
j
(
g
k
,
j
−
1
(
x
)
)
S
k
,
j
(
x
)
g^{k,j}(x)=w^{k,j}(g^{k,j-1}(x)) S^{k,j}(x)
gk,j(x)=wk,j(gk,j−1(x))Sk,j(x)
w
k
,
j
w^{k,j}
wk,j表示任务
k
k
k各个选定的向量组的权重,
g
k
,
j
−
1
g^{k,j-1}
gk,j−1表示上一层任务
k
k
k的gate网络输出。
最终,经过任务
k
k
k的tower网络
t
k
t^k
tk转换后,任务
k
k
k的输出为
y
k
(
x
)
=
t
k
(
g
k
,
N
(
x
)
)
y^k(x) = t^k(g^{k,N}(x))
yk(x)=tk(gk,N(x))
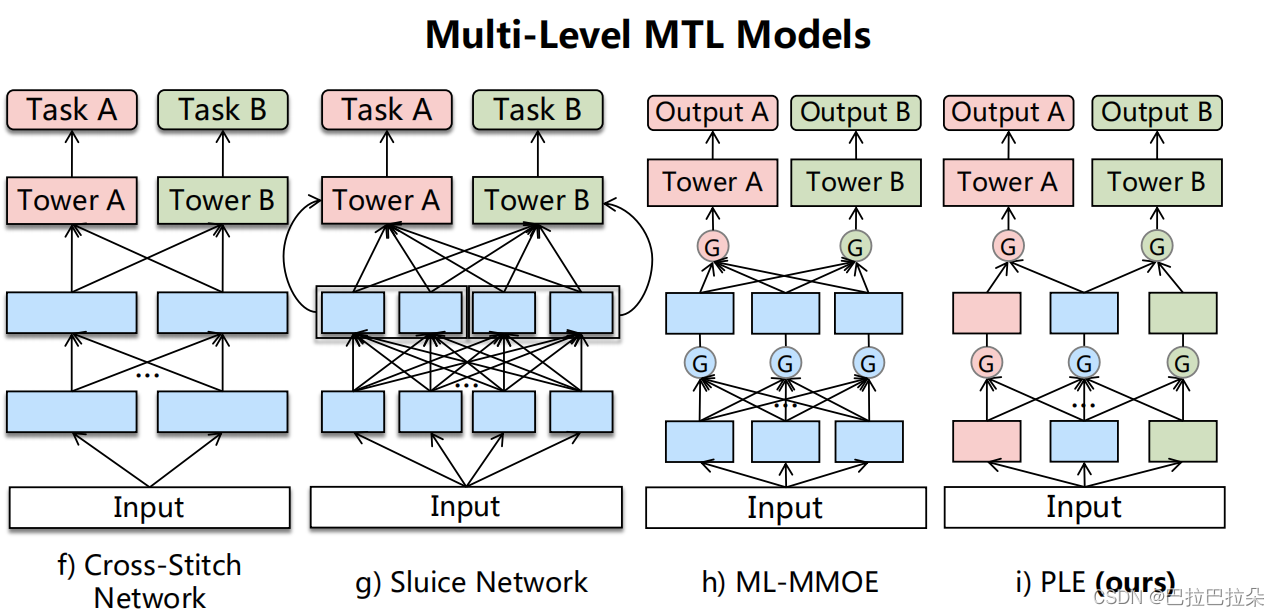
对比其他的多层多任务模型,如下图,PLE还是将expert分为了2种,一种特定任务相关,一种是大家共享。
loss层面优化
出了模型结构的优化,论文还提出了多任务的loss优化。一般多任务模型的loss函数由多个任务的loss进行加权求和,如下,假设有
K
K
K个任务
L
(
θ
1
,
θ
2
,
.
.
.
