
- 1apt-get update报错解决方法
- 2DeprecationWarning_langchaindeprecationwarning
- 3vue2低代码平台搭建(二)揭秘页面设计器_vue 页面设计器
- 4《云计算实践与原理》考试内容及参考答案_云计算原理与实践课后答案
- 5Java之SpringMVC框架_java springmvc架构
- 6kali 搭建vulhub docker-compose报错_kali安装compose失败
- 7Unity | Shader基础知识(第十九集:顶点着色器的进一步理解-易错点讲解)_unity plane网格
- 8软件开发解惑系列之五:内向性格不爱说话的同学,没有合适的工作方法是不行的_外向的人适合做开发吗
- 9python--基础知识点--heapq_python heappush
- 10java语言中的websocket
【AIGC】Mac Intel 本地 LLM 部署经验汇总(llama.cpp)_llama。cpp 推理参数 color gpu -n -1 --color -r "user:"
赞
踩
看到标题的各位都知道了。是的,终于也轮到 llama.cpp 了。先说结论,本次 llama.cpp 部署已能在 Intel 核心的 MBP 中使用 Metal GPUs 进行推理。
但出于各种原因最后我还是选择了 CPU 推理。
在进入正文前,还是要回应一下之前提到的 Ollama 不能使用 Metal GPUs 推理的问题。从结论来看,若需要使用 Metal GPUs 推理,则需要从 Github 下载源码后本地编译才可以使用(编译时需要添加 CMAKE Metal 参数)。此外,Docker 版的 Ollama 不能使用 Metal 进行加速,因为 Docker 只支持 CUDA 。
1. llama-cpp-python 实现
由于 llama-cpp-python 是 llama.cpp 的 python 实现,因此还是有必要进行说明的。
MacOS Install with Metal GPU - llama-cpp-python
在重看了 llama-cpp-python cookbook 后发现两个关键点:
- 关于 xcode 的安装路径
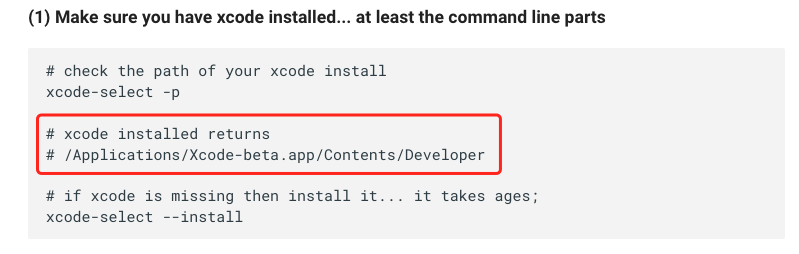
如 cookbook 所示,一定要指向这个路径,不然编译时虽然能够编译通过,但是无法达到目标效果。要怎样切换呢?只需要通过 “–switch” 参数切换即可,如下图:
# 将xcode路径进行切换
sudo xcode-select --switch /Applications/Xcode.app/Contents/Developer
- 1
- 2
- 模型要选 gguf v2 版本的 4 位量化模型

如 cookbook 所示,模型要选 4 位量化的 gguf 模型。文档中提到 TheBloke 量化模型就是一个不错的选择,如下图:
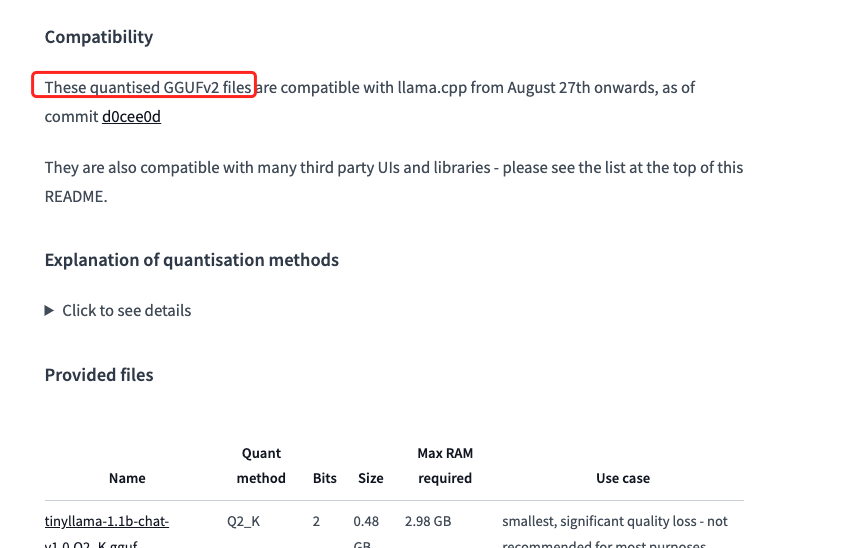
上图来自“TheBloke/TinyLlama-1.1B-Chat-v1.0-GGUF”的 model card 内容,可以看出 TheBloke 的 gguf 模型基本上都是 gguf v2 模型。大伙儿不用自己做量化直接下载使用即可,如下图:
(base) yuanzhenhui@MacBook-Pro hub % huggingface-cli download --resume-download TheBloke/TinyLlama-1.1B-Chat-v1.0-GGUF tinyllama-1.1b-chat-v1.0.Q4_0.gguf --local-dir-use-symlinks False
Consider using `hf_transfer` for faster downloads. This solution comes with some limitations. See https://huggingface.co/docs/huggingface_hub/hf_transfer for more details.
downloading https://hf-mirror.com/TheBloke/TinyLlama-1.1B-Chat-v1.0-GGUF/resolve/main/tinyllama-1.1b-chat-v1.0.Q4_0.gguf to /Users/yuanzhenhui/.cache/huggingface/hub/models--TheBloke--TinyLlama-1.1B-Chat-v1.0-GGUF/blobs/da3087fb14aede55fde6eb81a0e55e886810e43509ec82ecdc7aa5d62a03b556.incomplete
tinyllama-1.1b-chat-v1.0.Q4_0.gguf: 100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 638M/638M [05:56<00:00, 1.79MB/s]
/Users/yuanzhenhui/.cache/huggingface/hub/models--TheBloke--TinyLlama-1.1B-Chat-v1.0-GGUF/snapshots/52e7645ba7c309695bec7ac98f4f005b139cf465/tinyllama-1.1b-chat-v1.0.Q4_0.gguf
- 1
- 2
- 3
- 4
- 5
