
热门标签
热门文章
- 1【Leetcode刷题记录_C++】【数据结构】_给定一个字符串,里面包含n个数,其中前n-1个数是数组序列,第n个数是需要赢的次数。
- 2AI导师、AI提示工程师 # Earth实现任意角色设定
- 3解决:ModuleNotFoundError: No module named ‘tiktoken’_modulenotfounderror: no module named 'tiktoken
- 4MATLAB优化函数fmincon解析_fmincon函数原理
- 5基于Python+Neo4j+民航数据 ,我搭建了一个知识图谱的自动问答系统_python智能问答系统开发结合知识图谱
- 6Multi Self-Attention(多头自注意力机制)
- 7Vue中的Props,详细解析
- 8人工智能实验三:分类算法实验_人工智能导论分类算法实验
- 9阿里云服务器ECS常见应用 - 重装系统、快照备份回滚还原、升级降级配置_降低ecs运维事件影响推荐配置快照
- 10什么是元服务
当前位置: article > 正文
逻辑回归-二分类问题_excel的logist二分类回归
作者:繁依Fanyi0 | 2024-03-29 04:03:50
赞
踩
excel的logist二分类回归
目录
1.原理
1.1输入

1.2激活函数(sigmoid函数 )
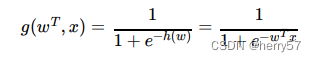
判断标准
回归的结果输⼊到sigmoid函数当中
输出结果:[0, 1]区间中的⼀个概率值,默认为0.5为阈值,其图像如下
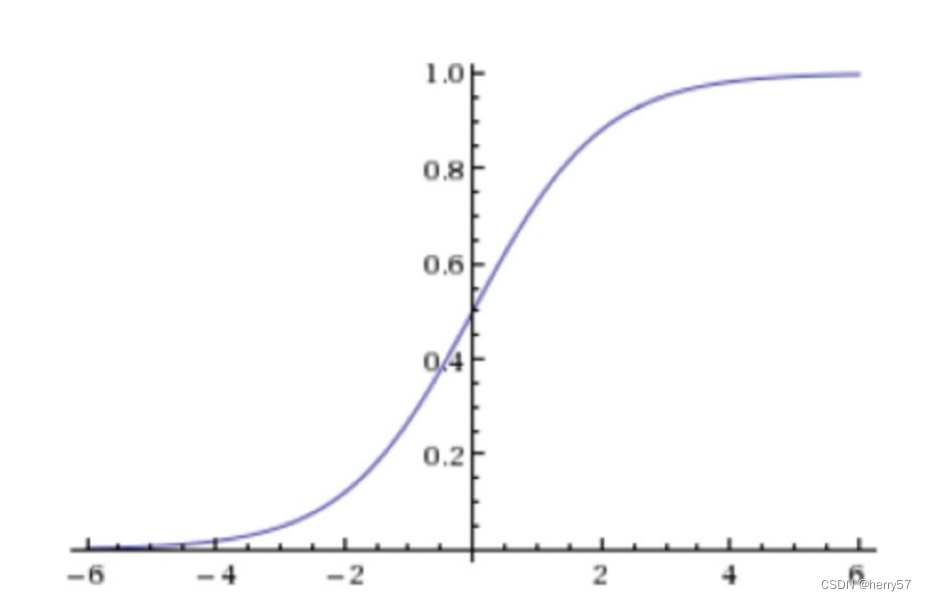
逻辑回归最终的分类是通过属于某个类别的概率值来判断是否属于某个类别,并且这个类别默认标记为1(正例), 另外的⼀个类别会标记为0(反例)
2.损失
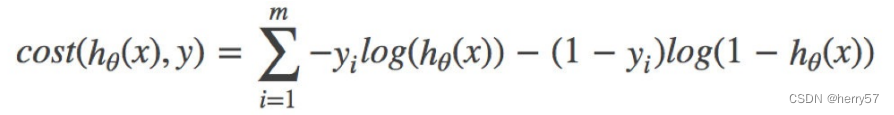
当y=1时,我们希望h (x)值越⼤越好
当y=0时,我们希望h (x)值越⼩越好

-log(P), P值越⼤,结果越⼩
优化:提升原本属于1类别的概率,降低原本是0类别的概率。
对于⼩数据集来说,“liblinear”是个不错的选择,⽽“sag”和'saga'对于⼤型数据集会更快。
3.案例
- import pandas as pd
- import numpy as np
- from sklearn.model_selection import train_test_split
- from sklearn.preprocessing import StandardScaler
- from sklearn.linear_model import LogisticRegression
- from sklearn.metrics import classification_report,roc_auc_score
-
- # 1.获取数据
- names = ['Sample code number', 'Clump Thickness', 'Uniformity of Cell Size', 'Uniformity of Cell Shape',
- 'Marginal Adhesion', 'Single Epithelial Cell Size', 'Bare Nuclei', 'Bland Chromatin',
- 'Normal Nucleoli', 'Mitoses', 'Class']
- data=pd.read_csv("D:/迅雷下载/demo/machineLearnCode/LogisticRegressionTest//breast-cancer-wisconsin.data",names=names)
- # 2.基本数据处理
- # 2.1 缺失值处理
- data=data.replace(to_replace="?",value=np.nan) #把问号替换为nan
- data=data.dropna()
- # 2.2 确定特征值,⽬标值
- x=data.iloc[:,1:-1]
- y=data["Class"]
- # 2.3 分割数据
- x_train,x_test,y_train,y_test=train_test_split(x,y,random_state=22,test_size=0.2)
- # 3.特征⼯程(标准化)
- transfer=StandardScaler()
- x_train=transfer.fit_transform(x_train)
- x_test=transfer.transform(x_test)
- # 4.机器学习(逻辑回归)
- estimator=LogisticRegression()
- estimator.fit(x_train,y_train)
- # 5.模型评估
- y_predict=estimator.predict(x_test) #准确率
- print(y_predict)
- print(estimator.score(x_test,y_test))
- # 5.1精确率和召回率
- ret=classification_report(y_test,y_predict,labels=(2,4),target_names=("良性","恶性"))
- print(ret)
- # 5.2auc指标计算
- y_test=np.where(y_test>3,1,0)
- print(roc_auc_score(y_test,y_predict))

声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/繁依Fanyi0/article/detail/333634
推荐阅读
相关标签

