
- 1JavaScript基础(前端的知识,很详细,很详细,很详细)_javascript前端
- 2太强了,英伟达面对ChatGPT还有这一招..._英伟达chat gpt
- 3MSCOMCTL.OCX文件缺少找不到如何解决的?
- 4如何为JBoss Developer Studio 8设置BPM和规则工具
- 5设计模式学习笔记 - 设计模式与范式 -结构型:3.装饰器模式
- 6springboot actuator 监控组件应用
- 7汽车自动驾驶是人工智能吗,自动驾驶是人工智能_无人驾驶和人工智能的关系
- 8tp5.0路由配置及thinkphp5.1使用Route路由说明
- 9FISCO BCOS区块链平台上的智能合约压力测试指南_fisco-bcos
- 10图神经网络综述_ggn和gan
谷歌开源大模型Gemma初体验_gemma 模型 精调
赞
踩
简介
2024年2月21日,谷歌发布了一系列最新的开放式大型语言模型 —— Gemma!
Gemma 提供两种规模的模型:7B 参数模型,针对消费级 GPU 和 TPU 设计,确保高效部署和开发;2B 参数模型则适用于 CPU 和移动设备。每种规模的模型都包含基础版本和经过指令调优的版本。
- Gemma发布博客:https://huggingface.co/blog/zh/gemma
- Gemma文档:https://huggingface.co/docs/transformers/v4.38.0/en/model_doc/gemma
- GPU colab教程:https://huggingface.co/google/gemma-7b/blob/main/examples/notebook_sft_peft.ipynb
- TPU训练脚本示例:https://huggingface.co/google/gemma-7b/blob/main/examples/example_fsdp.py
- 基于Hugging Face微调示例:https://huggingface.co/blog/zh/gemma-peft
以下内容参考huggingface博客
PEFT
对于中等大小的语言模型,常规的全参数训练也会非常占用内存和计算资源。对于依赖公共计算平台进行学习和实验的用户来说,如 Colab 或 Kaggle,成本可能过高。另一方面,对于企业用户来说,调整这些模型以适应不同领域的成本也是一个需要优化的重要指标。参数高效微调(PEFT)是一种以低成本实现这一目标的流行方法。
在 Hugging Face 的 transformers 中,Gemma 模型已针对 PyTorch 和 PyTorch/XLA 进行了优化,使得无论是 TPU 还是 GPU 用户都可以根据需要轻松地访问和试验 Gemma 模型。随着 Gemma 的发布,我们还改善了 PyTorch/XLA 在 Hugging Face 上的 FSDP 使用体验。这种 FSDP 通过 SPMD 的集成还让其他 Hugging Face 模型能够通过 PyTorch/XLA 利用 TPU 加速。本文将重点介绍 Gemma 模型的 PEFT 微调,特别是低秩适应(LoRA)。
想要深入了解 LoRA 技术,我们推荐阅读 Lialin 等人的
- “Scaling Down to Scale Up”
- 以及 Belkada 等人的 精彩文章。
环境配置
pip install -q -U bitsandbytes==0.42.0
pip install -q -U peft==0.8.2
pip install -q -U trl==0.7.10
pip install -q -U accelerate==0.27.1
pip install -q -U datasets==2.17.0
pip install -q -U transformers==4.38.1
- 1
- 2
- 3
- 4
- 5
- 6
模型下载
要访问 Gemma 模型文件,用户需先填写 同意表格。
现在,让我们开始实施。
假设您已提交同意表格,您可以从 Hugging Face Hub 获取模型文件。
除此之外,也可以从modelscope上面下载模型文件
modelscope模型卡链接:https://www.modelscope.cn/models/AI-ModelScope/gemma-7b-it/summary
下载代码示例:
#模型下载
from modelscope import snapshot_download
model_name = 'AI-ModelScope/gemma-7b-it'
cache_dir = 'models'
model_dir = snapshot_download(model_name,cache_dir=cache_dir)
- 1
- 2
- 3
- 4
- 5
微调示例
首先得有huggingface 账号,需要设置HF_TOKEN:
import os
os.environ['HF_TOKEN'] = "xxxxxxxxxxxx"
- 1
- 2
下载模型和分词器 (tokenizer),其中包含了一个 BitsAndBytesConfig 用于仅限权重的量化:
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM, BitsAndBytesConfig
# model_id = "google/gemma-2b"
model_path = "/workspace/models/AI-ModelScope/gemma-2b"
