
热门标签
热门文章
- 1面试官各种打压你,python爬虫爬取豆瓣电影Top250(1),Python高级面试framework
- 2《意志力》_父母给的钱不够吃早餐
- 3Redis数据类型, 在springboot中集成Redis_springboot redis list类型
- 4STA | 7. SDC是如何炼成的?Exception篇 - 附MCP电路实现方法及命令优先级实例
- 5HBase常用的shell命令_hbase substring:
- 6Parallels Desktop 16 已损坏,无法打开,您应该推出磁盘映像。怎么解决?_parallels desktop已损坏,推出磁盘映像
- 7【MySQL基础】MySQL基本数据类型_mysql数据类型
- 8物体检测-系列教程16:YOLOV5 源码解析6(马赛克数据增强函数load_mosaic)_yolov5mosaic数据增强代码
- 911.图论_图的复杂度
- 10DC与DCT DCG的区别_dc dct
当前位置: article > 正文
任务4.8.4 利用Spark SQL实现分组排行榜
作者:繁依Fanyi0 | 2024-06-23 13:55:02
赞
踩
任务4.8.4 利用Spark SQL实现分组排行榜

1. 任务说明

2. 解决思路

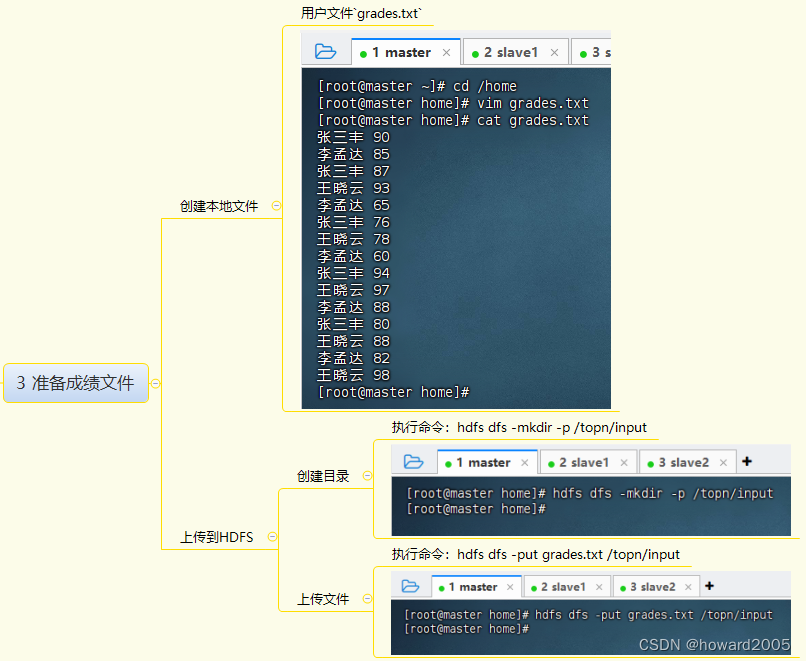
3. 准备成绩文件
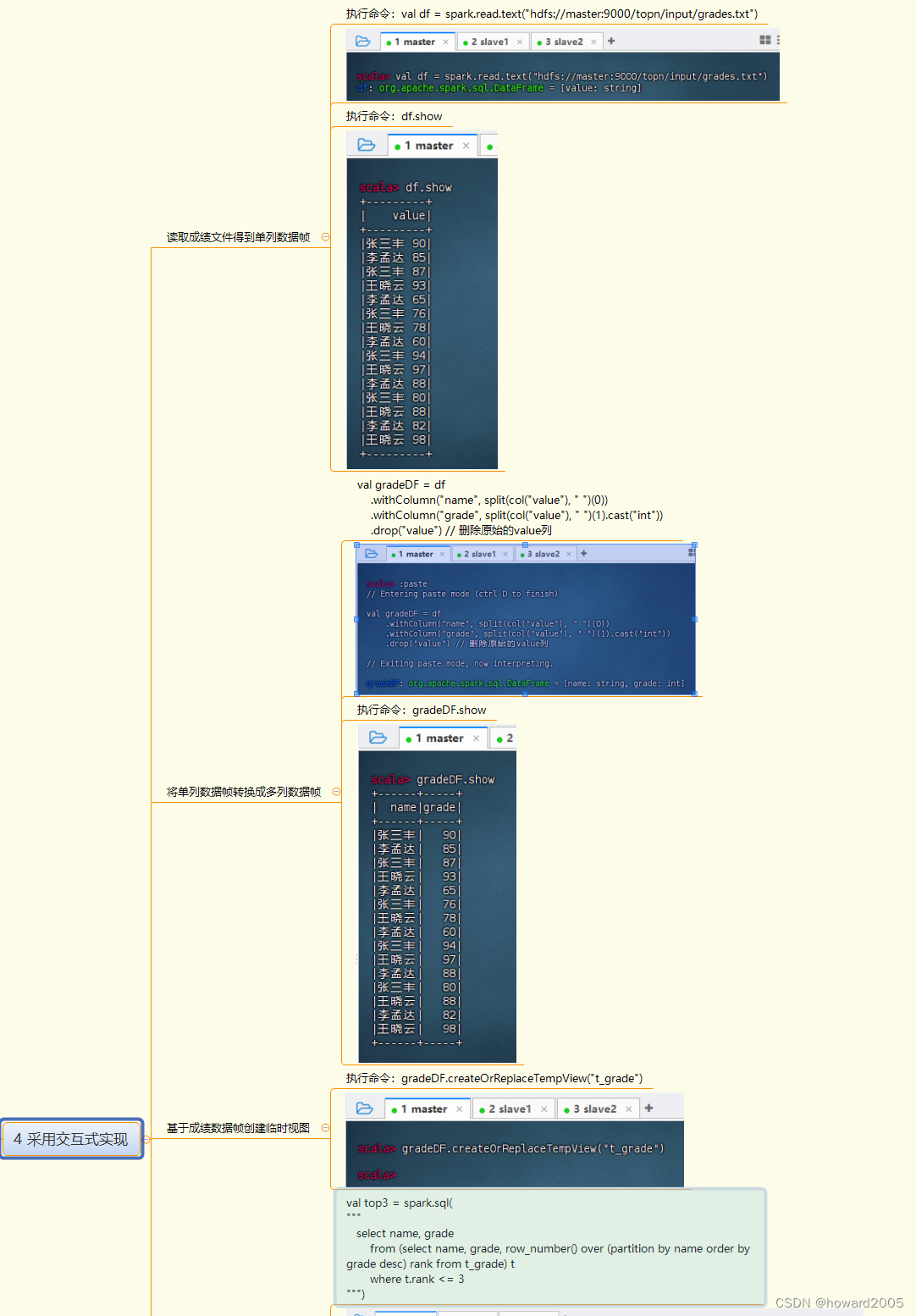
4. 采用交互式实现
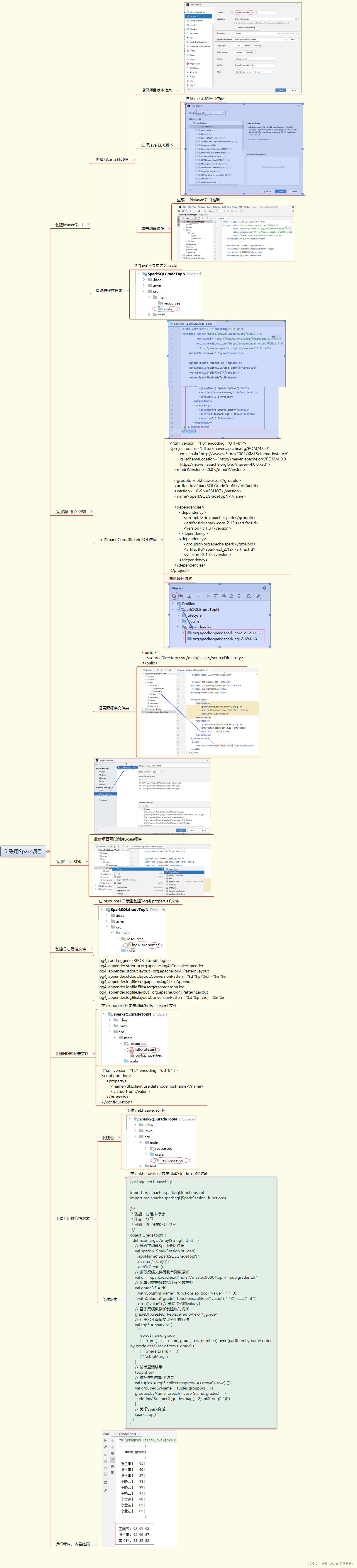
5. 采用Spark项目
实战概述:使用Spark SQL实现分组排行榜
任务背景
在教育数据分析领域,经常需要对学生的成绩进行分组和排名。本实战任务通过Apache Spark的Spark SQL模块,实现对学生成绩数据的分组,并求出每个学生分数最高的前3个成绩。
任务目标
- 处理包含多个学生多条成绩记录的数据集。
- 对每个学生的成绩进行分组,并计算每个学生最高的前3个成绩。
