
- 1【学习笔记】《卓有成效的管理者》 第四章 如何发挥人的长处_卓有成效的管理者第四章如何发挥人的长处
- 240种顶级思维模型,学会任何1种都让你受用无穷,赶紧点赞收藏
- 3简单介绍agv仓储叉车基本原理及操作方法_agv叉车怎么行驶
- 4【自然语言处理】【大模型】BLOOM:一个176B参数且可开放获取的多语言模型_bloom-176b
- 5bottle微框架从注册到应用(一)———基础配置_bottle框架
- 6ETL第八章无人售货机零售项目实践_大数据etl——无人售货机零售项目实战
- 7OpenHarmony实战:小型系统平台驱动移植
- 8《青少年成长管理2024》016 “成长七要素之二:情感”2/4
- 9Azure OpenAI 语音转语音聊天_azure openai 语音转语音聊天 restful
- 10深度学习之前馈神经网络(前向传播和误差反向传播)
ChatDoctor: A Medical Chat Model Fine-tuned on LLaMA Model using Medical Domain Knowledge
赞
踩
基本信息
这是23年5月发表在arxiv上的一篇文章。
博客创建者
武松
作者
Yunxiang Li, Zihan Li, Kai Zhang, Ruilong Dan, You Zhang
标签
LLM, ChatGPT, Prompt
1. 摘要
在语言大模型百花齐放的当下,虽然各个模型都有着令人惊讶的表现,但仍然存在一些问题,比如模型容易产生错误的言论以及对事实的歪曲,这被称作"hallucination",即“幻觉”。如何降低幻觉是通用语言模型领域在未来的一个重要的研究方向,将LLM应用到具体的领域,结合领域知识做应用研究也是重要的研究方向。这篇文章中,作者用领域知识对语言大模型进行prompt微调,使得模型产生的回答具有权威依据。这篇工作中的领域权威知识来自作者构建的疾病数据库以及维基百科组成的外部知识库,通过构建分步的prompt提示来训练模型自动化检索这个外部知识库,获得可信回答,并将其组合成对话结果返回给病人。作者工作实现了LLM在医疗问答上的应用,并一定程度上解决了幻觉问题。
2. 方法
2.1 方法架构图

