
- 1一文带你读懂深度估计算法
- 2windows 系统安装mysql8.0 及错误问题处理_windowsmysql8配置器错误
- 3mediasoup基础概览_mediasoup ndi
- 4数据结构-Treap(树堆) 详解
- 57 Series FPGAs Integrated Block for PCI Express IP核 Advanced模式配置详解(一)_pcie integrated block for pci express
- 6大模型的 5 月:热闹的 30 天和鸿沟边缘
- 7JDBC之MySQL的URL_mysqljdbc的url怎么写
- 8uni-app 配置编译环境与动态修改manifest,2024非科班生的Android面试之路_manifest 动态编译
- 9struct和class区别、三种继承及虚继承、友元类_class继承struct
- 10图片和16进制 互相转换_图片转16进制
Gated Neural Networks for Targeted Sentiment Analysis_gated recurrent neural networks
赞
踩
前提
- 文中的各个框架图、示意图都没有画出 target 信息与 context 交互的部分,这可能会产生一些误导,其实 target 信息是参与了门的控制的,即其是直接参与到了情感分类的。
Motivation
-
因为对目标和属性之间的联系建模对于目标情感分析是很重要的,但是之前的做法无论是否通过人工来得到特征,都人为依赖了一些语法、语义信息。
-
之后随着直接通过神经网络训练 word embedding 的方法的出现,得到的 word embedding 带来了更多的更可靠的包含了语义的信息。并且作者注意到了 Vo and Zhang (2015)[1] 利用这种 word embedding 的方式,这种方法的示意图如下:
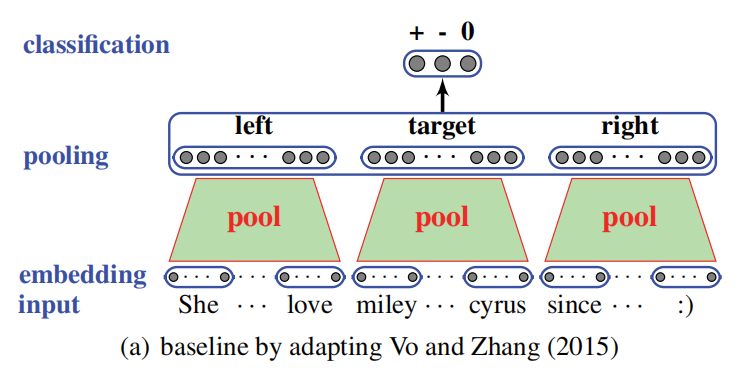
如图所示,这种方法首先用 embedding vector 表示句中每个词,之后将整句话分为 tareget 左边的 context、target、target 右边的 context 三部分。之后将每部分都做一个 pooling 的操作得到各自的向量表示。最后将这三部分的 vector 拼接起来作为整句话的表示,以此得到最后的分类结果。
-
但上面这种方法的准确率不高,因为没有完全捕获推文和给定目标实体的语义信息,具体是因为其两点限制:
- 池函数虽然可以从单词序列中选择最有用的特征,但不捕获底层的句法和语义信息。
- 目标与其上下文之间的交互仅在池函数和线性分类器上隐式建模,而不是显式建模。即在 pool 层里类似黑箱操作,少了些针对性。
方法概述
作者提出了用门控神经网络结构来对 tweet 语句建模,以及实现上下文和目标之间的交互,来解决上述两个限制,模型的框架图如下:
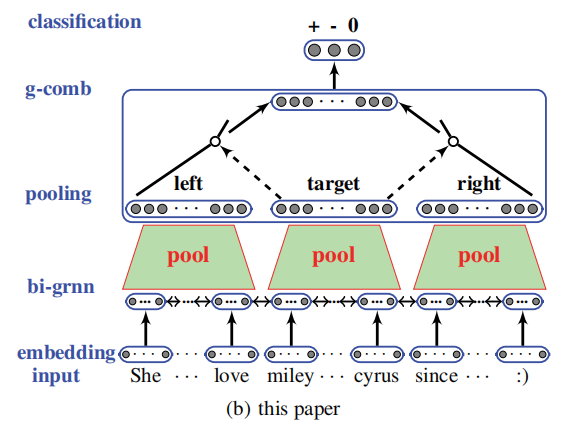
如图所示,模型分为几个部分:
- 先用 GRNN(Gated Recurrent Neural Network)来对整句话建模。
- 从 GRNN 中得到的结果根据位置分为三部分(target 左、target、target 右),并分别将其放入一个 pool 中,得到各部分的最终表示。
- 利用门控机制来完成 left context 和 right context 的交互(target 参与控制左右 context 的交互)。
(因为 target 本身对 context 的建模或者特征提取是有影响的,所以作者加入了 target 信息来帮助控制上面神经网络中的 gates)
方法详述
Modeling Tweet-Level Syntactic and Semantic Information Using Bi-Directional GRNN
这部分没什么需要说明的,下面只说一说作者在这部分定义的符号的含义。