θ
K
,
θ
s
)
=
∑
k
=
1
K
w
k
L
k
(
θ
k
,
θ
s
)
L(\theta_1,\theta_2,...\theta_K,\theta_s) = \sum_{k=1}^K w_k L_k(\theta_k,\theta_s)
L(θ1,θ2,...θK,θs)=k=1∑KwkLk(θk,θs)
存在2个问题
问题1:不同任务的样本空间不同,比如用户点击之后才能评论和分享,论文的优化措施是计算特定任务的loss时,忽略这个本任务样本空间以外的loss,只计算本任务样本空间的损失。
不同任务训练空间的关系图
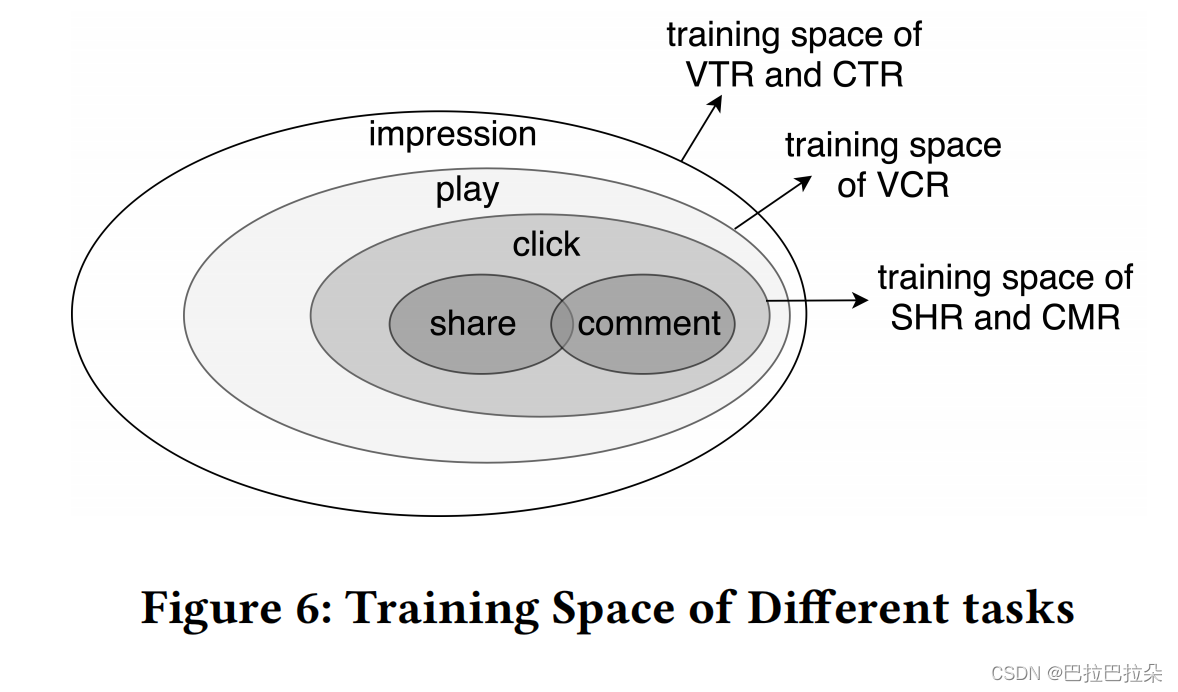
如下式,如果样本
i
i
i在任务
k
k
k的样本空间,才计算loss,否则不计算,
δ
k
i
∈
