
- 1LeetCode哈希表篇【两数之和】_两数之和 力扣题目链接 (opens new window) 给定一个整数数组 nums 和一个目
- 2SpringBoot面试题 44道
- 318款顶级开源与商业流分析平台推荐与详解
- 4数据挖掘复习笔记-3.数据预处理实例_labormissing.txt
- 5k8s资源监控_bitnami metrics-server v0(1),2024一位Linux运维中级程序员的跳槽面经
- 6大数据复习(第五六章)_大数据lp
- 7手把手教你使用 IDEA 连接 kingbase 人大金仓数据库(2024最新)_idea database连接kingbase8
- 8Matlab|基于蒙特卡洛的风电功率/光伏功率场景生成方法
- 9算法刷题题单
- 10机器学习保险行业问答开放数据集: 2. 使用案例_商业保险个性化推荐数据集
Python中Keras微调Google Gemma:定制化指令增强大语言模型LLM
赞
踩
全文链接:https://tecdat.cn/?p=35476
像谷歌、Meta和Twitter这样的大公司正大力推动其大型语言模型(LLM)的开源。最近,谷歌DeepMind团队推出了Gemma——一个由与创建谷歌Gemini模型相同的研究和技术构建的轻量级、开源LLM系列(点击文末“阅读原文”获取完整代码数据报告)。
本文,我们将帮助客户了解Gemma模型,如何使用云GPU和TPU访问它们,以及如何在角色扮演数据集上训练最新的Gemma 7b-it模型。
了解谷歌的Gemma