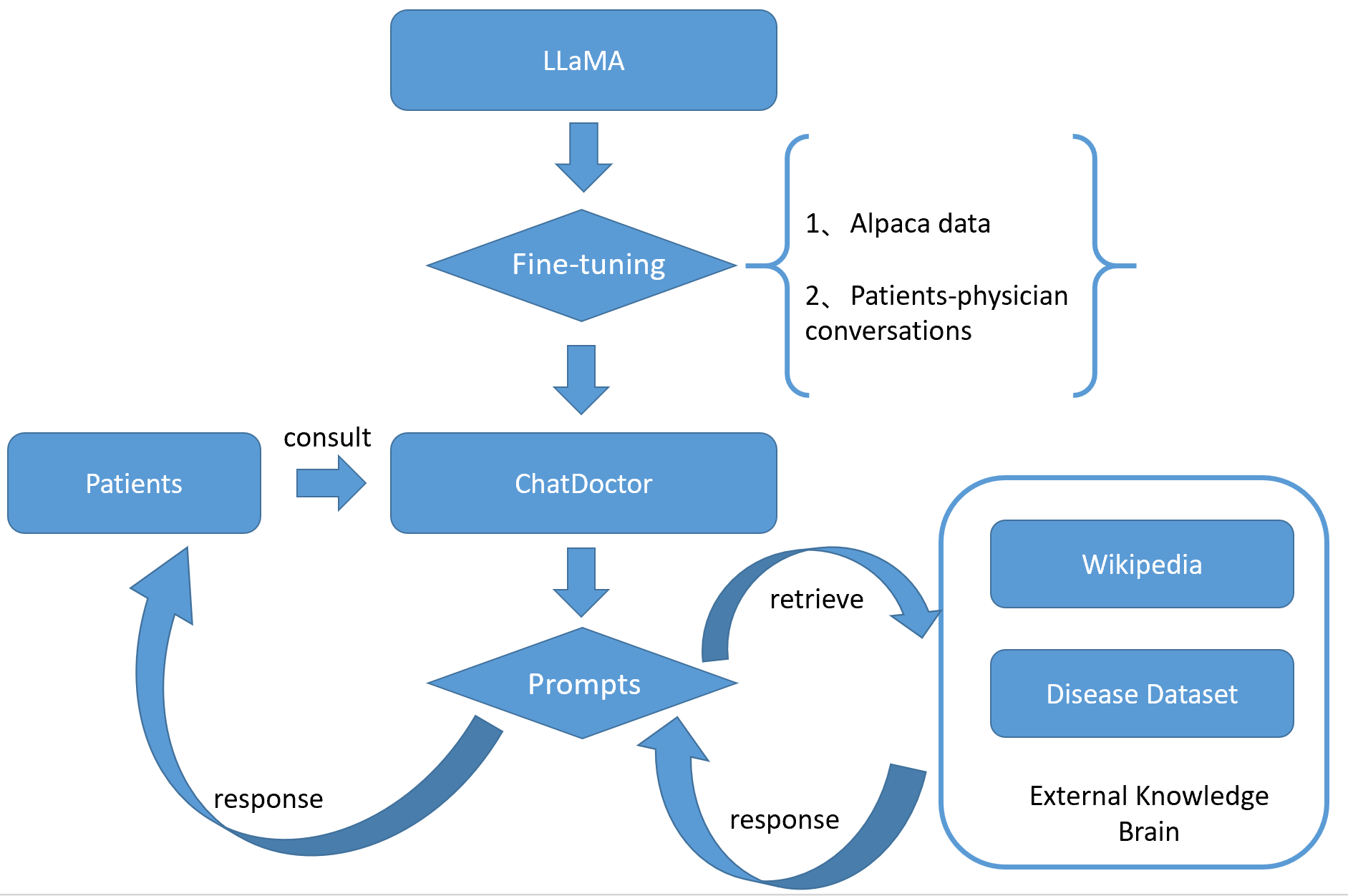
2.2 方法描述
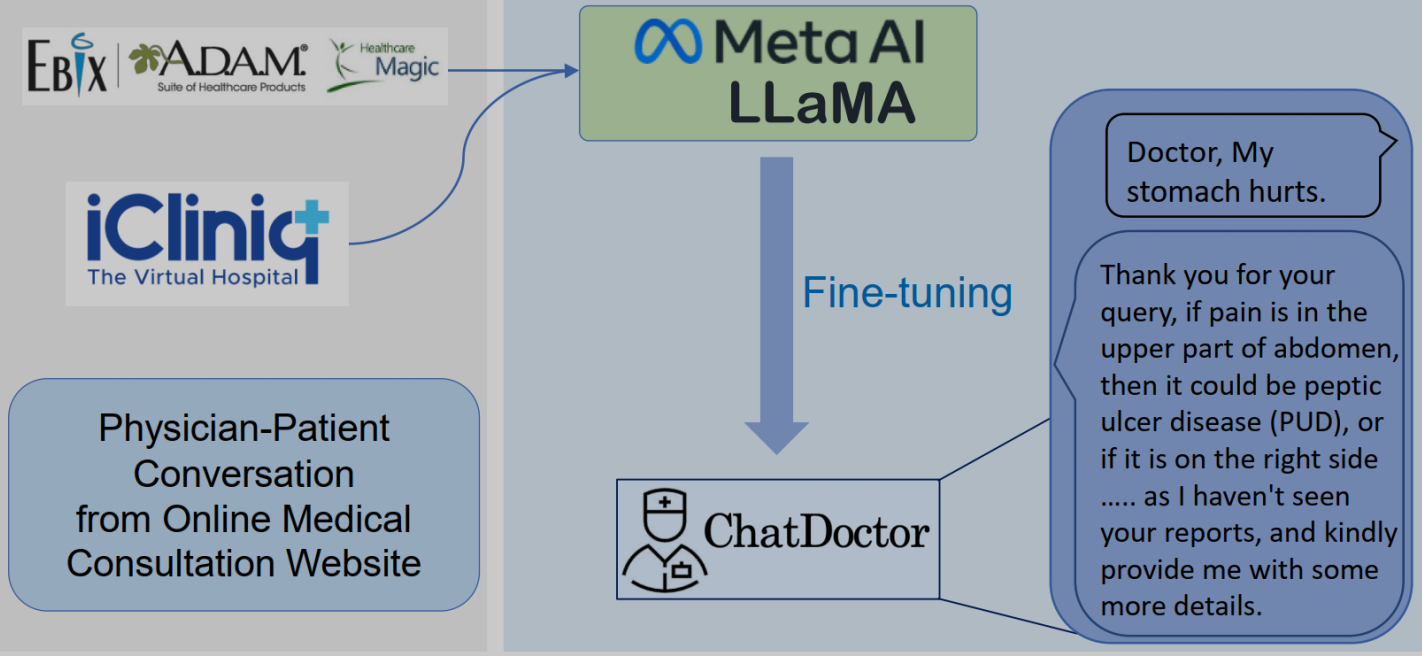
ChatDoctor基于LLaMA模型进行微调,进行了基于alpaca数据集的指令微调和作者收集的患者-医生对话数据集的微调。然后在此基础上设计了引入外部知识库查询的prompt模板,在医患对话过程中,使用prompt来获取模型更精准的输出。
2.2.1 医患对话数据集(Patient-physician Conversation Dataset)
作者团队需要构建一个患者-医生对话的数据集来对模型进行微调考虑到,往往会导致多样性不足和描述过度专门化的问题,这些问题往往与真实场景不同。收集真正的医患对话是一个更好的解决方案。因此,作者从一个在线医疗咨询网站healthcaremagic中收集了大约10万条真实的医患对话数据作为微调模型的训练数据集,并手动或自动地过滤数据,删除医生和患者的真实身份信息,并使用语言工具来纠正语法错误,该数据集命名为HealthCareMagic-100k,如图2.2所示。此外,作者也从在线医疗咨询网站iCliniq中收集了大约1万条患者-医生对话数据,用来评估模型的性能。
2.2.2 外部知识库(External Knowledge Brain)
对于模型出现的幻觉(hallucination)问题,即模型的回答可能出现错误,且不可控制,这对于医疗领域是不可接受的。作者在这个问题上的解决办法是对模型回答的生成引入外部知识库的权威知识,使得模型生成的结果具有参考和可靠的来源。因此作者针对ChatDoctor构建了一个外部知识库,主要包括两部分:疾病数据库(Disease Database)和维基百科检索(Wikipedia retrieval)。作者的工作主要是构建了疾病数据库,其中包括大约700种疾病及其相关症状、进一步的医疗测试或措施,以及推荐的药物,如图2.3所示。外部知识库的知识是通过在模型推理阶段的prompt过程中进行检索的。外部知识库可以实时更新和检索,而无需重新训练模型,保证了回答的时效性。

