
热门标签
热门文章
- 1基于java的校园活动管理小程序源码_java校园活动项目
- 2vue中英文切换i18n_vue3后台管理项目中实现中英文切换
- 3ubuntu22.04安装Fcitx5的步骤
- 4Vue多语言、全屏处理_vue 多语言显示title
- 5【IOS开发高级系列】dyld专题
- 6mysql约束之默认约束default_mysql添加默认约束
- 7[iOS 获取AppStored 中应用的下载地址]_ios 获取appstore 应用地址
- 8idea中的on update action中无Update classes and resources--解决方案_idea使用debug模式启动时,没有update classes and resources重启方
- 9AI+软件工程:10倍提效!用ChatGPT编写系统功能文档_chatgpt planuml
- 10一天破万:二十一个微信公众号推广技巧(终结版)_csdn会员 微信公众号推广
当前位置: article > 正文
基于交互注意力机制的多模态情感识别算法_交互注意力机制 多模态
作者:花生_TL007 | 2024-04-01 17:09:09
赞
踩
交互注意力机制 多模态
基于交互注意力机制的多模态情感识别算法
论文介绍
原著:
《基于交互注意力机制的多模态情感识别算法》
2021 Application Research of Computers
研究问题
多模态机制下的情感识别,在多模态下,需要提取大量的特征。但特征数量多,造成一是训练参数增大。二是产生噪声,关键信息被遗漏。在模型融合时,要关注主要特征,因此需引入注意力机制。
研究方法
文章研究文本+语音的多模态。提出的多交互注意力机制网络:GATASA(Global Acoustic-to-text and Acoustic-to-Self Acoustic to Text) 。两(互补)部分组成:1、GATA :强调所有的信息。2、ASATA:强调局部信息。这两部分由两种不同的注意力机制在文本和音频特征之间交互计算注意力分数。
深度学习中的文本数据处理:去掉不需要的停止词(stop word) -> 对单词做词嵌入(embedding)。词嵌入通常基于现有的词向量(word vector)、基于预训练的Glove 、BERT 。对于多个数据源的特征,可加入注意力机制。
注意力机制
处理思路:通过对特征向量计算权重分数并加权求和。通过不同的权重分数体现特征的重要性。
组成:
- Query:单个输入向量
- Key :多个特征向量
注意力机制分数:过点积或可学习参数投影等方法计算出来的Key 和 Query 的相互关系。
-
Value:注意力机制分数对 Key 加权求和。
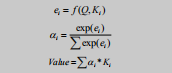
数据处理:
-
文本数据
特征提取:循环神经网络
-
音频数据
特征选择:频谱图:可以同时得到时域和频域信息。
特征提取:卷积-循环神经网络,先卷积提取各区域的特征再将其作为LSTM的输入。
实现过程:

技术介绍
训练图:
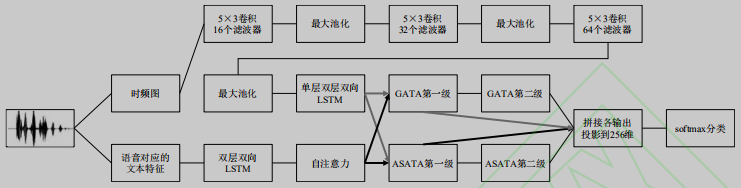
技术栈:
LSTM(解决梯度消失问题):提取文本、经卷积处理后的音频特征。
CNN:提取音频特征
输出
- 情感识别中,如何定义、量化人类的情感
- 引入视频、图像信息、人体生理信号信息(EEG、EOG、EMG)
- 融合方式(特征层、决策层、模型层)
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/花生_TL007/article/detail/349670
推荐阅读
相关标签