好了,做完上面的关键点处理后我们开始创建一个新的 python 环境进行验证,如下图:
(base) yuanzhenhui@MacBook-Pro llama.cpp % conda create -n llm python=3.11.7 Channels: - defaults - conda-forge Platform: osx-64 Collecting package metadata (repodata.json): done Solving environment: done ==> WARNING: A newer version of conda exists. <== current version: 24.3.0 latest version: 24.5.0 Please update conda by running $ conda update -n base -c conda-forge conda ... Downloading and Extracting Packages: Preparing transaction: done Verifying transaction: done Executing transaction: done # # To activate this environment, use # # $ conda activate llm # # To deactivate an active environment, use # # $ conda deactivate (base) yuanzhenhui@MacBook-Pro llama.cpp % conda activate llm (llm) yuanzhenhui@MacBook-Pro llama.cpp %

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
由于上一篇文章中已经安装了 Miniforge3 这里就无需再安装了。
接下来使用 conda create 创建环境时会自动在“/Users/yuanzhenhui/miniforge3/envs/”路径下创建一个新的环境,如果没有安装 Miniforge3 请翻看上一篇文章按照指引先进行安装。
之后就可以安装 llama-cpp-python 了,如下图:
(llm) yuanzhenhui@MacBook-Pro ~ % pip uninstall llama-cpp-python WARNING: Skipping llama-cpp-python as it is not installed. (llm) yuanzhenhui@MacBook-Pro ~ % CMAKE_ARGS="-DLLAMA_METAL=on" pip install -U llama-cpp-python==0.2.27 --no-cache-dir Collecting llama-cpp-python==0.2.27 Using cached llama_cpp_python-0.2.27-cp311-cp311-macosx_10_16_x86_64.whl Collecting typing-extensions>=4.5.0 (from llama-cpp-python==0.2.27) Downloading typing_extensions-4.11.0-py3-none-any.whl.metadata (3.0 kB) Collecting numpy>=1.20.0 (from llama-cpp-python==0.2.27) Downloading numpy-1.26.4-cp311-cp311-macosx_10_9_x86_64.whl.metadata (61 kB) ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 61.1/61.1 kB 239.8 kB/s eta 0:00:00 Collecting diskcache>=5.6.1 (from llama-cpp-python==0.2.27) Downloading diskcache-5.6.3-py3-none-any.whl.metadata (20 kB) Downloading diskcache-5.6.3-py3-none-any.whl (45 kB) ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 45.5/45.5 kB 726.9 kB/s eta 0:00:00 Downloading numpy-1.26.4-cp311-cp311-macosx_10_9_x86_64.whl (20.6 MB) ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 20.6/20.6 MB 95.5 kB/s eta 0:00:00 Downloading typing_extensions-4.11.0-py3-none-any.whl (34 kB) Installing collected packages: typing-extensions, numpy, diskcache, llama-cpp-python Successfully installed diskcache-5.6.3 llama-cpp-python-0.2.27 numpy-1.26.4 typing-extensions-4.11.0 (llm) yuanzhenhui@MacBook-Pro ~ % pip install 