- 1伺服系统的动态校正与控制:位置、转速、电流三环控制系统_伺服系统三环pid
- 2一文带你速通RAG、知识库和LLM!_知识库 rag
- 3sql update 特殊用法
- 4CosyVoice 实测,阿里开源语音合成模型,3s极速语音克隆,5分钟带你部署实战_cosyvoice 合成语音 速度慢
- 5LSSVM-ABKDE基于最小二乘支持向量机结合自适应带宽核函数密度估计的多变量回归预测(点预测+概率预测+核密度估计)_ls-svm 回归曲线
- 6百度api语音_function vol
- 7python中plot实现实时显示数据_python 一边显示图另一边显示数据
- 8Redis项目实战_redis 实战
- 9could not find implicit value for evidence parameter of type org.apache.flink.api.common.typeinfo.Ty
- 10树和二叉树
Python批量导出sql文件,navicat批量导入sql文件_在navicat中如何转储多个sql文件
赞
踩
系列文章目录
前言
当数据库部署在他人的系统上时,例如阿里云,腾讯云等,但是无法登录账号,直接使用阿里云的批量导出,数据库量太大,一个一个的通过navicat的导出不现实,因此就需要一种手段来,批量的导出sql文件,因此我才书写了此篇文章。
一、Python导出
序
因为java操作数据库网上的参考文档较少,因此,此处采用了python来进行sql文件的导出。
Python
import pymysql import subprocess import os # MySQL RDS连接信息 # RDS_HOST 是你的RDS实例的域名或IP地址 RDS_HOST = 'IP' RDS_PORT = 3306 # RDS实例的端口,默认是3306 RDS_USER = 'root' # RDS的用户名 RDS_PASS = 'root' # RDS的密码,这里使用了特殊字符,确保在命令行中不会造成解析问题 # 本地保存SQL文件的目录 LOCAL_DIR = 'D:/sql/' # 指定一个本地目录来保存导出的SQL文件 # 确保本地目录存在 # 如果目录不存在,则创建它 if not os.path.exists(LOCAL_DIR): os.makedirs(LOCAL_DIR) # 连接到MySQL RDS实例 # 使用pymysql库连接到RDS实例 connection = pymysql.connect(host=RDS_HOST, port=RDS_PORT, user=RDS_USER, password=RDS_PASS, charset='utf8mb4', # 使用utf8mb4字符集支持全字符集 cursorclass=pymysql.cursors.DictCursor) # 使用字典游标以便更容易地处理查询结果 try: with connection.cursor() as cursor: # 获取所有数据库名称 # 使用SQL命令SHOW DATABASES;获取所有数据库名 sql = "SHOW DATABASES;" cursor.execute(sql) # 过滤掉系统数据库,只获取用户创建的数据库名 databases = [db['Database'] for db in cursor.fetchall() if db['Database'] not in ['information_schema', 'mysql', 'performance_schema', 'sys']] # 遍历所有数据库并导出到本地 # 遍历每一个数据库 for db_name in databases: # 构造SQL文件路径 sql_file = LOCAL_DIR + db_name + ".sql" # 构造mysqldump命令 # mysqldump是MySQL的一个命令行工具,用于导出数据库 mysqldump_cmd = f"mysqldump --set-gtid-purged=off --column-statistics=0 -h {RDS_HOST} -P {RDS_PORT} -u {RDS_USER} --password={RDS_PASS} --databases {db_name} > {sql_file}" try: # 使用subprocess模块运行mysqldump命令 # shell=True允许在shell中执行命令,check=True表示如果命令返回非零退出码则抛出异常 subprocess.run(mysqldump_cmd, shell=True, check=True, stdout=subprocess.PIPE, stderr=subprocess.PIPE) print("数据库名:", db_name) # 打印成功导出的数据库名 except subprocess.CalledProcessError as e: # 如果mysqldump命令执行失败,捕获异常并打印错误信息 print("错误信息:", e.stderr.decode()) # 注意:这里需要decode()来将bytes转换为str finally: # 无论是否发生异常,都确保连接被关闭 connection.close()

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
注意事项
1.数据库的名称不能为中文名,一旦为中文名,在编译mysqldump命令的时候,会出现乱码的情况,并且报错,导致无法正常导出
2.上面的mysqldump部分的命令为mysql5.7的命令,如果使用的数据库版本为8.0,并且运行上面的命令报错,还请自行百度,8.0的命令是什么,从而进行修改 mysqldump_cmd 属性值
3.因为这个不仅仅是导出了数据库的表结构,还导出了数据,因此可能导出的速度会偏慢,如果出现输出了正确的命令的,但是卡住的情况,还请耐心等待,此时数据库正在进行sql文件的导出
4.如果是从文件管理器里,直接复制路径的话,他默认采用的是反斜线,会自动转义,导致实际路径与访问路径不符,因此一定要手动替换斜线
二、sql合并
序
如果使用navicat进行导入的话,多个文件的导入效率依旧缓慢,因此需要把所有的sql文件进行统一的合并成一个文件,然后进行导入。
windows操作
此时我们需要使用到windows的文件合并命令
具体的命令为
cd D:\sql
type *.sql >allMysql.sql
- 1
- 2
因为我是在对应的路径下进行的操作,因此需要先进入对应的路径下,然后使用type命令进行文件的合并
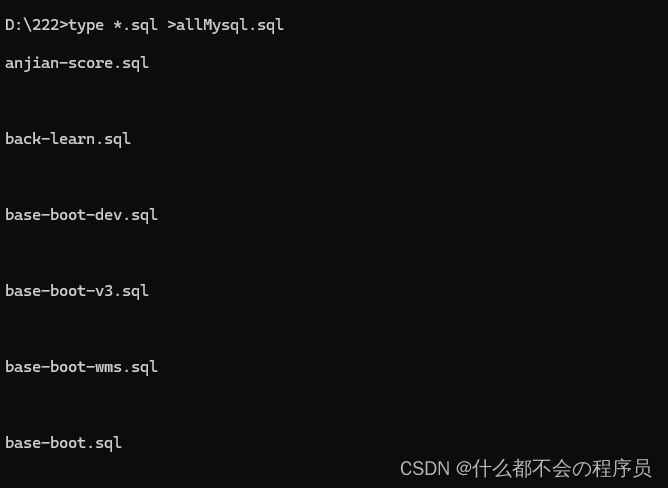
可以看到他在不断地合并文件,直到所有的文件都合并完成,即可在navicat下运行已经合并好的文件,等到导入完成后即可使用
注意事项
中文不要参与合并,最好单独导入,否则容易出各种字节码类型的问题
Navicat导入
如果文件太大会出现报错
[ERR] 2006 - Server has gone away
- 1
此时需要调整限传大小,运行下面的命令,重新运行sql即可
set global max_allowed_packet = 1024*1024*1024
- 1
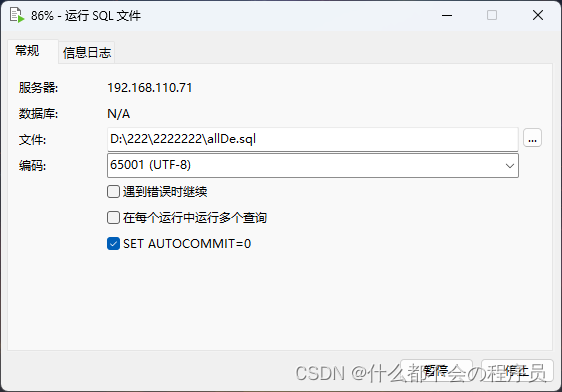
在导入文件的时候一定要勾选掉在每个运行中运行多个查询,否则很容易报错