2.2.3 基于外部知识库的自主ChatDoctor
要使得ChatDoctor能够自动地检索外部知识库并生成具有医患问答特色的回答,需要使用前两部分数据库进行检索。通过构建合适的prompts,来让模型自动检索外部知识。prompts包含以下几个步骤:
- 首先是让模型给出患者问题描述的几个有助于查询答案的关键词,如图2.4所示:

接着就会使用模型返回的几个关键词向维基百科的接口发起查询,并获取返回的文本(仅获取相关性最高的几个文本)。
- 第二步是让模型选取疾病数据库中的相关数据条目,即将疾病数据库相关数据送入prompt的输入部分,然后获取模型选取的有助于回答问题的几条疾病数据,如图2.5所示:

- 第三步,将以上从维基百科查询得到的文本和从疾病数据库查询得到的疾病数据条目加入第三步的prompt输入部分,让模型根据这些信息来对患者问题作出回答,如图2.6所示:

- 第四步,在实现中,每一篇维基百科返回的文本都会进行前三步,然后获得回答,这些回答会放入一个列表 answer_list 中,在第四步中,再让模型从这些回答中选出一个最好的回答来作为最终回答返回给患者,如图2.7所示。

3. 训练步骤(微调)
- 遵循Stanford Alpaca的训练方法,用其数据集对LLaMA进行微调获得基本的对话能力;
- 之后使用作者收集的医患对话数据集来prompt微调模型让模型具有医患对话的特定格式和知识。在这生成答案的过程中会检索外部知识库获得权威知识然后组成最后答案。
作者提供了LoRA微调方式的代码,可以极大节省微调训练成本。
4. 实验
4.1 数据集
- 本文获取的医患对话数据集
4.2 参数设置
- 使用Alpaca数据集的微调训练参数同Alpaca论文中相同;
- 医患对话数据集微调训练过程中使用的超参数如下:总批量大小为192,学习率为 2 × 1 0 − 5 2×10^{-5} 2×10−5,共3个epoch,最大序列长度为512个tokens,预热比为0.03,没有权重衰减。
4.3 实验结果及分析
实验部分主要是与chatgpt进行比较,从定性和定量两个角度来进行对比。采用从iCliniq上获取的1万条医患对话数据来进行实验验证。
4.3.1 定量比较
使用真实医患对话数据中的医生回答作为ground truth来计算模型输出与之的差距,用BERT Score计算回答的表现水平,具体计算Precision, Recall and F1 scores三个指标,对比ChatDoctor和ChatGPT的表现。结果如图4.1所示。

4.3.2 定性比较
通过在面对实际患者问题下ChatDoctor和ChatGPT的回答来定性对比二者的表现水平。
- 首先是比较来验证知识的时效性。对于一种23年才被WHO命名的疾病Mpox(猴痘),让两者进行回答,由于ChatGPT的训练数据截至到21年,因此不能回答出关于Mpox的治疗方法。而由于ChatDoctor连接了在线的外部知识库,因此能对该问题作出回答。如图4.2所示。

- 其次是验证回答的准确性和权威性。如图4.3-4.5所示。



5. 总结
5.1 亮点
- 考虑到了大语言模型在医疗问答的应用,并使用外部知识库实时检索的方式来保证生成回答的权威性和时效性。
5.2 不足
- 没有从模型层面考虑幻觉问题的根本解决方法,虽然外部知识库也一定程度上缓解了这个问题,但是不能完全保证模型在医疗问题上回答的严谨性。
5.3 启发(下一步工作)
- 将LLM应用到更多的领域
- 考虑如何降低幻觉
6. 相关知识链接
@article{yunxiang2023chatdoctor,
title={Chatdoctor: A medical chat model fine-tuned on llama model using medical domain knowledge},
author={Yunxiang, Li and Zihan, Li and Kai, Zhang and Ruilong, Dan and You, Zhang},
journal={arXiv preprint arXiv:2303.14070},
year={2023}
}
- 1
- 2
- 3
- 4
- 5
- 6