'llama-cpp-python[server]' Requirement already satisfied: llama-cpp-python[server] in /Users/yuanzhenhui/miniforge3/envs/llm/lib/python3.11/site-packages (0.2.27) ... Installing collected packages: websockets, uvloop, ujson, sniffio, shellingham, pyyaml, python-multipart, python-dotenv, pygments, pydantic-core, orjson, mdurl, MarkupSafe, idna, httptools, h11, dnspython, click, certifi, annotated-types, uvicorn, pydantic, markdown-it-py, jinja2, httpcore, email_validator, anyio, watchfiles, starlette, rich, pydantic-settings, httpx, typer, starlette-context, sse-starlette, fastapi-cli, fastapi Successfully installed MarkupSafe-2.1.5 annotated-types-0.6.0 anyio-4.3.0 certifi-2024.2.2 click-8.1.7 dnspython-2.6.1 email_validator-2.1.1 fastapi-0.111.0 fastapi-cli-0.0.3 h11-0.14.0 httpcore-1.0.5 httptools-0.6.1 httpx-0.27.0 idna-3.7 jinja2-3.1.4 markdown-it-py-3.0.0 mdurl-0.1.2 orjson-3.10.3 pydantic-2.7.1 pydantic-core-2.18.2 pydantic-settings-2.2.1 pygments-2.18.0 python-dotenv-1.0.1 python-multipart-0.0.9 pyyaml-6.0.1 rich-13.7.1 shellingham-1.5.4 sniffio-1.3.1 sse-starlette-2.1.0 starlette-0.37.2 starlette-context-0.3.6 typer-0.12.3 ujson-5.10.0 uvicorn-0.29.0 uvloop-0.19.0 watchfiles-0.21.0 websockets-12.0
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
关于 llama-cpp-python 的安装必须关注的点有 3 个:
- 必须加上 “-DLLAMA_METAL=on” 参数确保 llama-cpp-python 是可用于 Metal 加速;
- llama-cpp-python==0.2.27是必须加上的,因为最新版本无法使用 GPU 加速(估计是针对 M 系列做了调整);
- llama-cpp-python[server] 必须装,不然无法直接通过 API 调用;
都准备就绪后就可以运行 tinyllama 模型了,但启动的时候你或许会遇到以下的错误:
ggml_metal_init: allocating
ggml_metal_init: found device: Intel(R) Iris(TM) Plus Graphics
ggml_metal_init: picking default device: Intel(R) Iris(TM) Plus Graphics
ggml_metal_init: ggml.metallib not found, loading from source
ggml_metal_init: GGML_METAL_PATH_RESOURCES = nil
ggml_metal_init: loading '/Users/yuanzhenhui/miniforge3/envs/llm/lib/python3.11/site-packages/llama_cpp/ggml-metal.metal'
ggml_metal_init: error: Error Domain=MTLLibraryErrorDomain Code=3 "program_source:58:9: error: invalid type 'const constant int64_t &' (aka 'const constant long &') for buffer declaration
constant int64_t & ne00,
^~~~~~~~~~~~~~~~~~~~~~~~
program_source:58:19: note: type 'int64_t' (aka 'long') cannot be used in buffer pointee type
constant int64_t & ne00,
^
program_source:59:9: error: invalid type 'const constant int64_t &' (aka 'const constant long &') for buffer declaration
constant int64_t & ne01,
...