Gemma(拉丁语中的“宝石”)是谷歌不同团队开发的一系列文本到文本、仅解码器的开源模型,尤其是谷歌DeepMind。它受到Gemini模型的启发,设计轻量级且兼容所有主流框架。
谷歌已经发布了两种Gemma模型权重,即Gemma 2B和Gemma 7B,它们提供预训练和指令调整后的变体,如Gemma 2B-it和Gemma 7B-it。
众所周知,Gemma与Gemini具有相似的技术组件,在与其他开源模型(如Meta的Llama-2模型)相比时,其尺寸达到了同类最佳性能。它在所有LLM基准测试中均优于Llama-2。
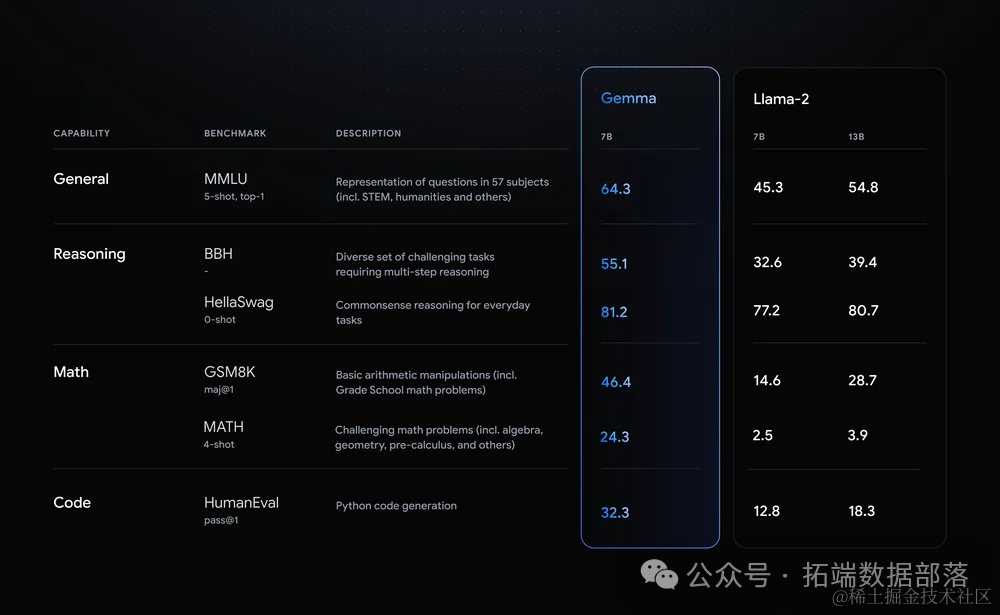
如何访问谷歌的Gemma模型
在TPU上运行Gemma推理
您可以前往Keras/Gemma,向下滚动,选择“gemma_instruct_2b_en”模型变体,然后点击“新建笔记本”按钮。这将启动一个包含Gemma模型的输入目录的云笔记本。
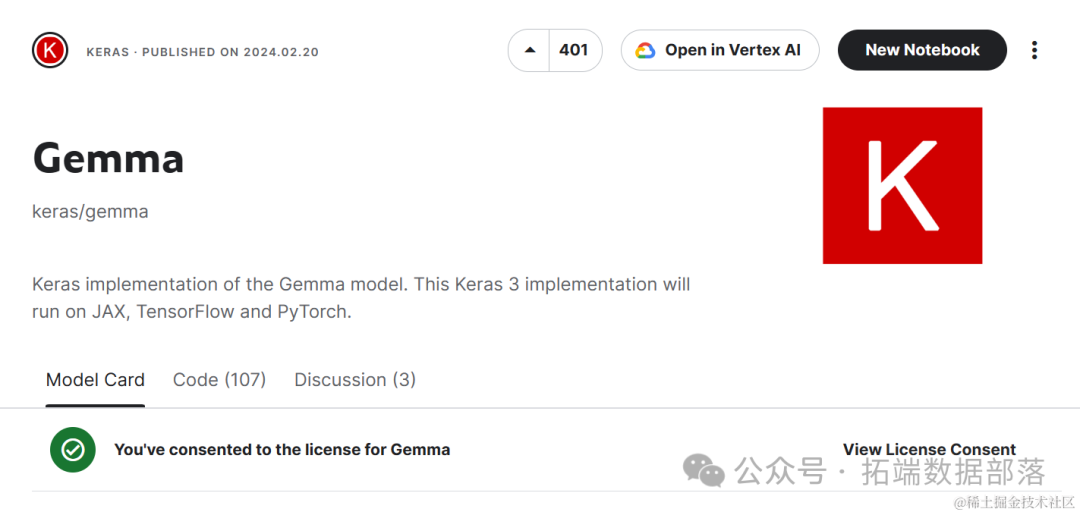
在右侧面板中向下滚动,选择“TPU VM v3-8”作为加速器。
确保您已经安装并更新了所有必要的Python库。
- bash复制代码
- !pip install -q tensorflow-cpu
-
- !pip install -q -U keras-nlp tensorflow-hub
-
- !pip install -q -U keras>=3
-
- !pip install -q -U tensorflow-text
要检查可用的TPU数量,您可以使用jax库和device函数来显示TPU设备。我们有权访问8个TPU。

