
热门标签
热门文章
- 1浅析axios及封装方法_axios 封装
- 2华为HarmonyOS开发实践--电影卡片应用开发_harmony os arkts卡片开发的简单案例
- 31+x 云计算平台运维与开发测试题_deployment更新可能需要使用的命令不包含哪个
- 4SAP BASIS ADM100 中文版 Unit 10(1)_sap adm100
- 5Android ScrollView自动滑动一段距离的问题解决
- 6Android Studio导入Android源码(推荐)_android studio导入ipr关联项目
- 7uni-App 封装 uni.request() 发起网络请求_uni.request判断网络是否通顺
- 8BroadcastReceiver应用详解以及Android实现点击通知栏后,先启动应用再打开目标Activity...
- 9javascript将对象的数值型属性值改为字符型_js将对象中的数字属性转为字符
- 10利用阿里云服务器搭建私有云电脑(Windows 11),不受局域网限制,安卓iOS也可随时远程访问_阿里云windows服务器环境
当前位置: article > 正文
YOLOv8添加注意力机制(ShuffleAttention为例)_yolov8 预训练 + 注意力机制
作者:羊村懒王 | 2024-03-29 21:16:21
赞
踩
yolov8 预训练 + 注意力机制
1 前言
注意力机制是非常重要的改进手段,yolov8是目标检测目前最先进的技术,本文将详细展示如何在yolov8中添加注意力机制。
最新版代码见此贴【新版yolov8添加注意力机制(以NAMAttention注意力机制为例)】
2. 如何改进
2.1 注意力机制代码
本文以ShuffleAttention为例:
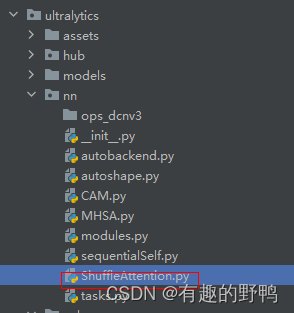
在ultralytics\文件夹下创建ShuffleAttention.py,以下是代码。
import numpy as np
