
热门标签
热门文章
- 1配置YOLOv7训练自己是数据集【踩坑记录】_yolov7训练自己的数据集出现的问题
- 2python植物大战僵尸辅助_【python面向对象实战练习】植物大战僵尸
- 3机器学习实战-员工离职预测-分类预测模型(决策树、朴素贝叶斯、支持向量机)_分别利用决策树算法(id3)、朴素贝叶斯算法分类模型预测样本是否会离职?结果有没有
- 4导出 Whisper 模型到 ONNX_whisper onnx
- 5【JAVA毕设|课设】基于SpringBoot+Vue的进销存(库存)管理系统-附下载方式_vue进销存系统csdn下载
- 6OpenCV 车道检测_实现图片车道线检测
- 7大数据毕业设计:微博情感分析可视化系统 舆情分析 爬虫 python 大数据 TF-IDF算法 Flask框架(源码)✅_基于大数据的舆情系统源码
- 8tf-idf关键词提取算法_tf-idf关键字提取
- 9spring boot 1.5.9 整合redis
- 10机器学习 鸢尾花分类的原理和实现(三)_机器学习鸢尾花的研究起源
当前位置: article > 正文
KNN(K最近邻算法)原理及代码实现_knn聚类实现
作者:笔触狂放9 | 2024-06-11 12:15:15
赞
踩
knn聚类实现
机器学习
没有免费午餐定理和三大机器学习任务
如何对模型进行评估
K-Means(K均值聚类)原理及代码实现
KNN(K最近邻算法)原理及代码实现
KMeans和KNN的联合演习
前言
邻近算法,或者说K最邻近(KNN,K-NearestNeighbor)分类算法是数据挖掘分类技术中最简单的方法之一。
该方法的思路非常简单直观:根据其最近的K个样本的分类确定它自身类别的分类算法。
一般来说在计算距离时,可以使用他们之间的直线距离即欧氏距离,或坐标绝对值之和,即曼哈顿距离。
一、K是什么?
所谓K最近邻,就是K个最近的邻居的意思,说的是每个样本都可以用它最接近的K个邻近值来代表。
K的取值非常重要。
K太小:受到个例影响严重,波动较大。
K太大:受到距离较远数据影响,分类模糊。
K的取值受数据集大小影响。一般需要反复尝试,根据经验调整或者使用均方根误差来选取。
二、算法步骤
- 计算新样本和所有样本之间的距离。
- 按照由小到大排序。
- 根据K值选取取前K个样本。
- 加权平均。(计算总距离D以及目标到这个样本的距离d, w e i g h t = 1 − d D weight =1− \frac{d}{D} weight=1−Dd weight是这个样本的权重)
三、缺点
- 数据越多计算量越大,效率越低。
- 难以运用到较大的数据集中。
四、代码实现
- 导入必要的库:
import numpy as np
- 1
- KNN实现:
class KNN(object): def __init__(self, data, targets, k, distance='E'): # 'E' 欧氏距离 # 'M' 曼哈顿距离 self.targets = targets self.data = data # data = [[x1,x2,x3,x4,y]] self.k = k self.result = [] self.maxDistance = [] distance = distance.upper() if distance == 'E' or distance == 'M': self.way = distance else: raise Exception("未定义的距离公式") def __distance(self, target): distances = [] if self.way == 'E': for i in self.data: diff = i[:-1] - target distance = np.sum(np.power(diff, 2)) distances.append((distance, i)) else: for i in self.data: diff = i[:-1] ** 2 ** 0.5 - target ** 2 ** 0.5 distance = np.sum(diff) distances.append((distance, i)) return distances def classify(self): for target in self.targets: distances = self.__distance(target) neighbors = sorted(distances, key=lambda distances: distances[0])[:self.k] total_distance = 0 for distance in neighbors: total_distance += distance[0] weights = {} for item in neighbors: if item[1][-1] not in weights: weights[item[1][-1]] = 1 - (item[0] / total_distance) else: weights[item[1][-1]] += 1 - (item[0] / total_distance) maxValue = 0 res = None for key in weights.keys(): if weights.get(key) > maxValue: res = key maxValue = weights.get(key) self.result.append(res) self.maxDistance.append(neighbors[self.k - 1][0] ** 0.5)