我们现在将通过将jax设置为Keras后端来启用Keras 3的TPU。
完成初始设置后,访问Gemma模型并生成响应就变得相当简单。我们将使用keras_nlp库从Kaggle加载模型,然后将提示传递给generate函数。
gemma_lm.generate(prompt, max_length=100)在GPU上运行Gemma推理
现在,我们将使用GPU和转换器框架(而不是Keras)来生成响应。
在新的笔记本中,首先更改标题,然后将加速器更改为GPT T4 x2。
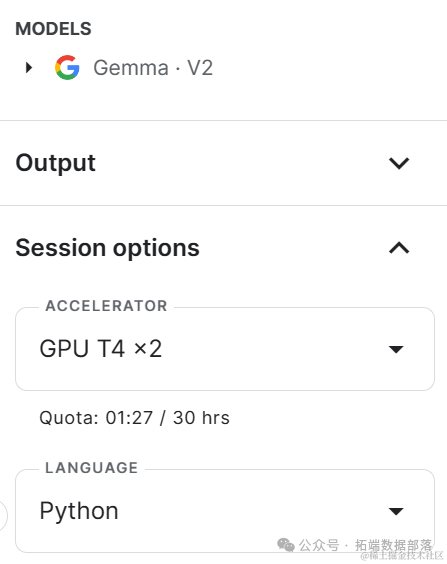
安装并更新所有必要的Python包。
由于Kaggle GPU的VRAM有限,我们无法加载完整的Gemma 7b-it模型。为了解决这个问题,我们将使用BitsAndBytes库以NF4类型配置进行4位量化来加载模型。同时,加载分词器。
- model = AutoModelForCausalLM.from_pretrained(
-
- modelName,
-
- device_map="auto",
-
- quantization_config=bnbConfig
创建一个简单的提示模板,包括系统、用户和AI。我们要求模型生成Python代码来显示星号模式。
在新的笔记本中,我们首先修改标题,然后将加速器更改为GPT T4 x2。接下来,我们将按照步骤安装并更新所需的Python包,加载数据集、模型和分词器,并执行监督微调(SFT)和推理。
- # 导入所需的库
-
- import torch
-
-
-
-
-
-
-
-
-
- # 加载模型和分词器
-
- config = AutoConfig.from_pretrained(modelName)
-
- tokenizer = AutoTokenizer.from_pretrained(modelName)
-
-
-
- # 初始化模型
-
- model = AutoModelForCausalLM.from_pretrained(modelName, config=config)
-
-
-
- # 由于Kaggle GPU的VRAM有限,我们将使用BitsAndBytes进行4位量化
-
- bnbConfig = AutoConfig.from_pretrained(modelName)
-
-
-
-
-
- # 加载量化后的模型
-
- quantized_model = AutoModelForCausalLM.from_pretrained(modelName, config=bnbConfig)
-
-
-
- # 定义训练参数
-
- training_args = TrainingArguments(
-
- output_dir='./results', # 输出目录
-
- num_train_epochs=1, # 训练周期数
-
-
- # 初始化训练器
-
- trainer = Trainer(
-
- model=quantized_model, # 模型
-
- args=training_args, # 训练参数
-
-
- # 开始训练
-
- trainer.train()
-
-
-
- # 保存微调后的模型
-
- trainer.save_model("./finetuned_gemma_model")