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
嗯…这种情况只需要将 llama-cpp-python “先删除后安装”多安装几次就好(我也无解)。
(llm) yuanzhenhui@MacBook-Pro ~ % pip uninstall llama-cpp-python
Found existing installation: llama_cpp_python 0.2.27
Uninstalling llama_cpp_python-0.2.27:
Would remove:
...
Successfully uninstalled llama_cpp_python-0.2.27
(llm) yuanzhenhui@MacBook-Pro ~ % pip cache purge
Files removed: 307
(llm) yuanzhenhui@MacBook-Pro ~ % CMAKE_ARGS="-DLLAMA_METAL=on" FORCE_CMAKE=1 pip install -U llama-cpp-python==0.2.27 --no-cache-dir
(llm) yuanzhenhui@MacBook-Pro ~ % pip install 'llama-cpp-python[server]'
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
虽然 tinyllama 能够正常运行起来,但可惜的是它不支持中文输出。出于对中文输出的需要找了一个名为“llama-2-7b-langchain-chat.Q4_0.gguf”的模型,执行效果如下:
(llm) yuanzhenhui@MacBook-Pro Downloads % python3 -m llama_cpp.server --model /Users/yuanzhenhui/Downloads/llama-2-7b-langchain-chat.Q4_0.gguf --n_gpu_layers 16 --n_ctx 512 --n_threads 4 --cache true --chat_format chatml llama_model_loader: loaded meta data with 19 key-value pairs and 291 tensors from /Users/yuanzhenhui/Downloads/llama-2-7b-langchain-chat.Q4_0.gguf (version GGUF V2) llama_model_loader: Dumping metadata keys/values. Note: KV overrides do not apply in this output. llama_model_loader: - kv 0: general.architecture str = llama ... llama_model_loader: - type f32: 65 tensors llama_model_loader: - type q4_0: 225 tensors llama_model_loader: - type q6_K: 1 tensors llm_load_vocab: special tokens definition check successful ( 259/32000 ). llm_load_print_meta: format = GGUF V2 llm_load_print_meta: arch = llama ... llm_load_print_meta: model type = 7B llm_load_print_meta: model ftype = Q4_0 llm_load_print_meta: model params = 6.74 B llm_load_print_meta: model size = 3.56 GiB (4.54 BPW) llm_load_print_meta: general.name = LLaMA v2 llm_load_print_meta: BOS token = 1 '<s>' llm_load_print_meta: EOS token = 2 '</s>' llm_load_print_meta: UNK token = 0 '<unk>' llm_load_print_meta: LF token = 13 '<0x0A>' llm_load_tensors: ggml ctx size = 0.11 MiB ggml_backend_metal_buffer_from_ptr: allocated buffer, size = 2048.00 MiB, offs = 0 ggml_backend_metal_buffer_from_ptr: allocated buffer, size = 1703.12 MiB, offs = 2039959552, ( 3755.41 / 1536.00)ggml_backend_metal_buffer_from_ptr: warning: current allocated size is greater than the recommended max working set size llm_load_tensors: system memory used = 3647.98 MiB .................................................................................................. llama_new_context_with_model: n_ctx = 512 llama_new_context_with_model: freq_base = 10000.0 llama_new_context_with_model: freq_scale = 1 ggml_metal_init: allocating ggml_metal_init: found device: Intel(R) Iris(TM) Plus Graphics ggml_metal_init: picking default device: Intel(R) Iris(TM) Plus Graphics ggml_metal_init: ggml.metallib not found, loading from source ggml_metal_init: GGML_METAL_PATH_RESOURCES = nil ggml_metal_init: loading '/Users/yuanzhenhui/miniforge3/envs/llm/lib/python3.11/site-packages/llama_cpp/ggml-metal.metal' ggml_metal_init: GPU name: Intel(R) Iris(TM) Plus Graphics ggml_metal_init: hasUnifiedMemory = true ggml_metal_init: recommendedMaxWorkingSetSize = 1610.61 MB ggml_metal_init: maxTransferRate = built-in GPU ggml_backend_metal_buffer_type_alloc_buffer: allocated buffer, size = 256.00 MiB, ( 4018.91 / 1536.00)ggml_backend_metal_buffer_type_alloc_buffer: warning: current allocated size is greater than the recommended max working set size llama_new_context_with_model: KV self size = 256.00 MiB, K (f16): 128.00 MiB, V (f16): 128.00 MiB ggml_backend_metal_buffer_type_alloc_buffer: allocated buffer, size = 0.00 MiB, ( 4018.92 / 1536.00)ggml_backend_metal_buffer_type_alloc_buffer: warning: current allocated size is greater than the recommended max working set size llama_build_graph: non-view tensors processed: 676/676 llama_new_context_with_model: compute buffer total size = 73.69 MiB ggml_backend_metal_buffer_type_alloc_buffer: allocated buffer, size = 70.50 MiB, ( 4089.41 / 1536.00)ggml_backend_metal_buffer_type_alloc_buffer: warning: current allocated size is greater than the recommended max working set size AVX = 1 | AVX_VNNI = 0 | AVX2 = 1 | AVX512 = 1 | AVX512_VBMI = 1 | AVX512_VNNI = 1 | FMA = 1 | NEON = 0 | ARM_FMA = 0 | F16C = 1 | FP16_VA = 0 | WASM_SIMD = 0 | BLAS = 1 | SSE3 = 1 | SSSE3 = 1 | VSX = 0 | Using ram cache with size 2147483648 INFO: Started server process [61420] INFO: Waiting for application startup. INFO: Application startup complete. INFO: Uvicorn running on http://localhost:8000 (Press CTRL+C to quit) Llama._create_completion: cache miss llama_print_timings: load time = 16405.52 ms llama_print_timings: sample time = 88.29 ms / 423 runs ( 0.21 ms per token, 4791.08 tokens per second) llama_print_timings: prompt eval time = 0.00 ms / 1 tokens ( 0.00 ms per token, inf tokens per second) llama_print_timings: eval time = 88859.66 ms / 423 runs ( 210.07 ms per token, 4.76 tokens per second) llama_print_timings: total time = 92104.09 ms Llama._create_completion: cache save Llama.save_state: saving llama state Llama.save_state: got state size: 334053420 Llama.save_state: allocated state ggml_backend_metal_buffer_type_alloc_buffer: allocated buffer, size = 255.50 MiB, ( 4359.41 / 1536.00)ggml_backend_metal_buffer_type_alloc_buffer: warning: current allocated size is greater than the recommended max working set size Llama.save_state: copied llama state: 333537328 Llama.save_state: saving 333537328 bytes of llama state INFO: 127.0.0.1:53543 - "POST /v1/chat/completions HTTP/1.1" 200 OK
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
在使用“–n_gpu_layers”参数时系统提示“模型所需显存大于本机显存”,但这个不影响运行因此可以选择忽视,因为在这种情况下若 GPU 资源不够会先进行“排队等待”,若还是不够则会自动调取 CPU 资源进行推理。此外,由于使用了 cache 参数,因此在第二次问同一个问题的时候就不用重新解析相同的 prompt 了。但有一说一 7b 的模型对于我来说还是太大了,虽然结果出来了,但是性能上不去。两次生成一次 108 秒,另一次 92 秒,而且还是使用了 Metal 推理的情况下…
难道 TheBloke 就没有体积小一点的中文模型吗?
随后到 huggingface 上看了一下 TheBloke 的中文模型,如下图:
逐个点进去查看发现这些模型动不动就几个 G…
声明:本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:【wpsshop博客】
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

