
热门标签
热门文章
- 1【GitHub】保姆级使用教程
- 2github安装_如何用 Github 搭建博客
- 3gpt-2 生成文本_对gpt 2进行了微调,以实现神奇的收集风味文本生成
- 4对抗训练方法:保卫人工智能的盾牌_对抗性训练
- 5【快速上手ESP32(基于ESP-IDF&VSCode)】03-定时器
- 6如何使用Matlab进行图像处理_matlab图像处理
- 7ASP.NET Core MVC 从入门到精通之初窥门径_.net core入门到精通
- 8nodejs google search console api对接之提交网址到索引
- 9Hadoop伪分布式安装配置_hadoop伪分布式安装需要修改 、 两个配置文件
- 10探秘机器学习核心逻辑:梯度下降的迭代过程 (图文详解)_梯度下降迭代
当前位置: article > 正文
文本相似度算法总结_文本相似度匹配算法
作者:花生_TL007 | 2024-04-07 18:53:45
赞
踩
文本相似度匹配算法
文本匹配算法主要用于搜索引擎,问答系统等,是为了找到与目标文本最相关的文本。例如信息检索可以归结成查询项和文档的匹配,问答系统可以归结为问题和候选答案的匹配,对话系统可以归结为对话和回复的匹配。
一、传统模型
基于字面匹配
- 字面距离:字符串有字符构成,只要比较两个字符串中每一个字符是否相等便知道两个字符串是否相等,或者更简单一点将每一个字符串通过哈希函数映射为一个哈希值,然后进行比较。
- 主要方法:TF-IDF、BM25 、simhash
语义匹配
- LSA类模型 通过LSA得到的文本主题矩阵可以用于文本相似度计算,而计算方法一般是通过余弦相似度。
二、文本距离的概念(计算向量间的距离)
- 欧几里德距离
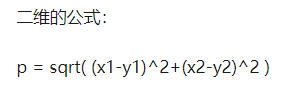
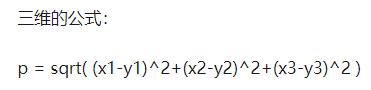
- 曼哈顿距离

- 切比雪夫距离
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/花生_TL007/article/detail/379991
推荐阅读
相关标签