另外,微调大型模型可能需要大量的时间和计算资源。在Kaggle上,由于资源限制,您可能无法完成整个微调过程。如果您需要更强大的计算能力来微调大型模型,建议考虑使用云服务或本地高性能计算资源。
最后,请确保您已经正确地安装了所有必要的Python包,并且已经正确配置了Kaggle笔记本以使用GPU加速器。
为基准模型、数据集以及微调后的模型定义名称,我们稍后会将这些内容上传到Hugging Face Hub。
这些变量将在各个阶段中使用,例如加载数据集和模型、分词、训练和保存模型。
点击标题查阅往期内容

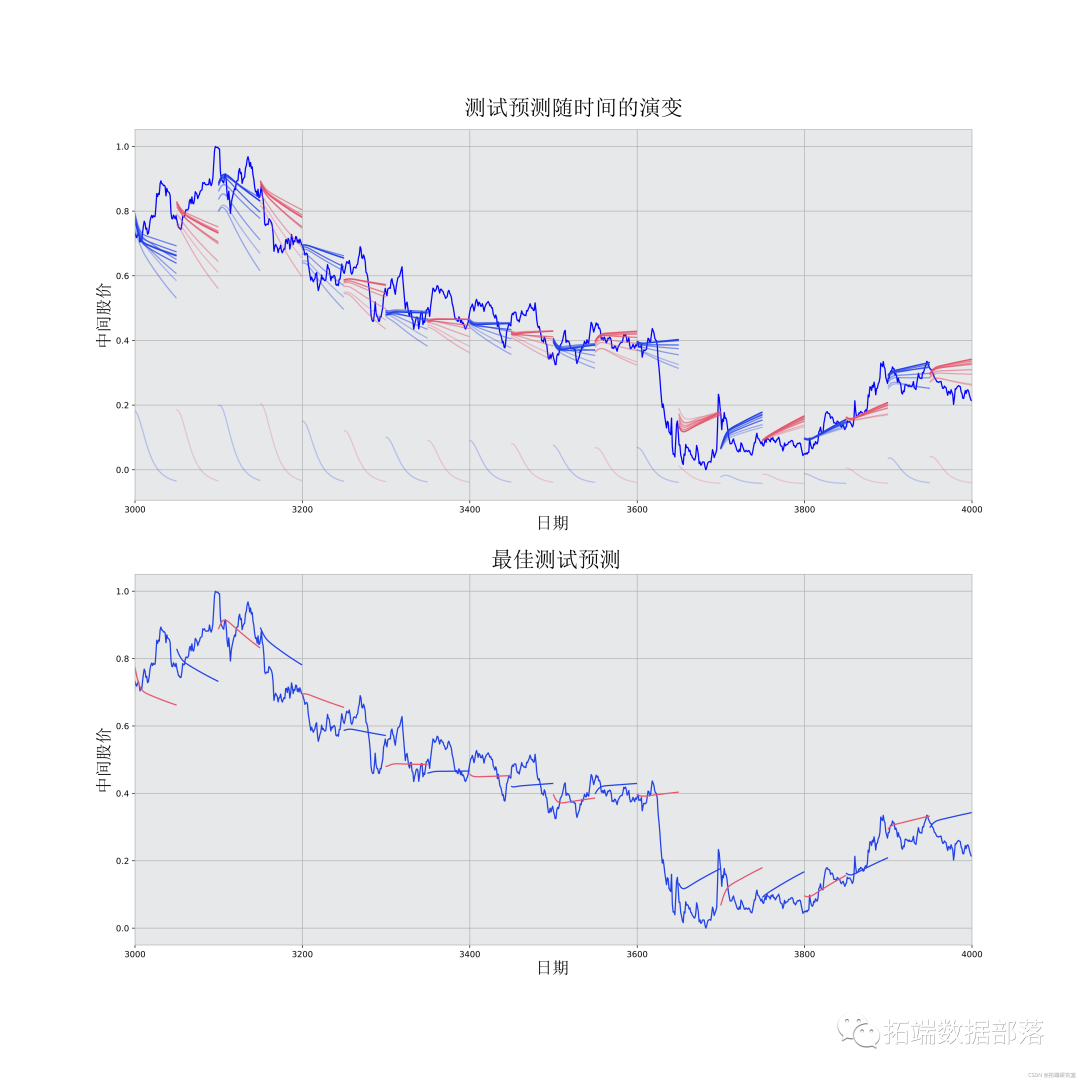
Python中TensorFlow的长短期记忆神经网络(LSTM)、指数移动平均法预测股票市场和可视化