words x = [ x 1 , x 2 , ⋯ , x n ] \mathbf{x} = [x_1,x_2,\cdots,x_n] x=[x1,x2,⋯,xn] 经过 BiGRNN 分别得到正向和负向的隐状态 h i h_i hi 和 h i ′ h_i^{'} hi′,将二者的拼接 h i ⊕ h i ′ h_i⊕h_i^{'} hi⊕hi′ 作为第 i i i 个 word x i x_i xi 对应的隐状态。
Modeling the left context, the target entity and the right context respectively
通过 BiGRNN 得到的 words 的隐状态后,分别对 target 左边的 context、target 和 target 右边的 context 进行 pooling 操作,分别得到这三部分的表示
h
l
h_l
hl、
h
r
h_r
hr 和
h
t
h_t
ht。这部分对应的公式为:
h
l
=
t
a
n
h
(
p
o
o
l
i
n
g
(
l
e
f
t
_
c
o
n
t
e
x
t
)
⋅
W
7
+
b
7
)
h
t
=
t
a
n
h
(
p
o
o
l
i
n
g
(
t
a
r
g
e
t
)
⋅
W
8
+
b
8
)
h
r
=
t
a
n
h
(
p
o
o
l
i
n
g
(
r
i
g
h
t
_
c
o
n
t
e
x
t
)
⋅
W
9
+
b
9
)
(1)
h_l = tanh(pooling(left\_context) · W_7 + b_7) \\ h_t = tanh(pooling(target) · W_8 + b_8) \\ h_r = tanh(pooling(right\_context) · W_9 + b_9) \tag{1}
hl=tanh(pooling(left_context)⋅W7+b7)ht=tanh(pooling(target)⋅W8+b8)hr=tanh(pooling(right_context)⋅W9+b9)(1)
Modeling the Interaction between the Target and the Surrounding Context
接下来要利用门控机制来让左右 context 进行交互,以得到最后有利于情感分类的最终表示。(注意:尽管这里说的是让左右 context 进行交互,但是 target 信息也是会参与门的控制的,所以最终的表示也是包含着 target 信息的)。下面是该部分的示意图:
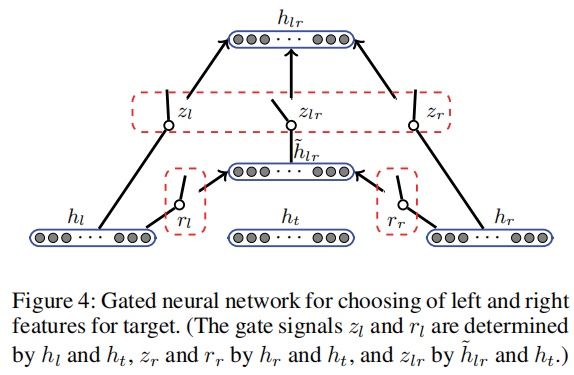
从图中可以看出,该部分是先融合 h l h_l hl 和 h r h_r hr 得到 h ~ l r \tilde{h}_{lr} h~lr,接着融合 h l h_l hl、 h r h_r hr、 h ~ l r \tilde{h}_{lr} h~lr 得到整个句子的最终表示 h l r h_{lr} hlr,接下来我具体说明这两步。
说明之前,我说一下我的说明的思路。因为事实上作者提出的这个门控机制和 GRU(Gated Recurrent Unit) 是非常像的(尽管图 4 长得与 GRU 不是很像),所以我说明时会将图 4 对应着 GRU 来说明,并且为了方便对应,我会倒着说明。接下来正式开始说明:
-
首先,作者得到句子最后的表示 h l r h_{lr} hlr 的过程可以用下面这个公式表示:
h l r = z l ⊙ h l + z r ⊙ h r + z l r ⊙ h ~ l r (2) h_{lr} = z_l⊙h_l + z_r⊙h_r + z_{lr}⊙\tilde{h}_{lr} \tag2 hlr=zl⊙hl+zr⊙hr+zlr⊙h~lr(2)
