- 1Yolov8多头检测头优化微小目标检测精度的技巧_yolov8小目标检测头
- 2如何站在成功人士的肩上成为一个真正的巨人————《赛马娘 Pretty Derby》评测_如何评价pretty derby
- 3使用Python和Echarts进行数据可视化分析:旅游景点销量和星级景点统计
- 4基于AidLux平台的智慧交通中对抗防御监测应用评测_aidlux 障碍物检测
- 5Claude3 正式发布,支持多模态(附注册使用教程)_claude 3如何免费使用
- 6白噪声检测_几种噪声标签识别算法简介
- 7AI辅写疑似度:学校是否会查?一篇文章为你揭秘_研究室论文查aigc吗
- 8sample函数随机抽取训练集和测试集_测试集的sample
- 92024年展望:AI辅助研发引领科技创新潮流,重塑未来研发格局_恋情辅助科技2024
- 10网络安全相关证书资料——OSCP、CISP-PTE
基于深度强化学习的路径规划算法【matlab仿真与代码】_深度学习路径规划算法
赞
踩
一、内容简介
路径规划是指物体处于存在障碍物的路径规划环境中,利用有效的路径规划算法使得物体规划出从起始位置到目标位置的较优路径,从而使物体能够在较短的时间内到达目标位置,并在规划过程中躲避障碍物。求解路径规划的算法可以分为精确算法、近似算法、启发式算法、亚启发式算法。近年来,机器学习算法也被应用在路径规划领域。基于机器学习的路径规划算法根据训练方法的不同,可分为监督学习、无监督学习和强化学习。其中,监督学习和无监督学习两种训练方法都需要大量的训练数据,如果训练数据不足则无法较好的进行路径规划。为了解决上述问题,研究人员引入了强化学习。强化学习可以使物体在与环境交互获取信息,路径规划算法根据获取的信息进行训练,最终得到较优路径。然而,基于强化学习的路径规划算法会出现维数灾难、收敛速度慢、可移植性差和泛化性弱等问题。为了解决上述问题,研究人员将深度学习与强化学习相结合,提出了基于深度强化学习的训练方法。
此次改进的创新点主要在于:
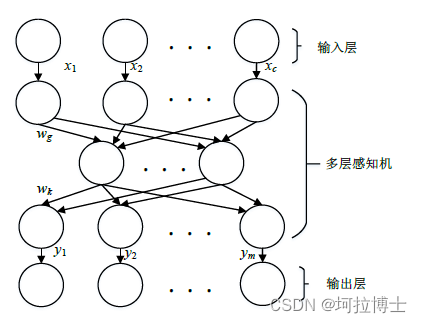
(1)针对传统 DQN 路径规划算法因神经网络、奖励函数以及动作选择机制存在的不足导致路径规划效率低的问题,提出了一种改进 DQN 的路径规划算法,该算法对上述三个方面进行改进。首先通过引入多层感知机对神经网络结构进行修改,从而加快神经网络的收敛速度;其次,通过改进奖励函数获得动态奖励值,使物体执行不同动作获取不同的奖励值,根据得到的不同奖励值计算每个动作的价值,使得神经网络的参数更加精准;最后,通过修改动作选择机制,解决了物体在路径规划后期因随机选择动作导致物体错过较优动作的问题。
(2)针对ERDQN 路径规划算法中的 Q 值过高估计和经验池中高效数据无法被更好利用导致网络更新速度慢的问题,提出了PER-ERD3QN 路径规划算法。首先,该算法将ERDQN 路径规划算法与双 Q 网络和竞争网络相结合,通过改变Q 值的计算方式和改变网络结构解决Q 值过高估计问题;其次引入了优先经验回放机制,通过为经验池中的数据设置优先级来提高经验池中较优数据被抽到的概率,从而更好的利用经验池中的较优数据。实验结果表明,PER-ERD3QN 路径规划算法拥有更高的平均得分和平均奖励值,因此该算法的网络更新速度更快。
二、算例与成果
基于DQN 的路径规划算法
- 输入:当前物体状态(物体位置)。
- 输出:目标网络参数。
- 初始化超参数、环境数据和容量为H的经验池D;for episode = 1,2,.....o;
- b -生成随机数字;
- if b>E:
- at-随机生成i个数,选择最大值对应的动作;/*
- i为动作个数,每个数对应一个动作*/
- else:
- at预测网络选择奖励值最大的动作;
- St+1物体执行at选择下一步方向;奖励函数根据状态st计算奖励值 rt;D;=(Stat, 7t。SH1), i∈[1.HI];
- /*将物体与环境交互的样本数据(st,at, 7t,St+i)存储经验池中*/”—更新Qr;
- /*在经验池中随机抽取一批样本数据(s, a,1, s ')进行神经网络的更新*/。- Q;
- /*当预测网络更新迭代一定次数之后,对目标网络进行更新*/
- end for

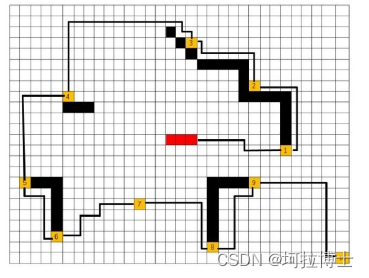
算例结果
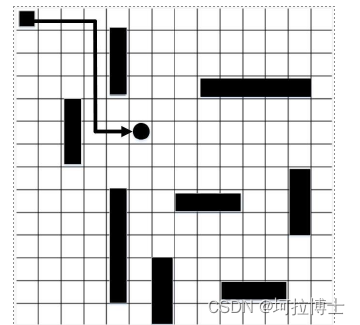
算法结果