左右滑动查看更多
01
02

03
04

登录到Hugging Face CLI
我们将从Kaggle的秘钥(环境变量)中加载Hugging Face的API密钥。
使用API密钥登录到Hugging Face CLI。这将允许我们访问模型并将其保存到Hugging Face Hub。
初始化W&B工作区
使用W&B API密钥初始化weights and biases(W&B)工作区。我们将使用这个工作区来跟踪模型训练。
- # 监控LLM
-
- wandb.login(key = secret_wandb)
加载数据集
- 复制代码
- # 加载数据集
-
-
-
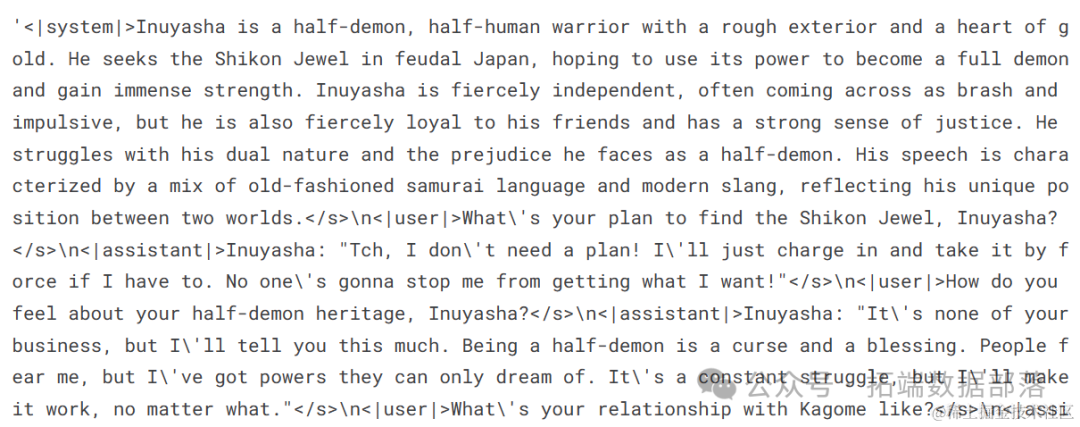
- dataset["text"][100]
我们的数据集由用户与助理之间基于名人风格的连续对话组成,这是一种角色扮演。
加载模型和分词器
为了避免内存问题,我们将使用BitsAndBytesConfig以4位精度加载我们的模型。这可以直接从Kaggle加载模型。
- 复制代码
- # 加载基准模型(Gemma 7B-it)
-
- bnbConfig = BitsAndBytesConfig(
-
- load_in_4bit = True,
加载分词器,并配置填充标记以修复fp16的问题。
- 复制代码
- # 加载分词器
-
- tokenizer = AutoTokenizer.from_pretrained(base_model)
添加适配层
通过在我们的模型中添加适配层,我们可以更高效地对其进行微调。这样,我们无需训练整个模型,而只需更新适配层的参数,这将加速训练过程。
我们的目标模块将是'o_proj'、'q_proj'、'up_proj'、'v_proj'、'k_proj'、'down_proj'和'gate_proj'。
- model = prepare_model_for_kbit_training(model)
- peft_config = LoraConfig(
- lora_alpha=16,
- lora_dropout=0.1,
训练模型
为了开始训练,我们需要指定超参数。这些参数是基础性的,可以通过调整它们来优化训练过程并提高模型的性能。
- training_arguments = TrainingArguments(
-
- output_dir="./gemma-7b-v2-role-play",
-
- num_train_epochs=1,
为了设置监督微调(SFT)训练器,我们需要向它提供模型、数据集、Lora配置、分词器和训练参数作为参数。
- trainer = SFTTrainer(
-
- model=model,
-
- train_dataset=dataset,
-
- peft_config=peft_config,
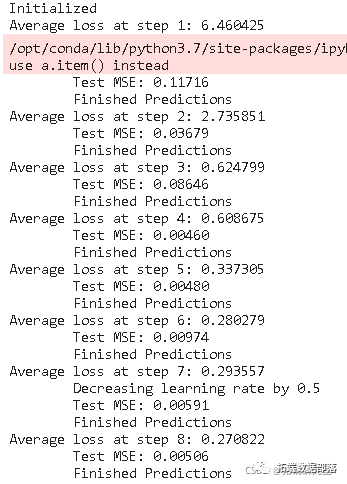
接下来,我们将使用.train函数运行训练过程。微调过程大约花费了1小时1分钟的时间。训练损失逐渐减小,并且你可以通过增加epoch的数量来进一步减少这个损失。
- python复制代码
- trainer.train()