- 以指定的格式输出每个学生的Top3成绩。
技术选型
- 使用Apache Spark作为大数据处理框架。
- 利用Spark SQL进行数据查询和操作。
实现步骤
1. 准备数据
- 创建本地文件
grades.txt,存储学生姓名和对应的成绩。
2. 数据上传至HDFS
- 创建HDFS目录
/topn/input。 - 将
grades.txt上传至HDFS。
3. 启动Spark Shell或创建Spark项目
- 启动Spark Shell或创建Maven项目并配置Spark相关依赖。
4. 读取数据
- 使用Spark读取HDFS上的成绩文件,创建DataFrame。
5. 数据转换
- 将单列DataFrame转换成包含
name和grade的多列DataFrame。
6. 创建临时视图
- 基于DataFrame创建SQL临时视图,以便进行SQL查询。
7. SQL查询实现分组排行榜
- 使用窗口函数
row_number()和over()对每个学生的成绩进行降序排名,并筛选出排名前3的成绩。
8. 结果格式化输出
- 将查询结果转换为元组,然后按学生姓名分组,格式化输出每个学生的Top3成绩。
9. 运行程序并验证结果
- 执行Scala程序,查看输出的Top3成绩是否符合预期。
代码实现
以下是使用Scala编写的Spark程序示例,用于实现分组排行榜功能:
package net.huawei.sql import org.apache.spark.sql.{SparkSession, functions} object GradeTopN { def main(args: Array[String]): Unit = { val spark = SparkSession.builder() .appName("SparkSQLGradeTopN") .master("local[*]") .getOrCreate() val df = spark.read.text("hdfs://master:9000/topn/input/grades.txt") val gradeDF = df.selectExpr("split(value, ' ') as (name, grade)") .withColumn("grade", functions.expr("cast(grade as int)")) .drop("value") gradeDF.createOrReplaceTempView("t_grade") val top3 = spark.sql( """ SELECT name, grade FROM ( SELECT name, grade, ROW_NUMBER() OVER (PARTITION BY name ORDER BY grade DESC) as rank FROM t_grade ) t WHERE t.rank <= 3 """) top3.show() val result = top3.collect.map(row => (row.getString(0), row.getInt(1))) val grouped = result.groupBy(_._1) grouped.foreach { case (name, grades) => println(s"$name: ${grades.map(_._2).mkString(" ")}") } spark.stop() } }

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
结果展示
程序运行后,将输出每个学生的Top3成绩
张三丰: 94 90 87
李孟达: 88 85 82
王晓云: 98 97 93
- 1
- 2
- 3
总结
本实战任务展示了如何使用Spark SQL对数据进行分组和TopN计算,这是大数据领域中常见的数据处理需求。通过Spark SQL的窗口函数,可以方便地实现复杂的数据分析任务。
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/繁依Fanyi0/article/detail/749769
推荐阅读
相关标签