{
0
,
1
}
\delta_k^i \in \{0,1\}
δki∈{0,1}
l
k
(
θ
k
,
θ
s
)
=
1
∑
i
δ
k
i
∑
i
δ
k
i
l
o
s
s
k
(
y
^
k
i
(
θ
k
,
θ
s
)
,
y
k
i
)
l_k(\theta_k,\theta_s) = \frac {1} {\sum_i \delta_k^i} \sum_i \delta_k^i loss_k(\hat y^i_k(\theta_k,\theta_s), y^i_k)
lk(θk,θs)=∑iδki1i∑δkilossk(y^ki(θk,θs),yki)
问题2:多任务模型对于权重选择比较敏感,同时不同训练阶段各个任务的重要些也不同,相对于设置一个固定的任务权重,论文提出了对于任务设置一个动态的任务权重,可以根据不同的训练阶段来自动调整。
w
k
t
=
w
k
,
0
×
γ
k
t
w^{t}_k= w_{k,0} \times \gamma^t_k
wkt=wk,0×γkt
t
t
t表示训练epoch,
w
k
t
w^{t}_k
wkt和
γ
k
t
\gamma^t_k
γkt都是超参数
实验部分
定义多任务增益
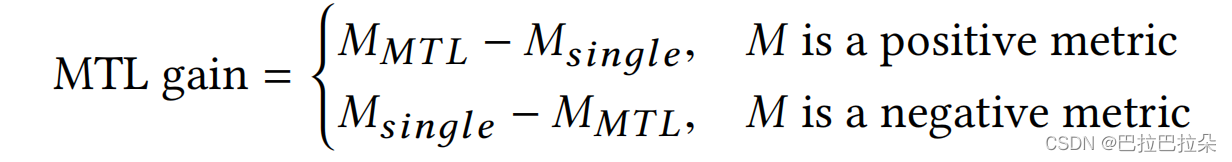
效果
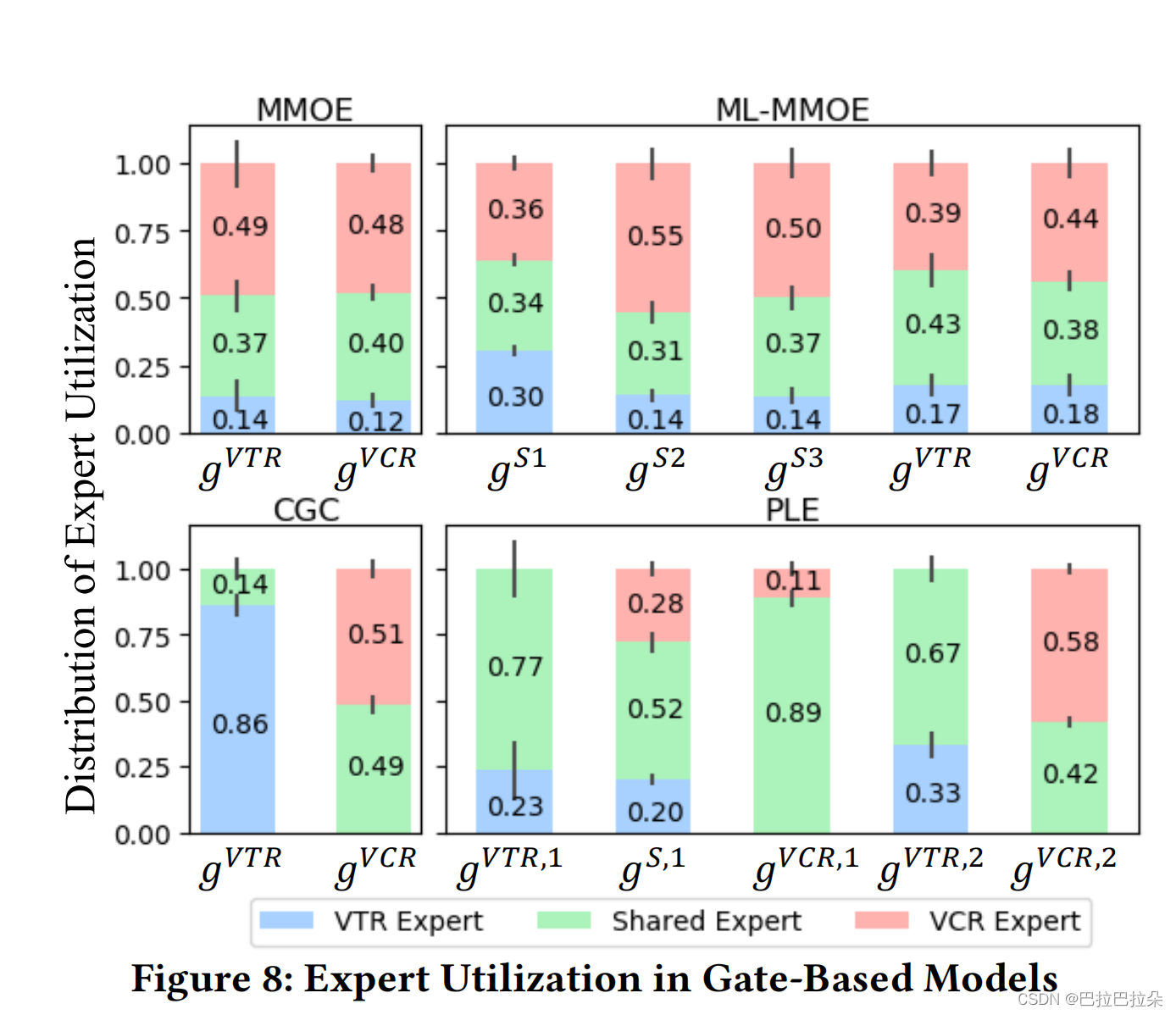
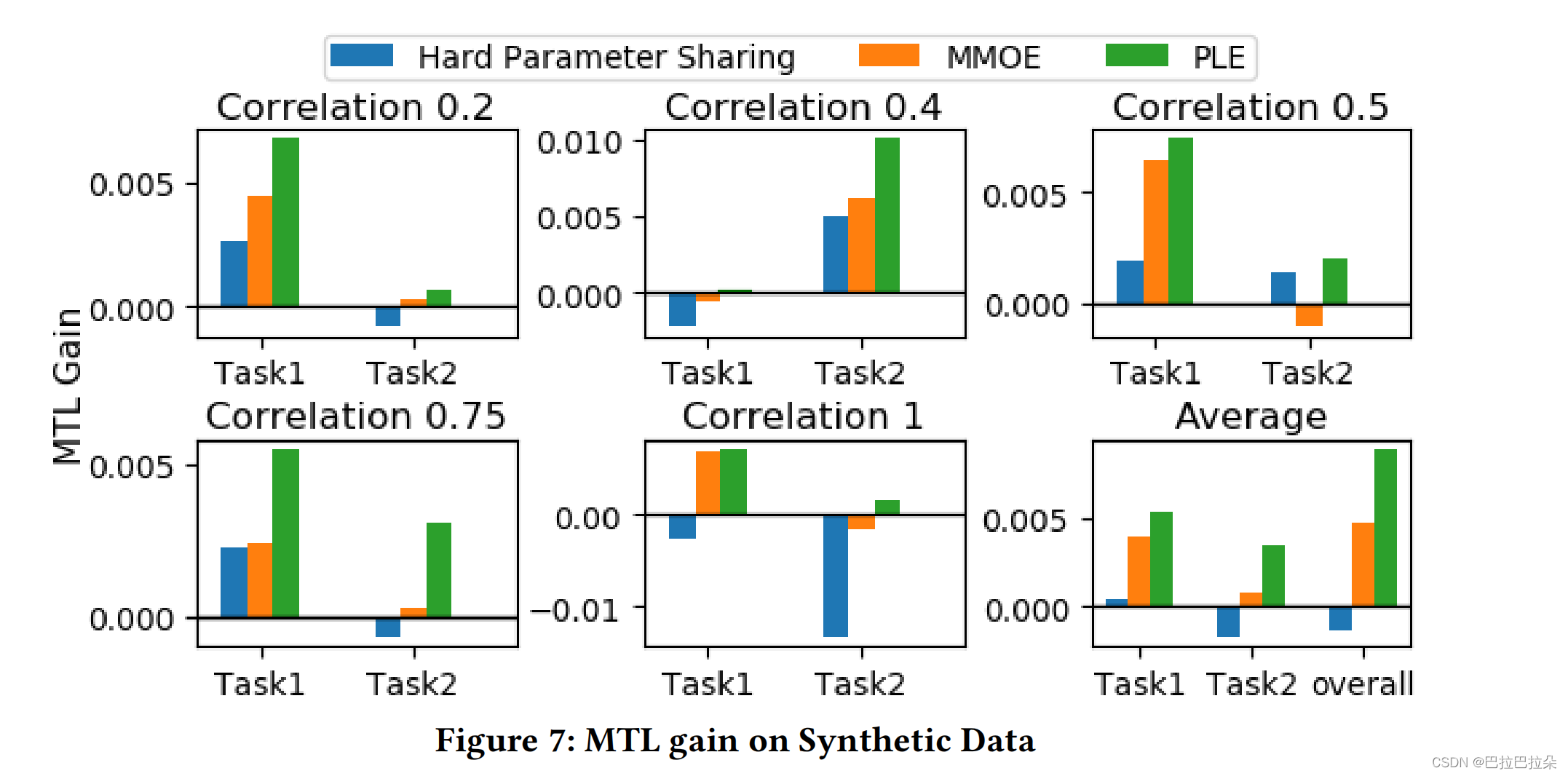
对比不同任务相关性的表现
对比MMoE和PLE的expert权重分布,MMoE的expert权重区别不大,PLE不同任务的exper权重区别较大