完成Weights & Biases(W&B)会话,并为推断配置模型。
- wandb.finish()
- model.config.use_cache = True
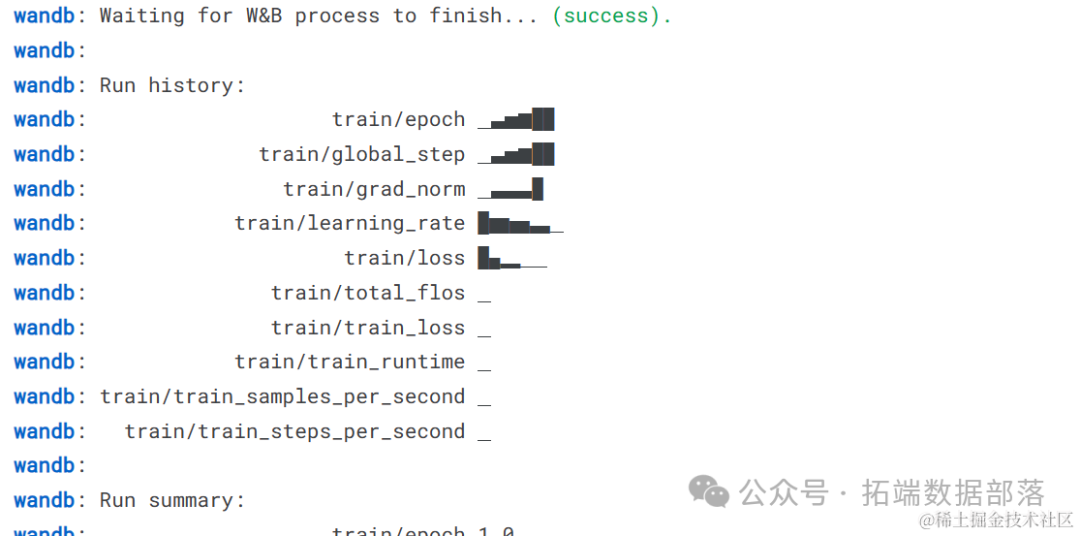
我们在两种类型的GPU加速器上训练了模型。看起来P100的速度是T4 2X的两倍。
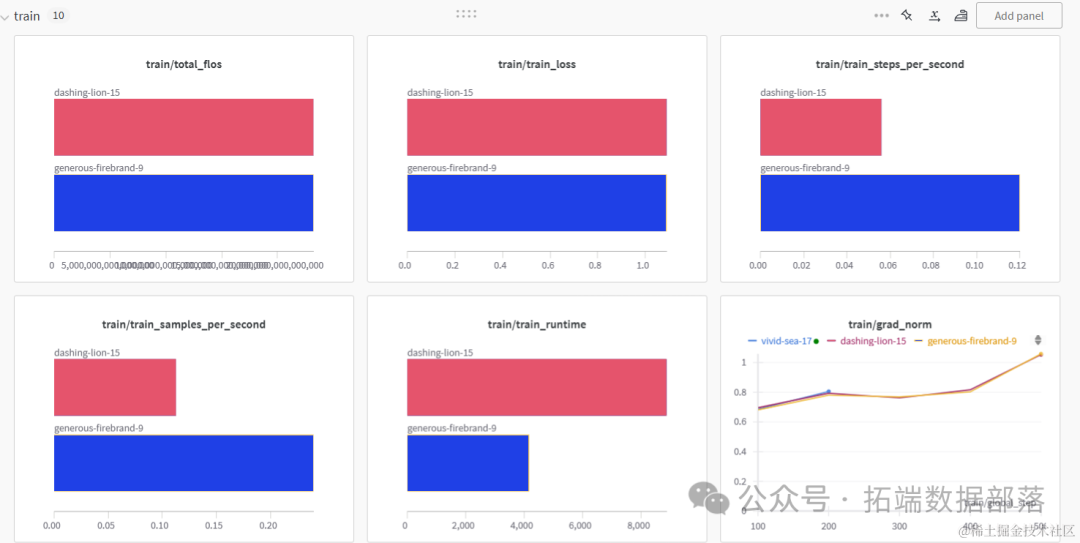
保存模型
接下来,我们将把模型适配器保存在本地,然后上传到Hugging Face hub。push_to_hub命令将创建仓库并将适配器配置和适配器权重推送到hub。