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 绘制分类图(二维情况下):
def plotKNN(classifier): colors = ['r', 'g', 'b', 'c', 'm', 'y', 'k'] figure, axes = plt.figure(), plt.gca() for i in range(len(classifier.data)): x = np.array([classifier.data[i][0]]) y = np.array([classifier.data[i][1]]) plt.plot(x, y, color=colors[int(classifier.data[i][-1])], marker='o', # 点的形状为圆点 ms=7, linestyle='') # 线型为空,也即点与点之间不用线连接 for i in range(len(classifier.targets)): x = np.array([classifier.targets[i][0]]) y = np.array([classifier.targets[i][1]]) plt.plot(x, y, color=colors[int(classifier.result[i])], marker='*', # 点的形状为星形 ms=20, linestyle='') # 线型为空,也即点与点之间不用线连接 circle = plt.Circle((x[0], y[0]), classifier.maxDistance[i], fill=False, color=colors[int(classifier.result[i])]) axes.add_patch(circle) plt.axis('equal') plt.grid(True) plt.title("KNN") plt.show()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 测试及评估:
import random import numpy as np from KNN import KNN import csv if __name__ == '__main__': data = [] classification = {'M': 1, 'B': 0} with open('E:\\ML\\dataset\\prostate-cancer\\Prostate_Cancer.csv', 'r') as f: f_csv = csv.reader(f) header = next(f_csv) for row in f_csv: row.append(classification[row[1]]) del row[1] del row[0] data.append(np.array(row, dtype='float64')) random.shuffle(data) n = len(data) // 3 test_data = data[:n] test_data_labels = [] for i in range(len(test_data)): test_data_labels.append(test_data[i][-1]) test_data[i] = test_data[i][:-1] train_data = data[n:] # 测试 correct = 0 incorrect = 0 classifier = KNN(train_data, test_data, 5, 'E') classifier.classify() result = classifier.result # 62个M,38个B for i in range(len(test_data)): if test_data_labels[i] == result[i]: correct += 1 else: incorrect += 1 print("Correct: " + str(correct)) print("Incorrect: " + str(incorrect)) print("AC Rate: {:.2f}%".format(100 * (correct/(correct + incorrect))))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
五、测试结果
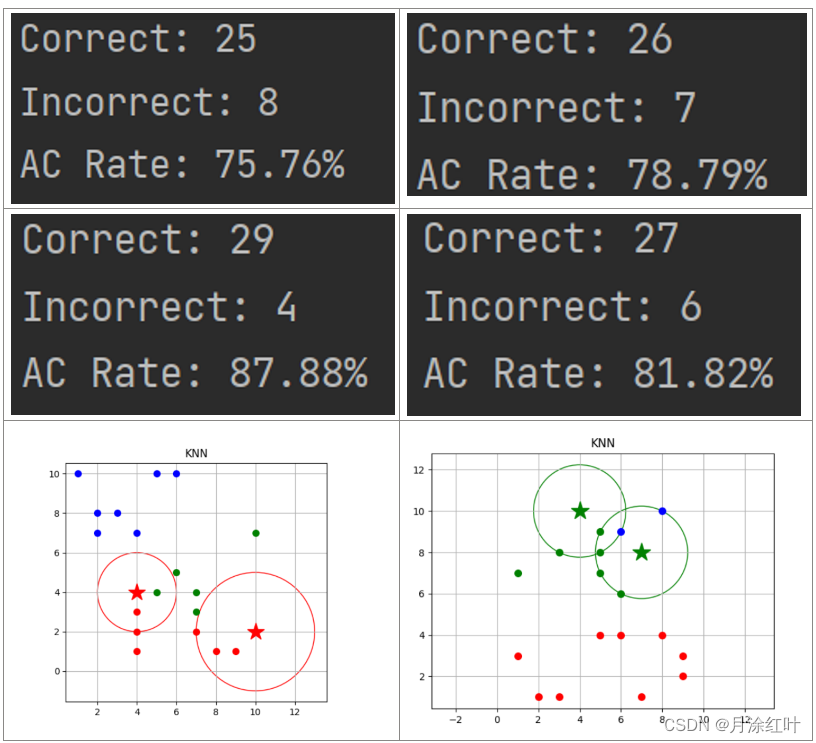
数据集来自https://pan.baidu.com/s/1w8cyvknAazrAYnAXdvtozw提取码:zxmt
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/笔触狂放9/article/detail/703126
推荐阅读


相关标签