其中 z l z_l zl、 z r z_r zr、 z l r z_{lr} zlr 是三个控制门,并且 z l + z r + z l r = 1 ⃗ z_l + z_r + z_{lr} = \vec1 zl+zr+zlr=1 。其实这个公式对应着图 4 很好懂,那这部分如何对应 GRU 呢?其实我们可以大致把 h l h_l hl 和 h r h_r hr 当成历史状态, h ~ l r \tilde{h}_{lr} h~lr 当成候选状态。为了方便理解,下面给出我写的“等价”公式,下面的公式只是大概表达刚刚表述的意思,并不是很准确:
h l r = ( z l , z r ) ⊙ ( h l , h r ) + [ 1 − ( z l , z r ) ] ⊙ h ~ l r (3) h_{lr} = (z_l,z_r)⊙(h_l,h_r) + [1-(z_l,z_r)]⊙\tilde{h}_{lr} \tag3 hlr=(zl,zr)⊙(hl,hr)+[1−(zl,zr)]⊙h~lr(3)
这下是不是发现和 GRU 很像?接下来给出作者对 z l z_l zl、 z r z_r zr、 z l r z_{lr} zlr 的定义:
z l ∞ e x p ( W 4 h l + U 4 h t + b 4 ) z r ∞ e x p ( W 5 h r + U 5 h t + b 5 ) z l r ∞ e x p ( W 6 h ~ l r + U 6 h t + b 6 ) (4) z_l∞exp(W_4h_l + U_4h_t + b_4) \\ z_r∞exp(W_5h_r + U_5h_t + b_5) \\ z_{lr}∞exp(W_6\tilde{h}_{lr} + U_6h_t + b_6) \tag{4} zl∞exp(W4hl+U4ht+b4)zr∞exp(W5hr+U5ht+b5)zlr∞exp(W6h~lr+U6ht+b6)(4)
(PS:原文中公式(4)的第 3 个子公式中给出的是 h ~ e r \tilde{h}_{er} h~er,因为文中没在其他地方见过这个符号,所以应该是写错了。)上面这组公式中的 ∞ ∞ ∞ 符号我不太清楚其具体代表什么运算,但根据其作用,应该代表着做 Softmax 操作。
-
现在公式(2)中未定义的只有 h ~ l r \tilde{h}_{lr} h~lr ,所以下面首先给出其定义:
h ~ l r = t a n h ( W 1 ( r l ⊙ h l ) + U 1 ( r r ⊙ h r ) + b 1 ) (5) \tilde{h}_{lr} = tanh(W_1(r_l⊙h_l) + U_1(r_r ⊙h_r) + b_1) \tag5 h~lr=tanh(W1(rl⊙hl)+U1(rr⊙hr)+b1)(5)
因为上面说过,我们可以将 h ~ l r \tilde{h}_{lr} h~lr 这部分看作是 GRU 的候选状态,而上面这个公式的形式也基本与 GRU 中获得候选状态的公式相同。同样从这个公式的相似也可以看出作者提出的这个门控模型与 GRU 很相似。上式中 r l r_l rl 和 r r r_r rr 的两个门控的定义为:
r l = s i g m o i d ( W 2 h l + U 2 h t + b 2 ) r r = s i g m o i d ( W 3 h r + U 3 h t + b 3 ) (6) r_l = sigmoid(W_2h_l + U_2h_t + b_2) \tag{6} \\ r_r = sigmoid(W_3h_r + U_3h_t + b_3) rl=sigmoid(W2hl+U2ht+b2)rr=sigmoid(W3hr+U3ht+b3)(6)
上述就是作者模型中的门控部分,之后就是用得到的句子的最终表示 h l r h_{lr} hlr 进行情感分类即可。
Reference
- Vo, D.-T., and Zhang, Y. 2015. Target-dependent twitter sentiment classifification with rich automatic features. In Proceedings of the IJCAI, 1347–1353.