bnb_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_dtype=torch.bfloat16
)
tokenizer = AutoTokenizer.from_pretrained(model_path, token=os.environ['HF_TOKEN'])
model = AutoModelForCausalLM.from_pretrained(model_path, quantization_config=bnb_config, device_map={"":0}, token=os.environ['HF_TOKEN'])
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
在开始微调前,我们先使用一个相当熟知的名言来测试一下 Gemma 模型:
text = "Quote: Imagination is more"
device = "cuda:0"
inputs = tokenizer(text, return_tensors="pt").to(device)
outputs = model.generate(**inputs, max_new_tokens=20)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
- 1
- 2
- 3
- 4
- 5
- 6
数据集加载
选择一个英文“名人名言”数据集:
from datasets import load_dataset
# data = load_dataset("Abirate/english_quotes")
data = load_dataset("/workspace/datasets/Abirate/english_quotes")
data = data.map(lambda samples: tokenizer(samples["quote"]), batched=True)
- 1
- 2
- 3
- 4
- 5
注意,由于服务器不能链接外网,所以需要自己手动下载数据集,再上传,加载时只需指明数据集的路径即可,推荐使用github desktop下载,比较方便
微调Gemma
import transformers from trl import SFTTrainer def formatting_func(example): text = f"Quote: {example['quote'][0]}\nAuthor: {example['author'][0]}" return [text] trainer = SFTTrainer( model=model, train_dataset=data["train"], args=transformers.TrainingArguments( per_device_train_batch_size=1, gradient_accumulation_steps=4, warmup_steps=2, max_steps=10, learning_rate=2e-4, fp16=True, logging_steps=1, output_dir="outputs", optim="paged_adamw_8bit" ), peft_config=lora_config, formatting_func=formatting_func, ) trainer.train()

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
微调示例:
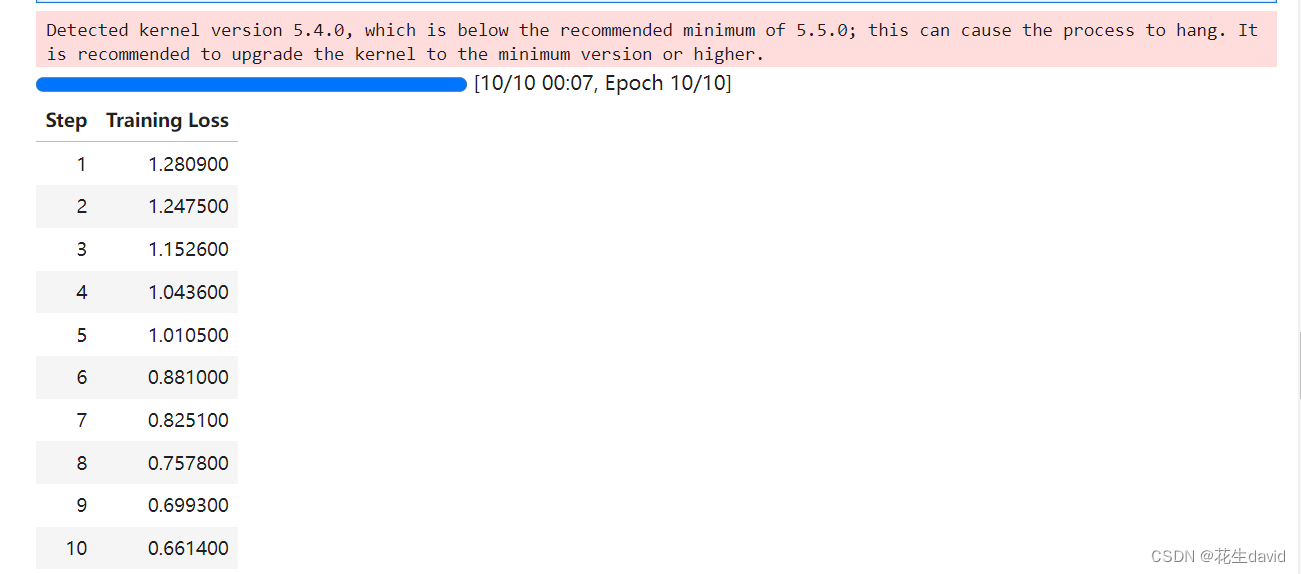
不知道为啥有个warning,但是不影响微调训练,测试一下结果:
text = "Quote: Imagination is"
device = "cuda:0"
inputs = tokenizer(text, return_tensors="pt").to(device)
outputs = model.generate(**inputs, max_new_tokens=20)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
- 1
- 2
- 3
- 4
- 5
- 6

总结
大体流程就是这样的,另外推荐使用hugging face 的聊天演示做些测试:
- https://huggingface.co/chat
排行榜查看在这里: - https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard
更多内容请查看这里:
- Gemma发布博客:https://huggingface.co/blog/zh/gemma
- Gemma文档:https://huggingface.co/docs/transformers/v4.38.0/en/model_doc/gemma
- GPU colab教程:https://huggingface.co/google/gemma-7b/blob/main/examples/notebook_sft_peft.ipynb
- TPU训练脚本示例:https://huggingface.co/google/gemma-7b/blob/main/examples/example_fsdp.py
- 基于Hugging Face微调示例:https://huggingface.co/blog/zh/gemma-peft