import torch
from torch import nn
from torch.nn import init
from torch.nn.parameter import Parameter
class ShuffleAttention(nn.Module):
def __init__(self, channel=512, reduction=16, G=8):
super().__init__()
self.G = G
self.channel = channel
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.gn = nn.GroupNorm(channel // (2 * G), channel // (2 * G))
self.cweight = Parameter(torch.zeros(1, channel // (2 * G), 1, 1))
self.cbias = Parameter(torch.ones(1, channel // (2 * G), 1, 1))
self.sweight = Parameter(torch.zeros(1, channel // (2 * G), 1, 1))
self.sbias = Parameter(torch.ones(1, channel // (2 * G), 1, 1))
self.sigmoid = nn.Sigmoid()
def init_weights(self):
for m in self.modules():
if isinstance(m, nn.Conv2d):
init.kaiming_normal_(m.weight, mode='fan_out')
if m.bias is not None:
init.constant_(m.bias, 0)
elif isinstance(m, nn.BatchNorm2d):
init.constant_(m.weight, 1)
init.constant_(m.bias, 0)
elif isinstance(m, nn.Linear):
init.normal_(m.weight, std=0.001)
if m.bias is not None:
init.constant_(m.bias, 0)
@staticmethod
def channel_shuffle(x, groups):
b, c, h, w = x.shape
x = x.reshape(b, groups, -1, h, w)
x = x.permute(0, 2, 1, 3, 4)
# flatten
x = x.reshape(b, -1, h, w)
return x
def forward(self, x):
b, c, h, w = x.size()
# group into subfeatures
x = x.view(b * self.G, -1, h, w) # bs*G,c//G,h,w
# channel_split
x_0, x_1 = x.chunk(2, dim=1) # bs*G,c//(2*G),h,w
# channel attention
x_channel = self.avg_pool(x_0) # bs*G,c//(2*G),1,1
x_channel = self.cweight * x_channel + self.cbias # bs*G,c//(2*G),1,1
x_channel = x_0 * self.sigmoid(x_channel)
# spatial attention
x_spatial = self.gn(x_1) # bs*G,c//(2*G),h,w
x_spatial = self.sweight * x_spatial + self.sbias # bs*G,c//(2*G),h,w
x_spatial = x_1 * self.sigmoid(x_spatial) # bs*G,c//(2*G),h,w