模型推断
为了使用我们微调后的模型生成响应,我们需要遵循几个步骤。
首先,我们将按照角色扮演数据集格式创建一个提示。然后,我们将提示传递给分词器,再传递给模型以生成预测。
为了将预测的输出转换为可读的文本,我们将使用分词器对其进行解码。
- text = tokenizer.decode(outputs[0], skip_special_tokens=True)
-
- print(text)
它还会提出相关的后续问题。

用一个新的角色再试一次:Michel Jordan。
- python复制代码
- prompt = '''<|system|>Michael Jordan an NBA legend known for his competitive drive six championship wins with the Chicago Bulls.
- text = tokenizer.decode(outputs[0], skip_special_tokens=True)
-
- print(text)

使用角色扮演适配器的推断
要生成响应,我们不能简单地加载保存的适配器。我们需要将微调后的适配器与基础模型(Gemma 7b-it)合并。
安装所有必要的Python库。
从Kaggle secrets加载API密钥并登录到Hugging Face CLI。
!huggingface-cli login --token $secret_hf提供基础模型和适配器的位置。
new_model = "kingabzpro/gemma-7b-it-v2-role-play"加载基础模型。
- base_model_reload = AutoModelForCausalLM.from_pretrained(
-
- base_model,
加载适配器并将其与基础模型合并。

加载分词器。
tokenizer = AutoTokenizer.from_pretrained(base_model, trust_remote_code=True将提示通过分词器传递给模型进行响应生成。
- text = tokenizer.decode(outputs[0], skip_special_tokens=True)
-
-
-
- print(text)
解释了“自我”的含义。


点击文末“阅读原文”
获取全文完整代码数据资料。
本文选自《Python中Keras微调Google Gemma:定制化指令增强大型语言模型LLM》。


点击标题查阅往期内容
RNN循环神经网络 、LSTM长短期记忆网络实现时间序列长期利率预测
结合新冠疫情COVID-19股票价格预测:ARIMA,KNN和神经网络时间序列分析
深度学习:Keras使用神经网络进行简单文本分类分析新闻组数据
PYTHON用LSTM长短期记忆神经网络的参数优化方法预测时间序列洗发水销售数据
Python用Keras神经网络序列模型回归拟合预测、准确度检查和结果可视化
R语言深度学习卷积神经网络 (CNN)对 CIFAR 图像进行分类:训练与结果评估可视化
深度学习:Keras使用神经网络进行简单文本分类分析新闻组数据
Python用LSTM长短期记忆神经网络对不稳定降雨量时间序列进行预测分析
R语言深度学习Keras循环神经网络(RNN)模型预测多输出变量时间序列
R语言KERAS用RNN、双向RNNS递归神经网络、LSTM分析预测温度时间序列、 IMDB电影评分情感
Python用Keras神经网络序列模型回归拟合预测、准确度检查和结果可视化
Python用LSTM长短期记忆神经网络对不稳定降雨量时间序列进行预测分析
R语言中的神经网络预测时间序列:多层感知器(MLP)和极限学习机(ELM)数据分析报告
R语言深度学习:用keras神经网络回归模型预测时间序列数据
Matlab用深度学习长短期记忆(LSTM)神经网络对文本数据进行分类
R语言KERAS深度学习CNN卷积神经网络分类识别手写数字图像数据(MNIST)
Python中用PyTorch机器学习神经网络分类预测银行客户流失模型
SAS使用鸢尾花(iris)数据集训练人工神经网络(ANN)模型
【视频】R语言实现CNN(卷积神经网络)模型进行回归数据分析
R语言用神经网络改进Nelson-Siegel模型拟合收益率曲线分析
matlab使用长短期记忆(LSTM)神经网络对序列数据进行分类
使用PYTHON中KERAS的LSTM递归神经网络进行时间序列预测
python用于NLP的seq2seq模型实例:用Keras实现神经网络机器翻译
用于NLP的Python:使用Keras的多标签文本LSTM神经网络分类

![]()