# concatenate along channel axis
out = torch.cat([x_channel, x_spatial], dim=1) # bs*G,c//G,h,w
out = out.contiguous().view(b, -1, h, w)
# channel shuffle
out = self.channel_shuffle(out, 2)
return out
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
2.2 修改task.py
打开task.py
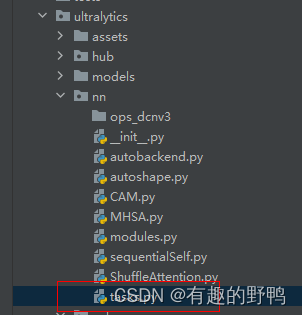
导入刚刚添加的包:
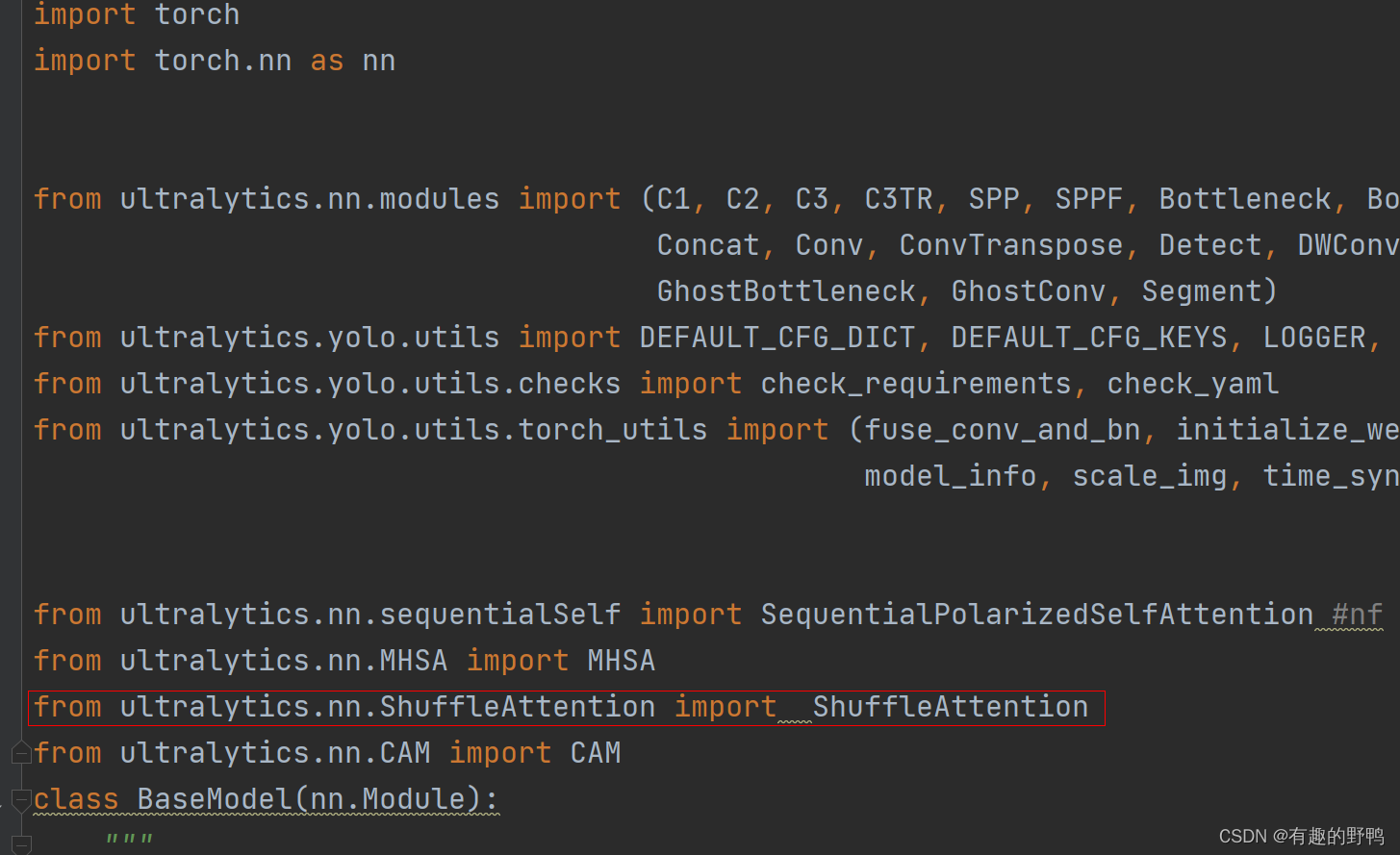
ctrl+f找到def parse_model(d, ch, verbose=True): 方法。如下图
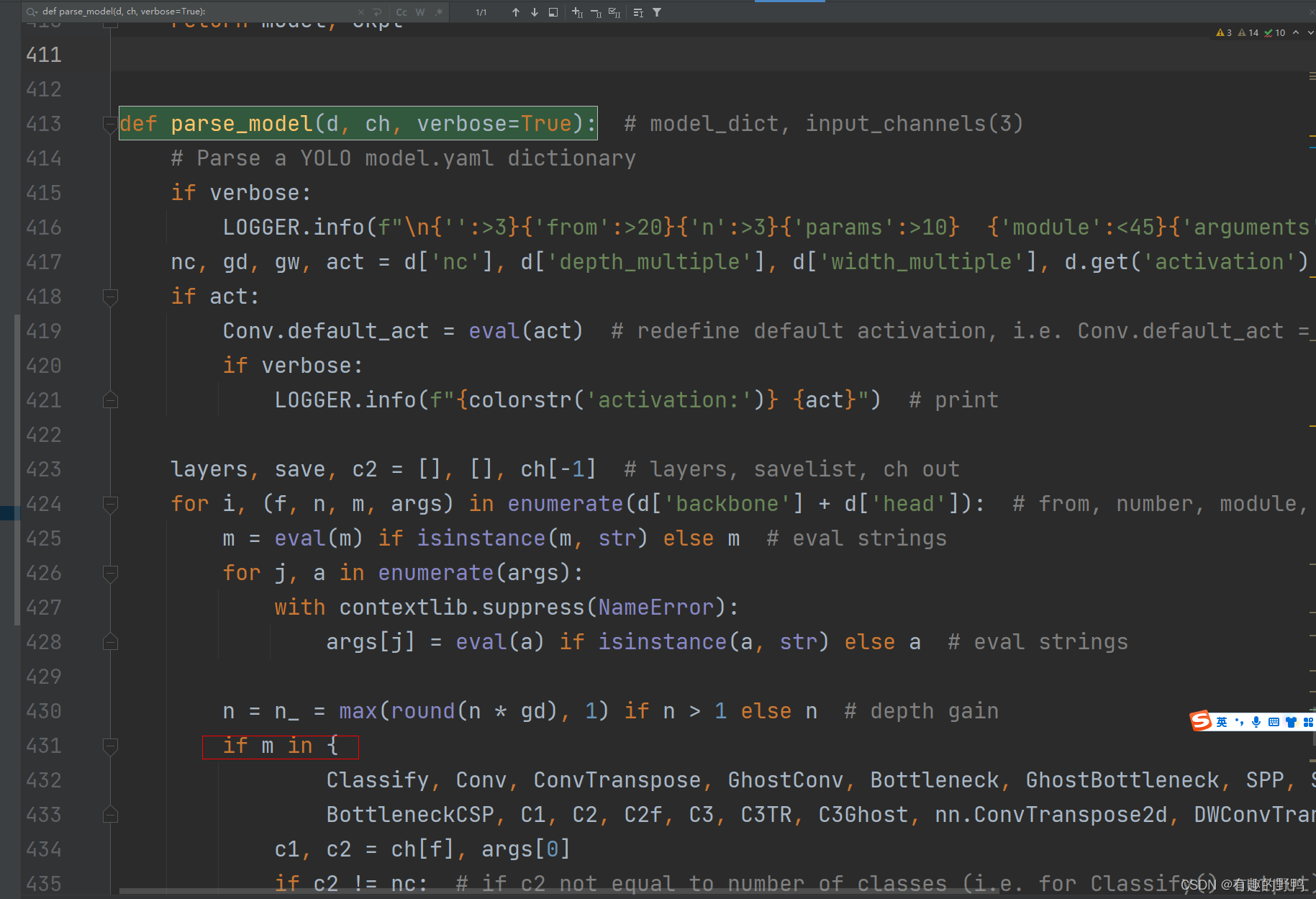
如上图,找到if m in xxx
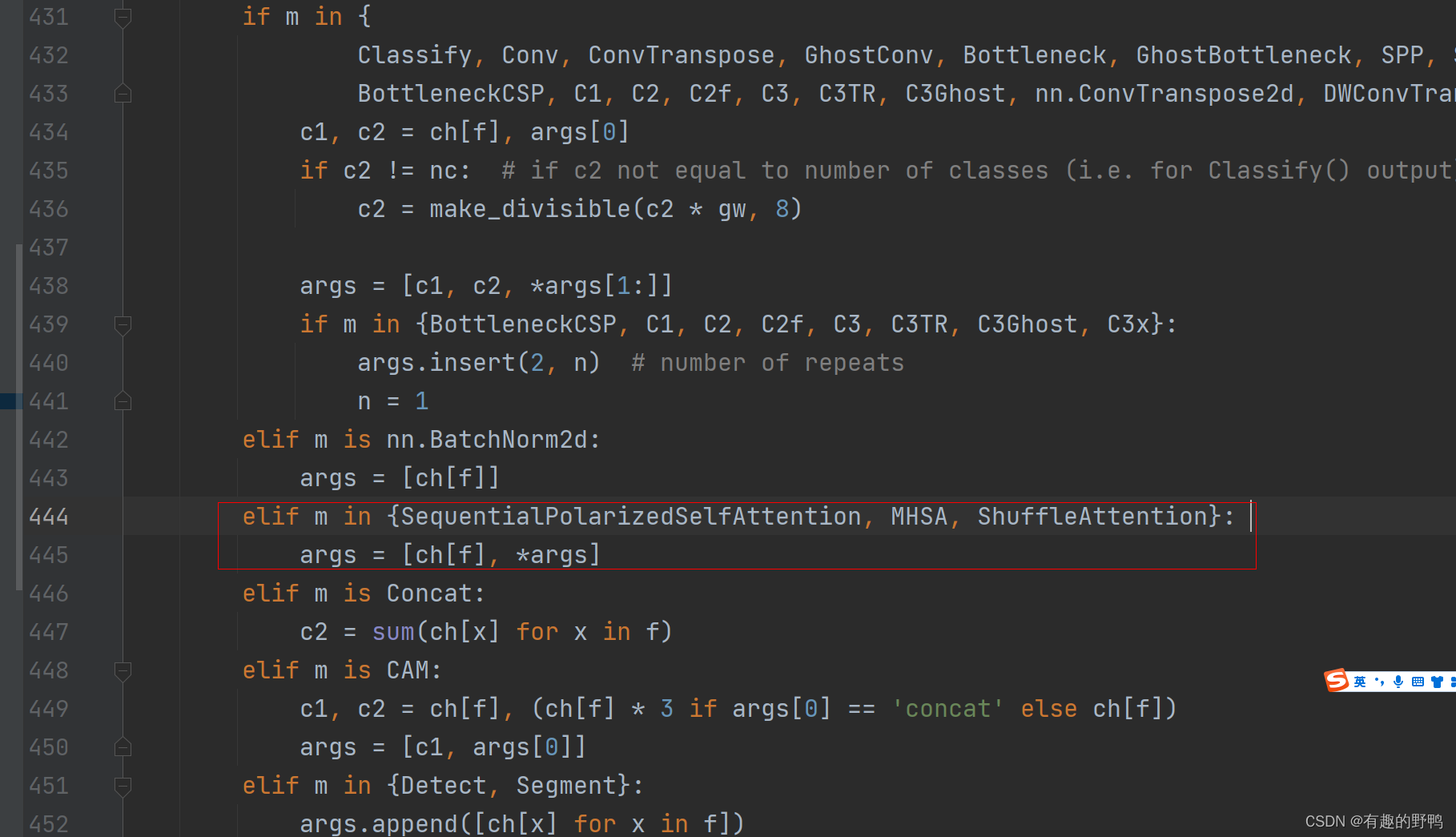
在下方elif里面添加自己的注意力机制,如果只有一个注意力机制,则如下代码,如果有多个,像上方截图。
elif m in {ShuffleAttention}: #在此处添加自己的注意力机制,命名是刚刚的类名
args = [ch[f], *args]
- 1
- 2
2.3 修改模型
找到模型的位置ultralytics/models/v8/yolov8n.yaml,将此模型拷贝一次,在模型中添加自己的注意力机制,如下代码所示。
如果用的yolov8s,则修改yolov8s.yaml
# Ultralytics YOLO 声明:本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:【wpsshop博客】推荐阅读
相关标签
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

